 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePearl: A Production-ready Reinforcement Learning Agent
Dec 06, 2023



Reinforcement Learning (RL) offers a versatile framework for achieving long-term goals. Its generality allows us to formalize a wide range of problems that real-world intelligent systems encounter, such as dealing with delayed rewards, handling partial observability, addressing the exploration and exploitation dilemma, utilizing offline data to improve online performance, and ensuring safety constraints are met. Despite considerable progress made by the RL research community in addressing these issues, existing open-source RL libraries tend to focus on a narrow portion of the RL solution pipeline, leaving other aspects largely unattended. This paper introduces Pearl, a Production-ready RL agent software package explicitly designed to embrace these challenges in a modular fashion. In addition to presenting preliminary benchmark results, this paper highlights Pearl's industry adoptions to demonstrate its readiness for production usage. Pearl is open sourced on Github at github.com/facebookresearch/pearl and its official website is located at pearlagent.github.io.
Offline Reinforcement Learning for Optimizing Production Bidding Policies
Oct 13, 2023The online advertising market, with its thousands of auctions run per second, presents a daunting challenge for advertisers who wish to optimize their spend under a budget constraint. Thus, advertising platforms typically provide automated agents to their customers, which act on their behalf to bid for impression opportunities in real time at scale. Because these proxy agents are owned by the platform but use advertiser funds to operate, there is a strong practical need to balance reliability and explainability of the agent with optimizing power. We propose a generalizable approach to optimizing bidding policies in production environments by learning from real data using offline reinforcement learning. This approach can be used to optimize any differentiable base policy (practically, a heuristic policy based on principles which the advertiser can easily understand), and only requires data generated by the base policy itself. We use a hybrid agent architecture that combines arbitrary base policies with deep neural networks, where only the optimized base policy parameters are eventually deployed, and the neural network part is discarded after training. We demonstrate that such an architecture achieves statistically significant performance gains in both simulated and at-scale production bidding environments. Our approach does not incur additional infrastructure, safety, or explainability costs, as it directly optimizes parameters of existing production routines without replacing them with black box-style models like neural networks.
Offline RL With Resource Constrained Online Deployment
Oct 07, 2021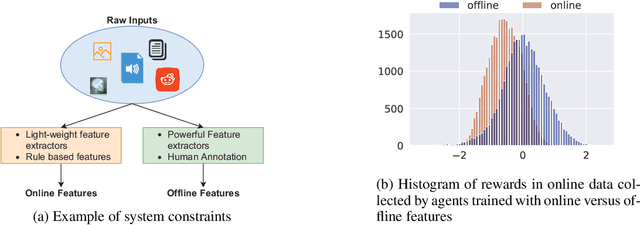


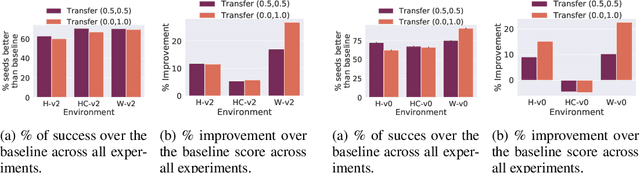
Offline reinforcement learning is used to train policies in scenarios where real-time access to the environment is expensive or impossible. As a natural consequence of these harsh conditions, an agent may lack the resources to fully observe the online environment before taking an action. We dub this situation the resource-constrained setting. This leads to situations where the offline dataset (available for training) can contain fully processed features (using powerful language models, image models, complex sensors, etc.) which are not available when actions are actually taken online. This disconnect leads to an interesting and unexplored problem in offline RL: Is it possible to use a richly processed offline dataset to train a policy which has access to fewer features in the online environment? In this work, we introduce and formalize this novel resource-constrained problem setting. We highlight the performance gap between policies trained using the full offline dataset and policies trained using limited features. We address this performance gap with a policy transfer algorithm which first trains a teacher agent using the offline dataset where features are fully available, and then transfers this knowledge to a student agent that only uses the resource-constrained features. To better capture the challenge of this setting, we propose a data collection procedure: Resource Constrained-Datasets for RL (RC-D4RL). We evaluate our transfer algorithm on RC-D4RL and the popular D4RL benchmarks and observe consistent improvement over the baseline (TD3+BC without transfer). The code for the experiments is available at https://github.com/JayanthRR/RC-OfflineRL}{github.com/RC-OfflineRL.
Physically Realizable Adversarial Examples for LiDAR Object Detection
Apr 02, 2020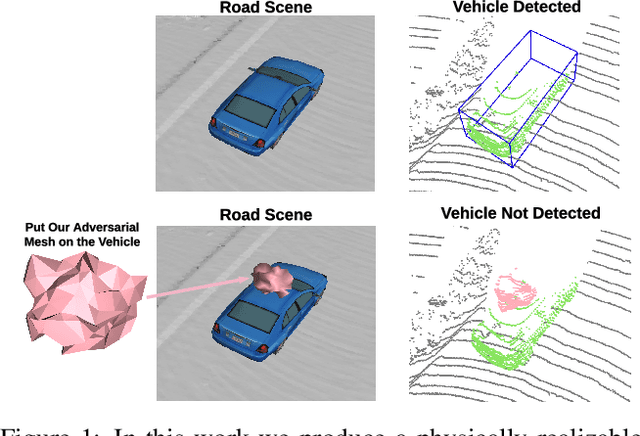
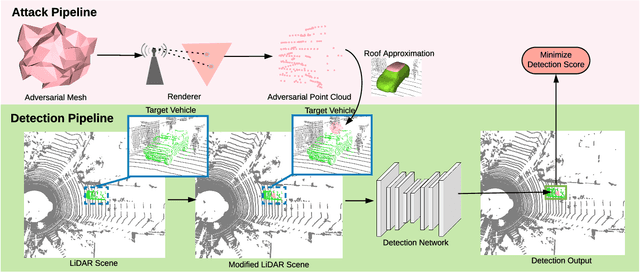
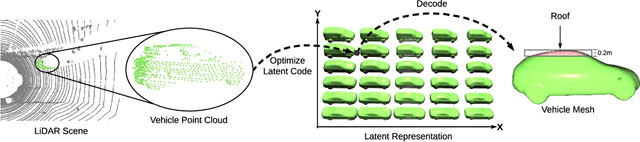

Modern autonomous driving systems rely heavily on deep learning models to process point cloud sensory data; meanwhile, deep models have been shown to be susceptible to adversarial attacks with visually imperceptible perturbations. Despite the fact that this poses a security concern for the self-driving industry, there has been very little exploration in terms of 3D perception, as most adversarial attacks have only been applied to 2D flat images. In this paper, we address this issue and present a method to generate universal 3D adversarial objects to fool LiDAR detectors. In particular, we demonstrate that placing an adversarial object on the rooftop of any target vehicle to hide the vehicle entirely from LiDAR detectors with a success rate of 80%. We report attack results on a suite of detectors using various input representation of point clouds. We also conduct a pilot study on adversarial defense using data augmentation. This is one step closer towards safer self-driving under unseen conditions from limited training data.