 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastFlow: Accelerating The Generative Flow Matching Models with Bandit Inference
Feb 11, 2026Flow-matching models deliver state-of-the-art fidelity in image and video generation, but the inherent sequential denoising process renders them slower. Existing acceleration methods like distillation, trajectory truncation, and consistency approaches are static, require retraining, and often fail to generalize across tasks. We propose FastFlow, a plug-and-play adaptive inference framework that accelerates generation in flow matching models. FastFlow identifies denoising steps that produce only minor adjustments to the denoising path and approximates them without using the full neural network models used for velocity predictions. The approximation utilizes finite-difference velocity estimates from prior predictions to efficiently extrapolate future states, enabling faster advancements along the denoising path at zero compute cost. This enables skipping computation at intermediary steps. We model the decision of how many steps to safely skip before requiring a full model computation as a multi-armed bandit problem. The bandit learns the optimal skips to balance speed with performance. FastFlow integrates seamlessly with existing pipelines and generalizes across image generation, video generation, and editing tasks. Experiments demonstrate a speedup of over 2.6x while maintaining high-quality outputs. The source code for this work can be found at https://github.com/Div290/FastFlow.
SPACE-SUIT: An Artificial Intelligence based chromospheric feature extractor and classifier for SUIT
Dec 11, 2024The Solar Ultraviolet Imaging Telescope(SUIT) onboard Aditya-L1 is an imager that observes the solar photosphere and chromosphere through observations in the wavelength range of 200-400 nm. A comprehensive understanding of the plasma and thermodynamic properties of chromospheric and photospheric morphological structures requires a large sample statistical study, necessitating the development of automatic feature detection methods. To this end, we develop the feature detection algorithm SPACE-SUIT: Solar Phenomena Analysis and Classification using Enhanced vision techniques for SUIT, to detect and classify the solar chromospheric features to be observed from SUIT's Mg II k filter. Specifically, we target plage regions, sunspots, filaments, and off-limb structures. SPACE uses You Only Look Once(YOLO), a neural network-based model to identify regions of interest. We train and validate SPACE using mock-SUIT images developed from Interface Region Imaging Spectrometer(IRIS) full-disk mosaic images in Mg II k line, while we also perform detection on Level-1 SUIT data. SPACE achieves an approximate precision of 0.788, recall 0.863 and MAP of 0.874 on the validation mock SUIT FITS dataset. Given the manual labeling of our dataset, we perform "self-validation" by applying statistical measures and Tamura features on the ground truth and predicted bounding boxes. We find the distributions of entropy, contrast, dissimilarity, and energy to show differences in the features. These differences are qualitatively captured by the detected regions predicted by SPACE and validated with the observed SUIT images, even in the absence of labeled ground truth. This work not only develops a chromospheric feature extractor but also demonstrates the effectiveness of statistical metrics and Tamura features for distinguishing chromospheric features, offering independent validation for future detection schemes.
Analyzing Consumer Reviews for Understanding Drivers of Hotels Ratings: An Indian Perspective
Aug 08, 2024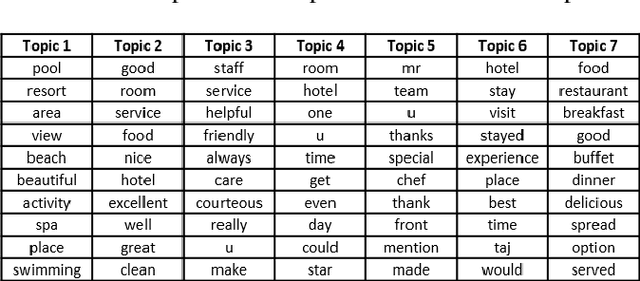
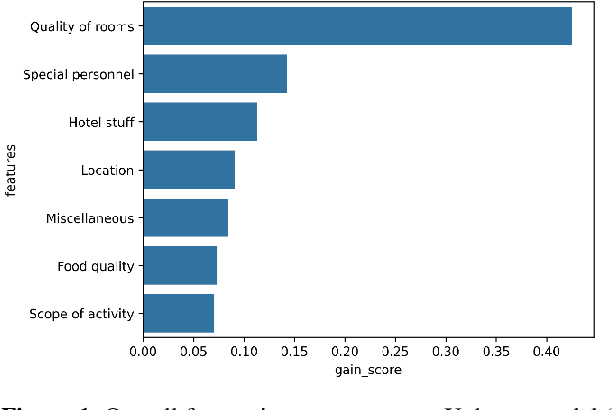
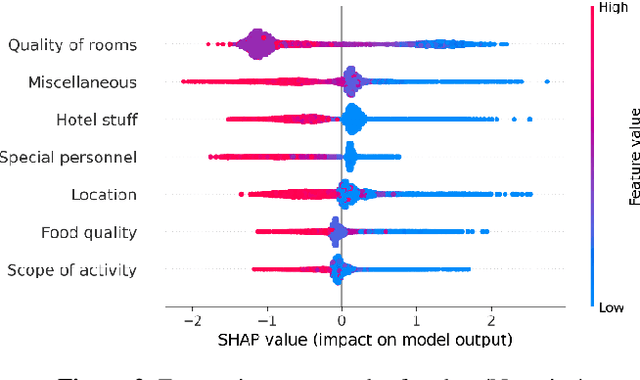
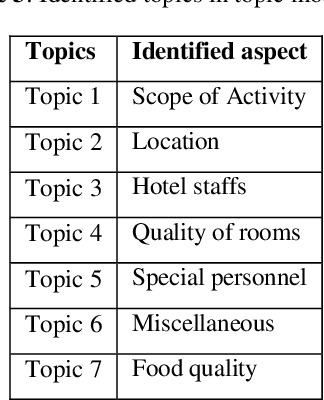
In the internet era, almost every business entity is trying to have its digital footprint in digital media and other social media platforms. For these entities, word of mouse is also very important. Particularly, this is quite crucial for the hospitality sector dealing with hotels, restaurants etc. Consumers do read other consumers reviews before making final decisions. This is where it becomes very important to understand which aspects are affecting most in the minds of the consumers while giving their ratings. The current study focuses on the consumer reviews of Indian hotels to extract aspects important for final ratings. The study involves gathering data using web scraping methods, analyzing the texts using Latent Dirichlet Allocation for topic extraction and sentiment analysis for aspect-specific sentiment mapping. Finally, it incorporates Random Forest to understand the importance of the aspects in predicting the final rating of a user.
