 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporally Precise Action Spotting in Soccer Videos Using Dense Detection Anchors
Paper and Code
May 20, 2022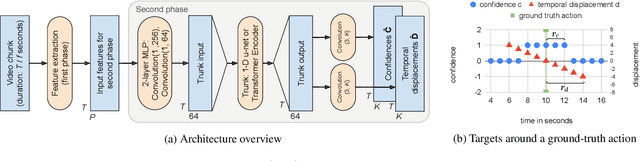
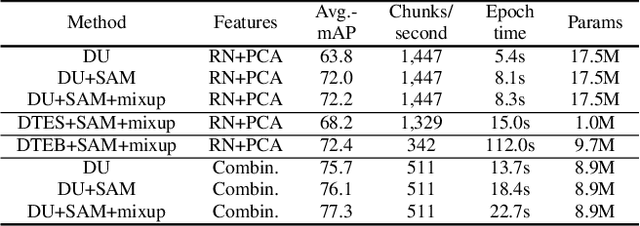
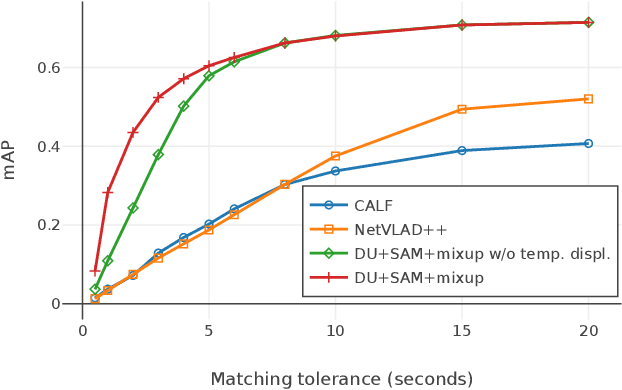
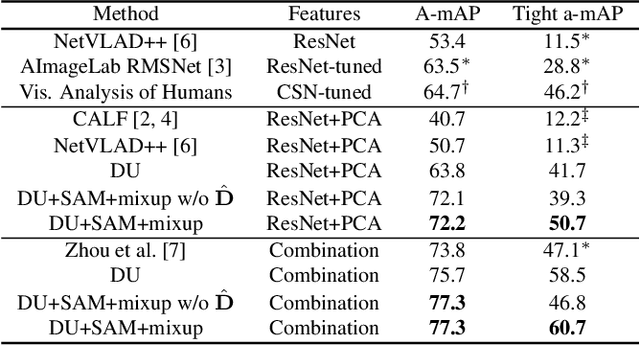
We present a model for temporally precise action spotting in videos, which uses a dense set of detection anchors, predicting a detection confidence and corresponding fine-grained temporal displacement for each anchor. We experiment with two trunk architectures, both of which are able to incorporate large temporal contexts while preserving the smaller-scale features required for precise localization: a one-dimensional version of a u-net, and a Transformer encoder (TE). We also suggest best practices for training models of this kind, by applying Sharpness-Aware Minimization (SAM) and mixup data augmentation. We achieve a new state-of-the-art on SoccerNet-v2, the largest soccer video dataset of its kind, with marked improvements in temporal localization. Additionally, our ablations show: the importance of predicting the temporal displacements; the trade-offs between the u-net and TE trunks; and the benefits of training with SAM and mixup.