 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCVI-SANet: A lightweight semi-supervised model for LAI and SPAD estimation of winter wheat under vegetation index saturation
Dec 20, 2025Vegetation index (VI) saturation during the dense canopy stage and limited ground-truth annotations of winter wheat constrain accurate estimation of LAI and SPAD. Existing VI-based and texture-driven machine learning methods exhibit limited feature expressiveness. In addition, deep learning baselines suffer from domain gaps and high data demands, which restrict their generalization. Therefore, this study proposes the Multi-Channel Vegetation Indices Saturation Aware Net (MCVI-SANet), a lightweight semi-supervised vision model. The model incorporates a newly designed Vegetation Index Saturation-Aware Block (VI-SABlock) for adaptive channel-spatial feature enhancement. It also integrates a VICReg-based semi-supervised strategy to further improve generalization. Datasets were partitioned using a vegetation height-informed strategy to maintain representativeness across growth stages. Experiments over 10 repeated runs demonstrate that MCVI-SANet achieves state-of-the-art accuracy. The model attains an average R2 of 0.8123 and RMSE of 0.4796 for LAI, and an average R2 of 0.6846 and RMSE of 2.4222 for SPAD. This performance surpasses the best-performing baselines, with improvements of 8.95% in average LAI R2 and 8.17% in average SPAD R2. Moreover, MCVI-SANet maintains high inference speed with only 0.10M parameters. Overall, the integration of semi-supervised learning with agronomic priors provides a promising approach for enhancing remote sensing-based precision agriculture.
Preference is More Than Comparisons: Rethinking Dueling Bandits with Augmented Human Feedback
Nov 12, 2025Interactive preference elicitation (IPE) aims to substantially reduce human effort while acquiring human preferences in wide personalization systems. Dueling bandit (DB) algorithms enable optimal decision-making in IPE building on pairwise comparisons. However, they remain inefficient when human feedback is sparse. Existing methods address sparsity by heavily relying on parametric reward models, whose rigid assumptions are vulnerable to misspecification. In contrast, we explore an alternative perspective based on feedback augmentation, and introduce critical improvements to the model-free DB framework. Specifically, we introduce augmented confidence bounds to integrate augmented human feedback under generalized concentration properties, and analyze the multi-factored performance trade-off via regret analysis. Our prototype algorithm achieves competitive performance across several IPE benchmarks, including recommendation, multi-objective optimization, and response optimization for large language models, demonstrating the potential of our approach for provably efficient IPE in broader applications.
Unsupervised Atomic Data Mining via Multi-Kernel Graph Autoencoders for Machine Learning Force Fields
Sep 15, 2025
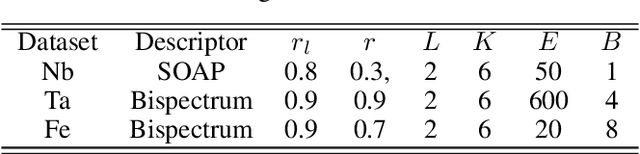
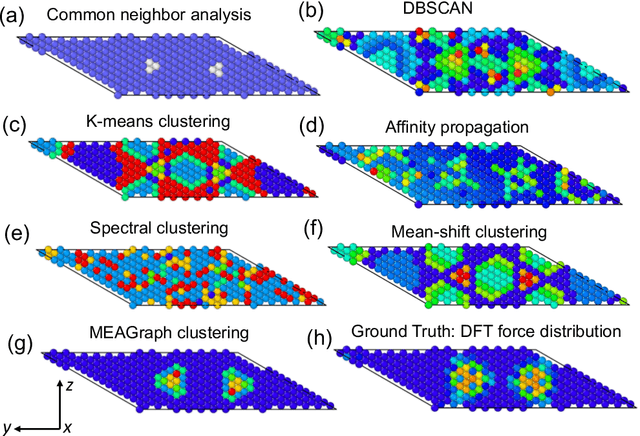
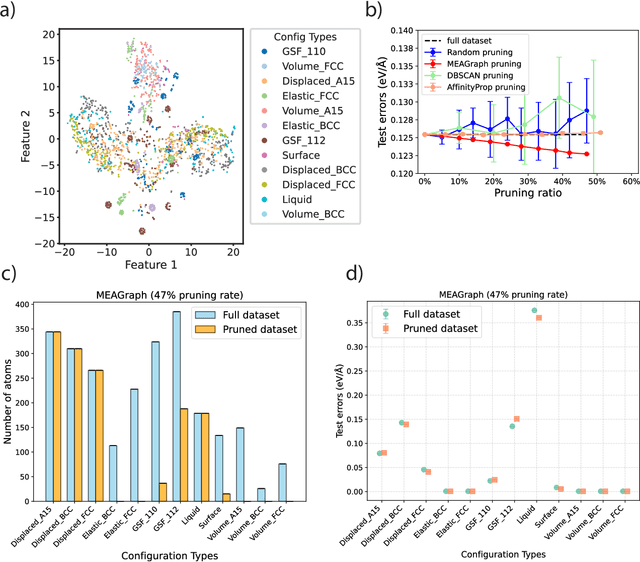
Constructing a chemically diverse dataset while avoiding sampling bias is critical to training efficient and generalizable force fields. However, in computational chemistry and materials science, many common dataset generation techniques are prone to oversampling regions of the potential energy surface. Furthermore, these regions can be difficult to identify and isolate from each other or may not align well with human intuition, making it challenging to systematically remove bias in the dataset. While traditional clustering and pruning (down-sampling) approaches can be useful for this, they can often lead to information