 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline RL With Resource Constrained Online Deployment
Oct 07, 2021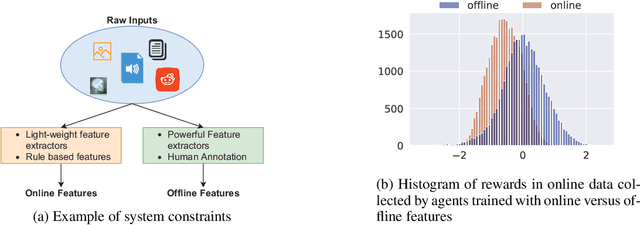


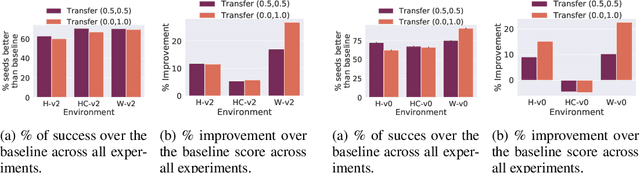
Offline reinforcement learning is used to train policies in scenarios where real-time access to the environment is expensive or impossible. As a natural consequence of these harsh conditions, an agent may lack the resources to fully observe the online environment before taking an action. We dub this situation the resource-constrained setting. This leads to situations where the offline dataset (available for training) can contain fully processed features (using powerful language models, image models, complex sensors, etc.) which are not available when actions are actually taken online. This disconnect leads to an interesting and unexplored problem in offline RL: Is it possible to use a richly processed offline dataset to train a policy which has access to fewer features in the online environment? In this work, we introduce and formalize this novel resource-constrained problem setting. We highlight the performance gap between policies trained using the full offline dataset and policies trained using limited features. We address this performance gap with a policy transfer algorithm which first trains a teacher agent using the offline dataset where features are fully available, and then transfers this knowledge to a student agent that only uses the resource-constrained features. To better capture the challenge of this setting, we propose a data collection procedure: Resource Constrained-Datasets for RL (RC-D4RL). We evaluate our transfer algorithm on RC-D4RL and the popular D4RL benchmarks and observe consistent improvement over the baseline (TD3+BC without transfer). The code for the experiments is available at https://github.com/JayanthRR/RC-OfflineRL}{github.com/RC-OfflineRL.
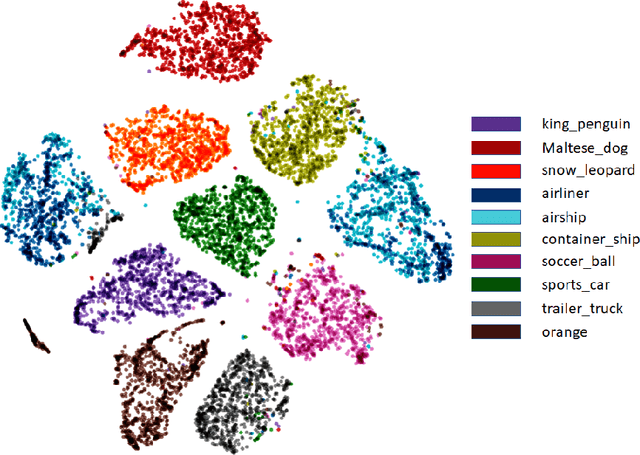
Representation Learning for Clustering via Building Consensus
May 04, 2021
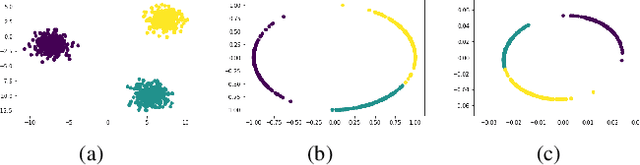
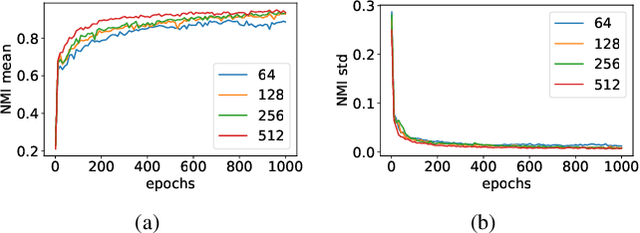

In this paper, we focus on deep clustering and unsupervised representation learning for images. Recent advances in deep clustering and unsupervised representation learning are based on the idea that different views of an input image (generated through data augmentation techniques) must be closer in the representation space (exemplar consistency), and/or similar images have a similar cluster assignment (population consistency). We define an additional notion of consistency, consensus consistency, which ensures that representations are learnt to induce similar partitions for variations in the representation space, different clustering algorithms or different initializations of a clustering algorithm. We define a clustering loss by performing variations in the representation space and seamlessly integrate all three consistencies (consensus, exemplar and population) into an end-to-end learning framework. The proposed algorithm, Consensus Clustering using Unsupervised Representation Learning (ConCURL) improves the clustering performance over state-of-the art methods on four out of five image datasets. Further, we extend the evaluation procedure for clustering to reflect the challenges in real world clustering tasks, such as clustering performance in the case of distribution shift. We also perform a detailed ablation study for a deeper understanding of the algorithm.
Consensus Clustering with Unsupervised Representation Learning
Oct 03, 2020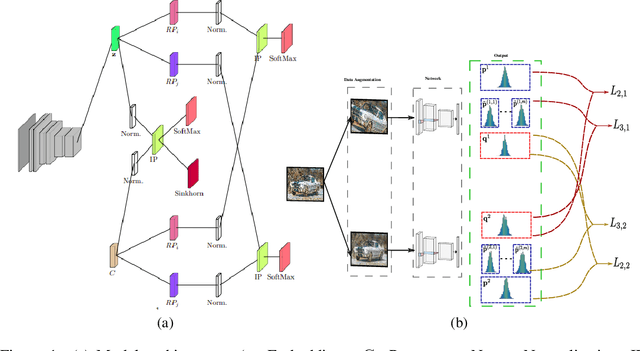


Recent advances in deep clustering and unsupervised representation learning are based on the idea that different views of an input image (generated through data augmentation techniques) must either be closer in the representation space, or have a similar cluster assignment. In this work, we leverage this idea together with ensemble learning to perform clustering and representation learning. Ensemble learning is widely used in the supervised learning setting but has not yet been practical in deep clustering. Previous works on ensemble learning for clustering neither work on the feature space nor learn features. We propose a novel ensemble learning algorithm dubbed Consensus Clustering with Unsupervised Representation Learning (ConCURL) which learns representations by creating a consensus on multiple clustering outputs. Specifically, we generate a cluster ensemble using random transformations on the embedding space, and define a consensus loss function that measures the disagreement among the constituents of the ensemble. Thus, diverse ensembles minimize this loss function in a synergistic way, which leads to better representations that work with all cluster ensemble constituents. Our proposed method ConCURL is easy to implement and integrate into any representation learning or deep clustering block. ConCURL outperforms all state of the art methods on various computer vision datasets. Specifically, we beat the closest state of the art method by 5.9 percent on the ImageNet-10 dataset, and by 18 percent on the ImageNet-Dogs dataset in terms of clustering accuracy. We further shed some light on the under-studied overfitting issue in clustering and show that our method does not overfit as much as existing methods, and thereby generalizes better for new data samples.