 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Transfer Random Forest: Combining Logged Data and Randomized Experiments for Robust Prediction
Oct 17, 2020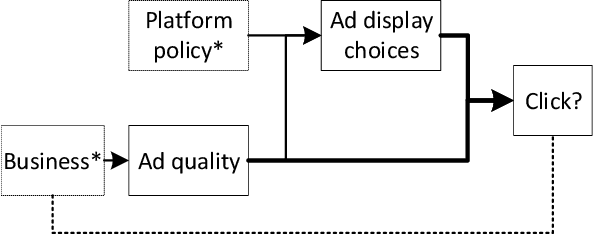
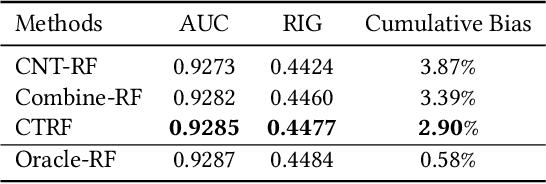
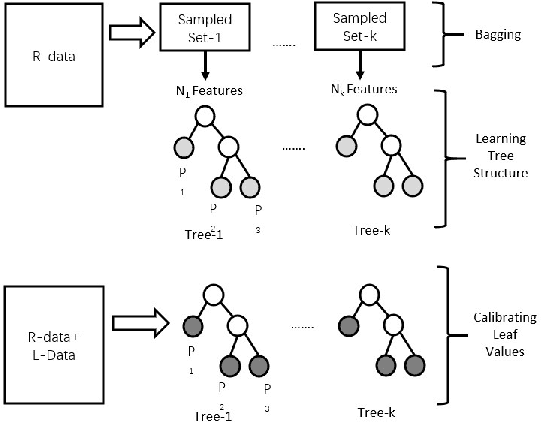
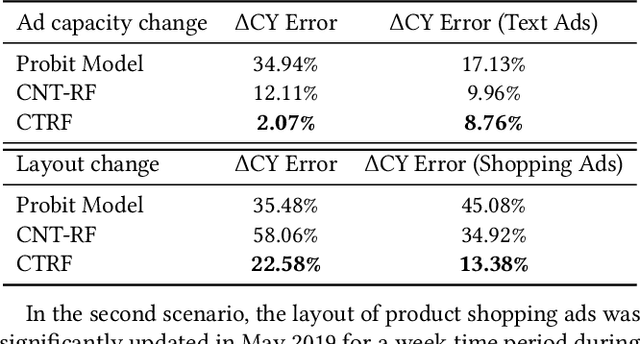
It is often critical for prediction models to be robust to distributional shifts between training and testing data. Viewed from a causal perspective, the challenge is to distinguish the stable causal relationships from the unstable spurious correlations across shifts. We describe a causal transfer random forest (CTRF) that combines existing training data with a small amount of data from a randomized experiment to train a model which is robust to the feature shifts and therefore transfers to a new targeting distribution. Theoretically, we justify the robustness of the approach against feature shifts with the knowledge from causal learning. Empirically, we evaluate the CTRF using both synthetic data experiments and real-world experiments in the Bing Ads platform, including a click prediction task and in the context of an end-to-end counterfactual optimization system. The proposed CTRF produces robust predictions and outperforms most baseline methods compared in the presence of feature shifts.
Causal Inference in the Presence of Interference in Sponsored Search Advertising
Oct 15, 2020


In classical causal inference, inferring cause-effect relations from data relies on the assumption that units are independent and identically distributed. This assumption is violated in settings where units are related through a network of dependencies. An example of such a setting is ad placement in sponsored search advertising, where the clickability of a particular ad is potentially influenced by where it is placed and where other ads are placed on the search result page. In such scenarios, confounding arises due to not only the individual ad-level covariates but also the placements and covariates of other ads in the system. In this paper, we leverage the language of causal inference in the presence of interference to model interactions among the ads. Quantification of such interactions allows us to better understand the click behavior of users, which in turn impacts the revenue of the host search engine and enhances user satisfaction. We illustrate the utility of our formalization through experiments carried out on the ad placement system of the Bing search engine.
Modeling and Simultaneously Removing Bias via Adversarial Neural Networks
Apr 18, 2018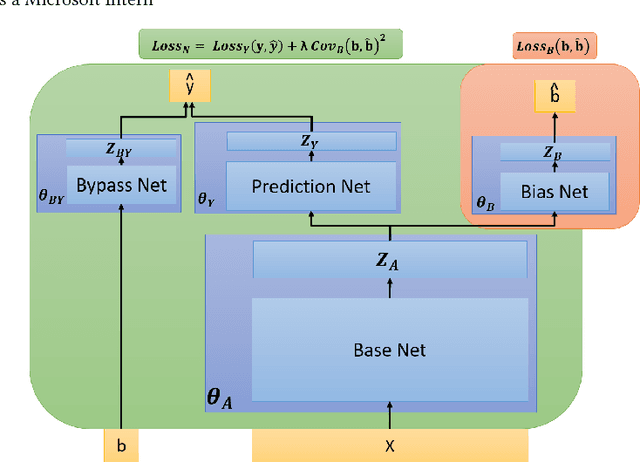
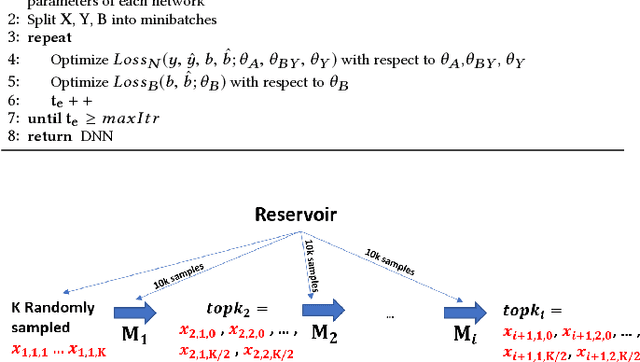
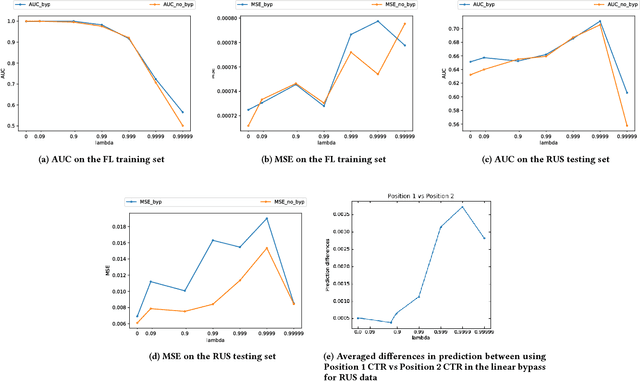
In real world systems, the predictions of deployed Machine Learned models affect the training data available to build subsequent models. This introduces a bias in the training data that needs to be addressed. Existing solutions to this problem attempt to resolve the problem by either casting this in the reinforcement learning framework or by quantifying the bias and re-weighting the loss functions. In this work, we develop a novel Adversarial Neural Network (ANN) model, an alternative approach which creates a representation of the data that is invariant to the bias. We take the Paid Search auction as our working example and ad display position features as the confounding features for this setting. We show the success of this approach empirically on both synthetic data as well as real world paid search auction data from a major search engine.