loss or a failure to properly identify distinct regions of the potential energy surface due to difficulties associated with the high dimensionality of atomic descriptors. In this work, we introduce the Multi-kernel Edge Attention-based Graph Autoencoder (MEAGraph) model, an unsupervised approach for analyzing atomic datasets. MEAGraph combines multiple linear kernel transformations with attention-based message passing to capture geometric sensitivity and enable effective dataset pruning without relying on labels or extensive training. Demonstrated applications on niobium, tantalum, and iron datasets show that MEAGraph efficiently groups similar atomic environments, allowing for the use of basic pruning techniques for removing sampling bias. This approach provides an effective method for representation learning and clustering that can be used for data analysis, outlier detection, and dataset optimization.
Novel models for fatigue life prediction under wideband random loads based on machine learning
Nov 13, 2023

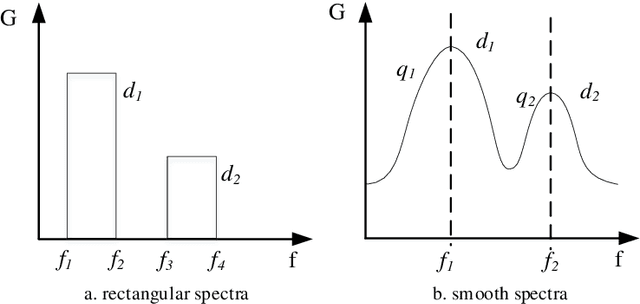

Machine learning as a data-driven solution has been widely applied in the field of fatigue lifetime prediction. In this paper, three models for wideband fatigue life prediction are built based on three machine learning models, i.e. support vector machine (SVM), Gaussian process regression (GPR) and artificial neural network (ANN). The generalization ability of the models is enhanced by employing numerous power spectra samples with different bandwidth parameters and a variety of material properties related to fatigue life. Sufficient Monte Carlo numerical simulations demonstrate that the newly developed machine learning models are superior to the traditional frequency-domain models in terms of life prediction accuracy and the ANN model has the best overall performance among the three developed machine learning models.
Explore the Effect of Data Selection on Poison Efficiency in Backdoor Attacks
Oct 15, 2023



As the number of parameters in Deep Neural Networks (DNNs) scales, the thirst for training data also increases. To save costs, it has become common for users and enterprises to delegate time-consuming data collection to third parties. Unfortunately, recent research has shown that this practice raises the risk of DNNs being exposed to backdoor attacks. Specifically, an attacker can maliciously control the behavior of a trained model by poisoning a small portion of the training data. In this study, we focus on improving the poisoning efficiency of backdoor attacks from the sample selection perspective. The existing attack methods construct such poisoned samples by randomly selecting some clean data from the benign set and then embedding a trigger into them. However, this random selection strategy ignores that each sample may contribute differently to the backdoor injection, thereby reducing the poisoning efficiency. To address the above problem, a new selection strategy named Improved Filtering and Updating Strategy (FUS++) is proposed. Specifically, we adopt the forgetting events of the samples to indicate the contribution of different poisoned samples and use the curvature of the loss surface to analyses the effectiveness of this phenomenon. Accordingly, we combine forgetting events and curvature of different samples to conduct a simple yet efficient sample selection strategy. The experimental results on image classification (CIFAR-10, CIFAR-100, ImageNet-10), text classification (AG News), audio classification (ESC-50), and age regression (Facial Age) consistently demonstrate the effectiveness of the proposed strategy: the attack performance using FUS++ is significantly higher than that using random selection for the same poisoning ratio.
