 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoHint: Automatic Prompt Optimization with Hint Generation
Jul 13, 2023
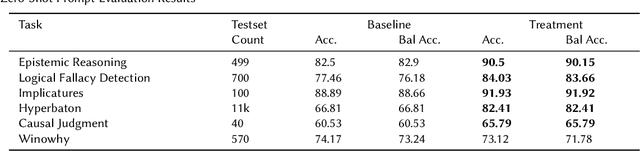
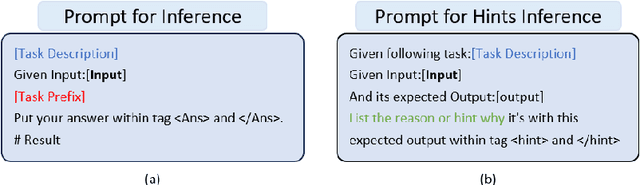
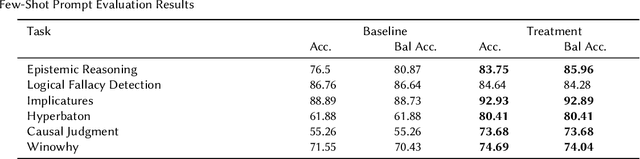
This paper presents AutoHint, a novel framework for automatic prompt engineering and optimization for Large Language Models (LLM). While LLMs have demonstrated remarkable ability in achieving high-quality annotation in various tasks, the key to applying this ability to specific tasks lies in developing high-quality prompts. Thus we propose a framework to inherit the merits of both in-context learning and zero-shot learning by incorporating enriched instructions derived from input-output demonstrations to optimize original prompt. We refer to the enrichment as the hint and propose a framework to automatically generate the hint from labeled data. More concretely, starting from an initial prompt, our method first instructs a LLM to deduce new hints for selected samples from incorrect predictions, and then summarizes from per-sample hints and adds the results back to the initial prompt to form a new, enriched instruction. The proposed method is evaluated on the BIG-Bench Instruction Induction dataset for both zero-shot and few-short prompts, where experiments demonstrate our method is able to significantly boost accuracy for multiple tasks.
Look Again at the Syntax: Relational Graph Convolutional Network for Gendered Ambiguous Pronoun Resolution
May 31, 2019



Gender bias has been found in existing coreference resolvers. In order to eliminate gender bias, a gender-balanced dataset Gendered Ambiguous Pronouns (GAP) has been released and the best baseline model achieves only 66.9% F1. Bidirectional Encoder Representations from Transformers (BERT) has broken several NLP task records and can be used on GAP dataset. However, fine-tune BERT on a specific task is computationally expensive. In this paper, we propose an end-to-end resolver by combining pre-trained BERT with Relational Graph Convolutional Network (R-GCN). R-GCN is used for digesting structural syntactic information and learning better task-specific embeddings. Empirical results demonstrate that, under explicit syntactic supervision and without the need to fine tune BERT, R-GCN's embeddings outperform the original BERT embeddings on the coreference task. Our work significantly improves the snippet-context baseline F1 score on GAP dataset from 66.9% to 80.3%. We participated in the 2019 GAP Coreference Shared Task, and our codes are available online.