Efficient Expansion and Gradient Based Task Inference for Replay Free Incremental Learning
Dec 02, 2023This paper proposes a simple but highly efficient expansion-based model for continual learning. The recent feature transformation, masking and factorization-based methods are efficient, but they grow the model only over the global or shared parameter. Therefore, these approaches do not fully utilize the previously learned information because the same task-specific parameter forgets the earlier knowledge. Thus, these approaches show limited transfer learning ability. Moreover, most of these models have constant parameter growth for all tasks, irrespective of the task complexity. Our work proposes a simple filter and channel expansion based method that grows the model over the previous task parameters and not just over the global parameter. Therefore, it fully utilizes all the previously learned information without forgetting, which results in better knowledge transfer. The growth rate in our proposed model is a function of task complexity; therefore for a simple task, the model has a smaller parameter growth while for complex tasks, the model requires more parameters to adapt to the current task. Recent expansion based models show promising results for task incremental learning (TIL). However, for class incremental learning (CIL), prediction of task id is a crucial challenge; hence, their results degrade rapidly as the number of tasks increase. In this work, we propose a robust task prediction method that leverages entropy weighted data augmentations and the models gradient using pseudo labels. We evaluate our model on various datasets and architectures in the TIL, CIL and generative continual learning settings. The proposed approach shows state-of-the-art results in all these settings. Our extensive ablation studies show the efficacy of the proposed components.
Active learning with version spaces for object detection
Nov 29, 2016
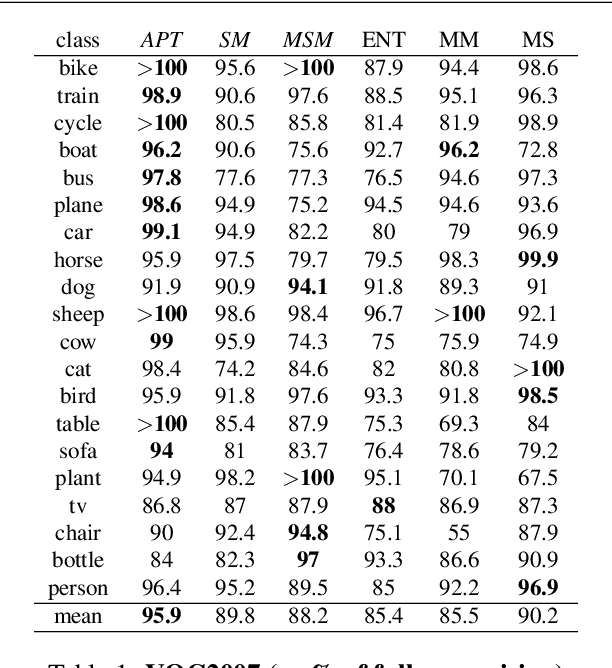

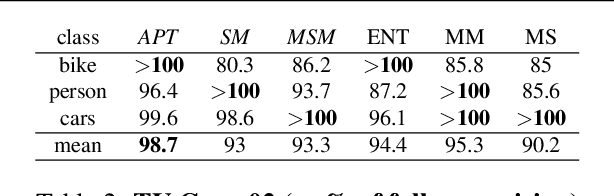
Given an image, we would like to learn to detect objects belonging to particular object categories. Common object detection methods train on large annotated datasets which are annotated in terms of bounding boxes that contain the object of interest. Previous works on object detection model the problem as a structured regression problem which ranks the correct bounding boxes more than the background ones. In this paper we develop algorithms which actively obtain annotations from human annotators for a small set of images, instead of all images, thereby reducing the annotation effort. Towards this goal, we make the following contributions: 1. We develop a principled version space based active learning method that solves for object detection as a structured prediction problem in a weakly supervised setting 2. We also propose two variants of the margin sampling strategy 3. We analyse the results on standard object detection benchmarks that show that with only 20% of the data we can obtain more than 95% of the localization accuracy of full supervision. Our methods outperform random sampling and the classical uncertainty-based active learning algorithms like entropy