 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePart-of-Speech Tagger for Bodo Language using Deep Learning approach
Jan 06, 2024Language Processing systems such as Part-of-speech tagging, Named entity recognition, Machine translation, Speech recognition, and Language modeling (LM) are well-studied in high-resource languages. Nevertheless, research on these systems for several low-resource languages, including Bodo, Mizo, Nagamese, and others, is either yet to commence or is in its nascent stages. Language model plays a vital role in the downstream tasks of modern NLP. Extensive studies are carried out on LMs for high-resource languages. Nevertheless, languages such as Bodo, Rabha, and Mising continue to lack coverage. In this study, we first present BodoBERT, a language model for the Bodo language. To the best of our knowledge, this work is the first such effort to develop a language model for Bodo. Secondly, we present an ensemble DL-based POS tagging model for Bodo. The POS tagging model is based on combinations of BiLSTM with CRF and stacked embedding of BodoBERT with BytePairEmbeddings. We cover several language models in the experiment to see how well they work in POS tagging tasks. The best-performing model achieves an F1 score of 0.8041. A comparative experiment was also conducted on Assamese POS taggers, considering that the language is spoken in the same region as Bodo.
AsPOS: Assamese Part of Speech Tagger using Deep Learning Approach
Dec 14, 2022Part of Speech (POS) tagging is crucial to Natural Language Processing (NLP). It is a well-studied topic in several resource-rich languages. However, the development of computational linguistic resources is still in its infancy despite the existence of numerous languages that are historically and literary rich. Assamese, an Indian scheduled language, spoken by more than 25 million people, falls under this category. In this paper, we present a Deep Learning (DL)-based POS tagger for Assamese. The development process is divided into two stages. In the first phase, several pre-trained word embeddings are employed to train several tagging models. This allows us to evaluate the performance of the word embeddings in the POS tagging task. The top-performing model from the first phase is employed to annotate another set of new sentences. In the second phase, the model is trained further using the fresh dataset. Finally, we attain a tagging accuracy of 86.52% in F1 score. The model may serve as a baseline for further study on DL-based Assamese POS tagging.
AsNER -- Annotated Dataset and Baseline for Assamese Named Entity recognition
Jul 07, 2022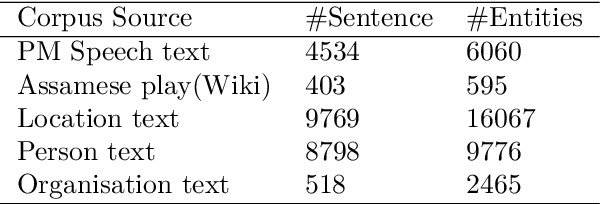
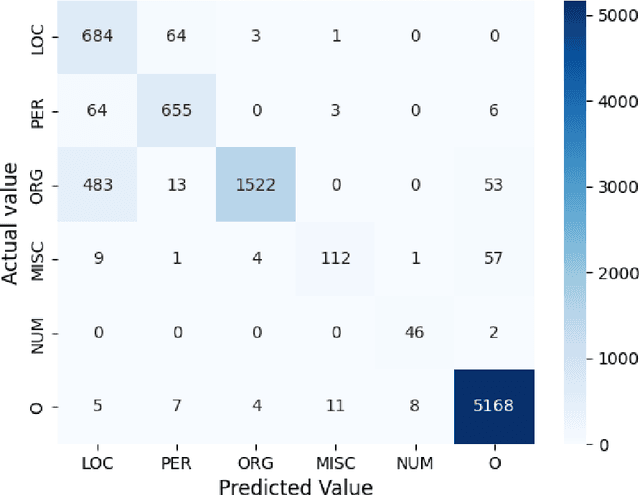
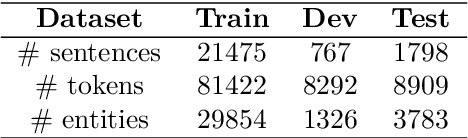
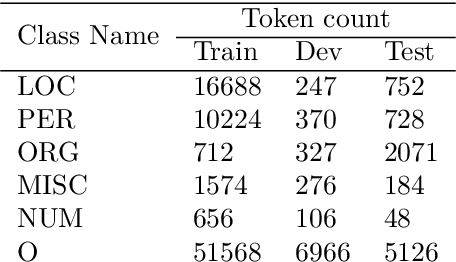
We present the AsNER, a named entity annotation dataset for low resource Assamese language with a baseline Assamese NER model. The dataset contains about 99k tokens comprised of text from the speech of the Prime Minister of India and Assamese play. It also contains person names, location names and addresses. The proposed NER dataset is likely to be a significant resource for deep neural based Assamese language processing. We benchmark the dataset by training NER models and evaluating using state-of-the-art architectures for supervised named entity recognition (NER) such as Fasttext, BERT, XLM-R, FLAIR, MuRIL etc. We implement several baseline approaches with state-of-the-art sequence tagging Bi-LSTM-CRF architecture. The highest F1-score among all baselines achieves an accuracy of 80.69% when using MuRIL as a word embedding method. The annotated dataset and the top performing model are made publicly available.
* Published at LREC 2022