AutoHint: Automatic Prompt Optimization with Hint Generation
Jul 13, 2023
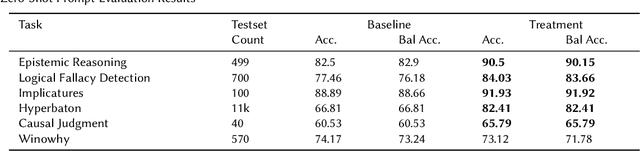
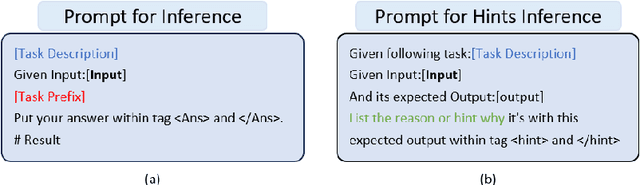
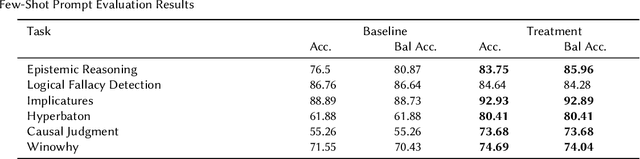
This paper presents AutoHint, a novel framework for automatic prompt engineering and optimization for Large Language Models (LLM). While LLMs have demonstrated remarkable ability in achieving high-quality annotation in various tasks, the key to applying this ability to specific tasks lies in developing high-quality prompts. Thus we propose a framework to inherit the merits of both in-context learning and zero-shot learning by incorporating enriched instructions derived from input-output demonstrations to optimize original prompt. We refer to the enrichment as the hint and propose a framework to automatically generate the hint from labeled data. More concretely, starting from an initial prompt, our method first instructs a LLM to deduce new hints for selected samples from incorrect predictions, and then summarizes from per-sample hints and adds the results back to the initial prompt to form a new, enriched instruction. The proposed method is evaluated on the BIG-Bench Instruction Induction dataset for both zero-shot and few-short prompts, where experiments demonstrate our method is able to significantly boost accuracy for multiple tasks.
Efficient Backdoor Attacks for Deep Neural Networks in Real-world Scenarios
Jun 14, 2023



Recent deep neural networks (DNNs) have come to rely on vast amounts of training data, providing an opportunity for malicious attackers to exploit and contaminate the data to carry out backdoor attacks. These attacks significantly undermine the reliability of DNNs. However, existing backdoor attack methods make unrealistic assumptions, assuming that all training data comes from a single source and that attackers have full access to the training data. In this paper, we address this limitation by introducing a more realistic attack scenario where victims collect data from multiple sources, and attackers cannot access the complete training data. We refer to this scenario as data-constrained backdoor attacks. In such cases, previous attack methods suffer from severe efficiency degradation due to the entanglement between benign and poisoning features during the backdoor injection process. To tackle this problem, we propose a novel approach that leverages the pre-trained Contrastive Language-Image Pre-Training (CLIP) model. We introduce three CLIP-based technologies from two distinct streams: Clean Feature Suppression, which aims to suppress the influence of clean features to enhance the prominence of poisoning features, and Poisoning Feature Augmentation, which focuses on augmenting the presence and impact of poisoning features to effectively manipulate the model's behavior. To evaluate the effectiveness, harmlessness to benign accuracy, and stealthiness of our method, we conduct extensive experiments on 3 target models, 3 datasets, and over 15 different settings. The results demonstrate remarkable improvements, with some settings achieving over 100% improvement compared to existing attacks in data-constrained scenarios. Our research contributes to addressing the limitations of existing methods and provides a practical and effective solution for data-constrained backdoor attacks.
A Proxy-Free Strategy for Practically Improving the Poisoning Efficiency in Backdoor Attacks
Jun 14, 2023



Poisoning efficiency is a crucial factor in poisoning-based backdoor attacks. Attackers prefer to use as few poisoned samples as possible to achieve the same level of attack strength, in order to remain undetected. Efficient triggers have significantly improved poisoning efficiency, but there is still room for improvement. Recently, selecting efficient samples has shown promise, but it requires a proxy backdoor injection task to find an efficient poisoned sample set, which can lead to performance degradation if the proxy attack settings are different from the actual settings used by the victims. In this paper, we propose a novel Proxy-Free Strategy (PFS) that selects efficient poisoned samples based on individual similarity and set diversity, effectively addressing this issue. We evaluate the proposed strategy on several datasets, triggers, poisoning ratios, architectures, and training hyperparameters. Our experimental results demonstrate that PFS achieves higher backdoor attack strength while x500 faster than previous proxy-based selection approaches.
