 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Contextual Bandits in Computer Vision
Mar 18, 2020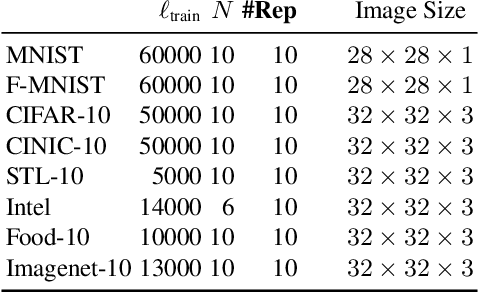
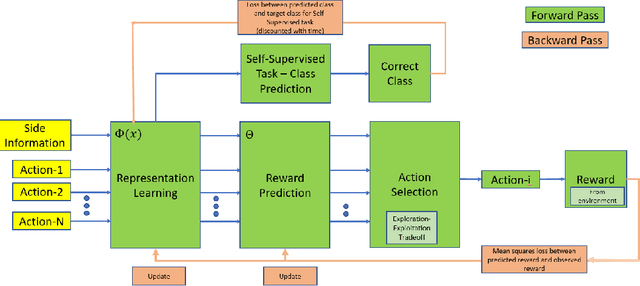
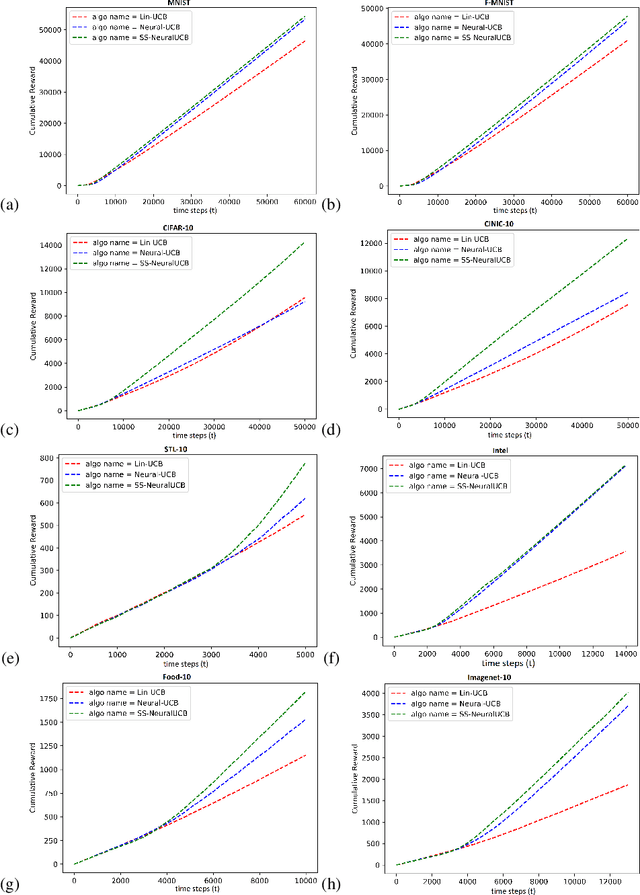
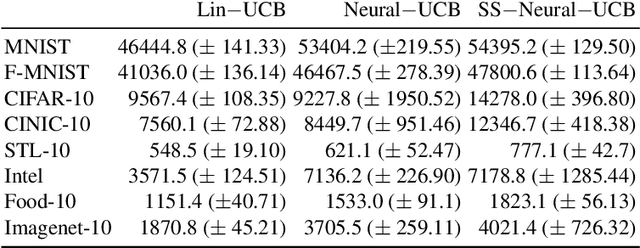
Contextual bandits are a common problem faced by machine learning practitioners in domains as diverse as hypothesis testing to product recommendations. There have been a lot of approaches in exploiting rich data representations for contextual bandit problems with varying degree of success. Self-supervised learning is a promising approach to find rich data representations without explicit labels. In a typical self-supervised learning scheme, the primary task is defined by the problem objective (e.g. clustering, classification, embedding generation etc.) and the secondary task is defined by the self-supervision objective (e.g. rotation prediction, words in neighborhood, colorization, etc.). In the usual self-supervision, we learn implicit labels from the training data for a secondary task. However, in the contextual bandit setting, we don't have the advantage of getting implicit labels due to lack of data in the initial phase of learning. We provide a novel approach to tackle this issue by combining a contextual bandit objective with a self supervision objective. By augmenting contextual bandit learning with self-supervision we get a better cumulative reward. Our results on eight popular computer vision datasets show substantial gains in cumulative reward. We provide cases where the proposed scheme doesn't perform optimally and give alternative methods for better learning in these cases.
