 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplementary-Similarity Learning using Quadruplet Network
Paper and Code
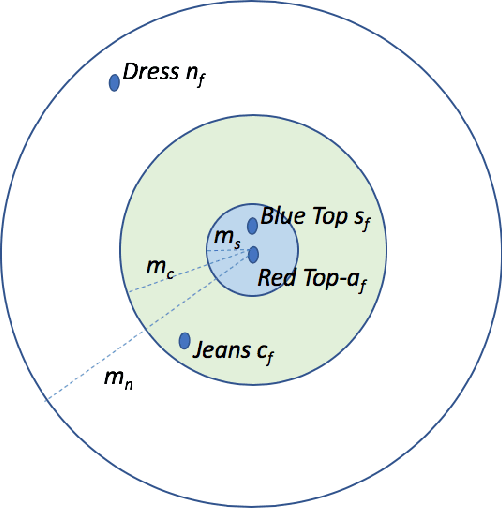


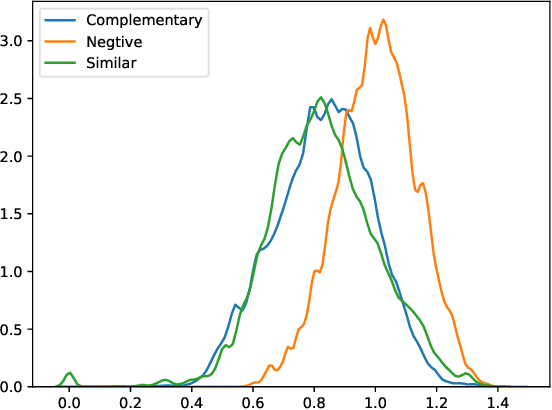
We propose a novel learning framework to answer questions such as "if a user is purchasing a shirt, what other items will (s)he need with the shirt?" Our framework learns distributed representations for items from available textual data, with the learned representations representing items in a latent space expressing functional complementarity as well similarity. In particular, our framework places functionally similar items close together in the latent space, while also placing complementary items closer than non-complementary items, but farther away than similar items. In this study, we introduce a new dataset of similar, complementary, and negative items derived from the Amazon co-purchase dataset. For evaluation purposes, we focus our approach on clothing and fashion verticals. As per our knowledge, this is the first attempt to learn similar and complementary relationships simultaneously through just textual title metadata. Our framework is applicable across a broad set of items in the product catalog and can generate quality complementary item recommendations at scale.