Modeling and Simultaneously Removing Bias via Adversarial Neural Networks
Apr 18, 2018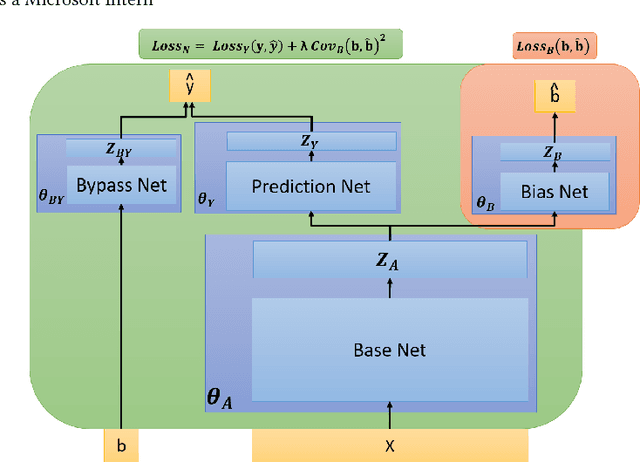
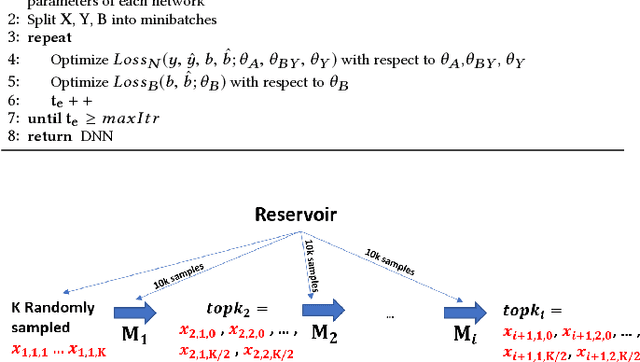
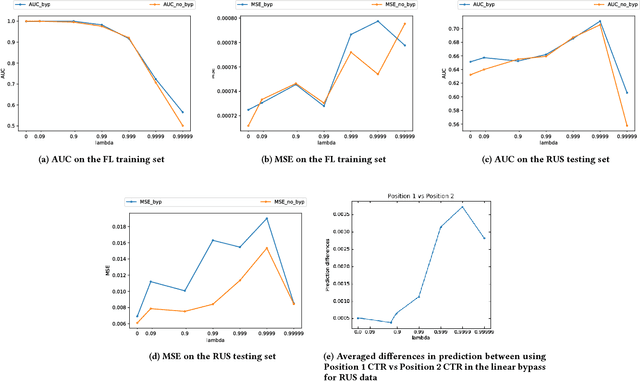
In real world systems, the predictions of deployed Machine Learned models affect the training data available to build subsequent models. This introduces a bias in the training data that needs to be addressed. Existing solutions to this problem attempt to resolve the problem by either casting this in the reinforcement learning framework or by quantifying the bias and re-weighting the loss functions. In this work, we develop a novel Adversarial Neural Network (ANN) model, an alternative approach which creates a representation of the data that is invariant to the bias. We take the Paid Search auction as our working example and ad display position features as the confounding features for this setting. We show the success of this approach empirically on both synthetic data as well as real world paid search auction data from a major search engine.
Stochastic Collapsed Variational Bayesian Inference for Latent Dirichlet Allocation
May 10, 2013
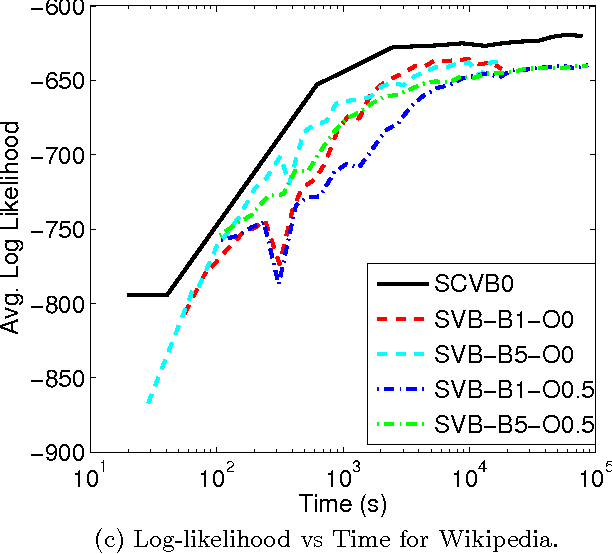
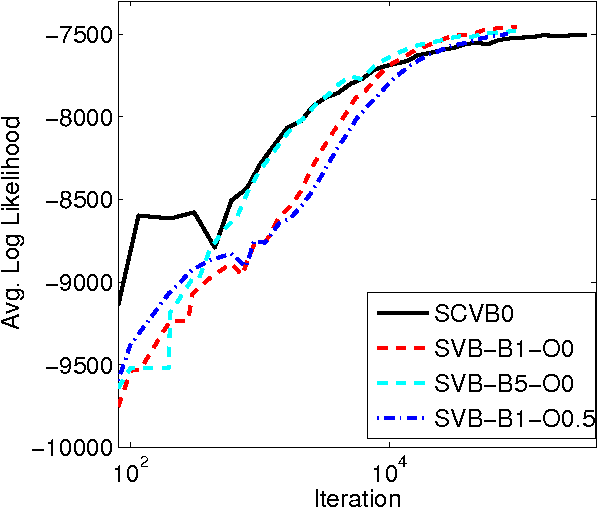
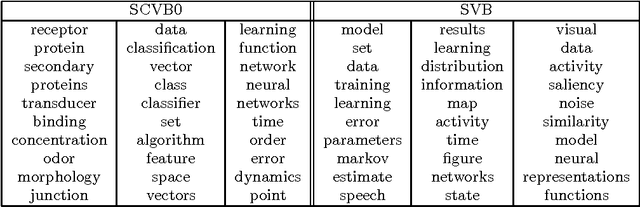
In the internet era there has been an explosion in the amount of digital text information available, leading to difficulties of scale for traditional inference algorithms for topic models. Recent advances in stochastic variational inference algorithms for latent Dirichlet allocation (LDA) have made it feasible to learn topic models on large-scale corpora, but these methods do not currently take full advantage of the collapsed representation of the model. We propose a stochastic algorithm for collapsed variational Bayesian inference for LDA, which is simpler and more efficient than the state of the art method. We show connections between collapsed variational Bayesian inference and MAP estimation for LDA, and leverage these connections to prove convergence properties of the proposed algorithm. In experiments on large-scale text corpora, the algorithm was found to converge faster and often to a better solution than the previous method. Human-subject experiments also demonstrated that the method can learn coherent topics in seconds on small corpora, facilitating the use of topic models in interactive document analysis software.