A scalable approach for developing clinical risk prediction applications in different hospitals
Jan 21, 2021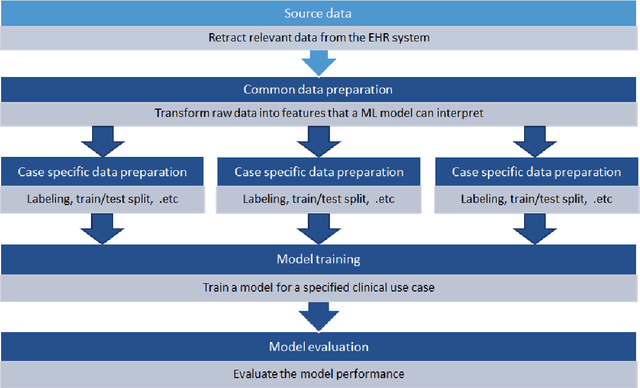
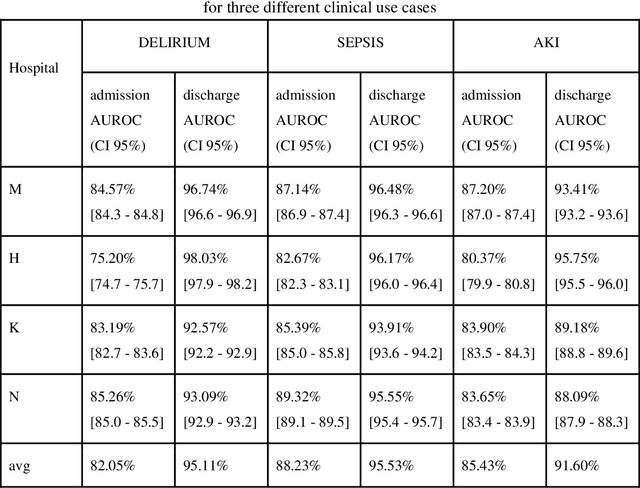

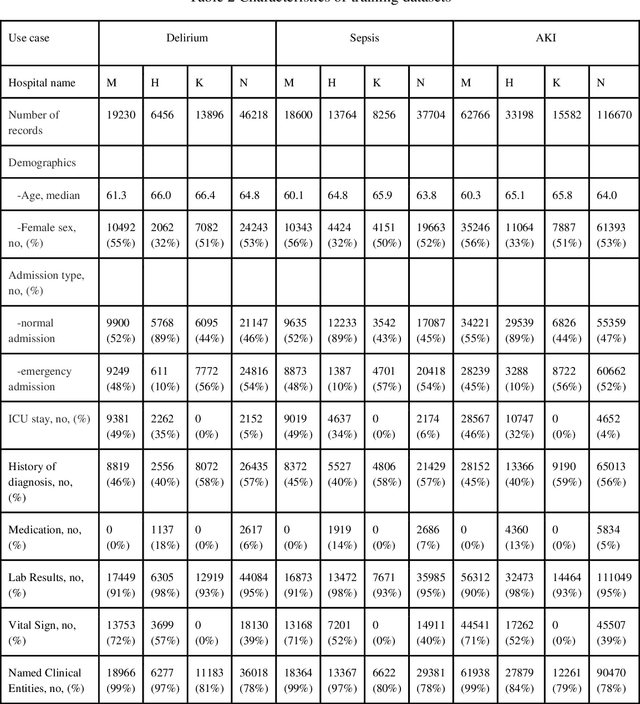
Objective: Machine learning algorithms are now widely used in predicting acute events for clinical applications. While most of such prediction applications are developed to predict the risk of a particular acute event at one hospital, few efforts have been made in extending the developed solutions to other events or to different hospitals. We provide a scalable solution to extend the process of clinical risk prediction model development of multiple diseases and their deployment in different Electronic Health Records (EHR) systems. Materials and Methods: We defined a generic process for clinical risk prediction model development. A calibration tool has been created to automate the model generation process. We applied the model calibration process at four hospitals, and generated risk prediction models for delirium, sepsis and acute kidney injury (AKI) respectively at each of these hospitals. Results: The delirium risk prediction models achieved area under the receiver-operating characteristic curve (AUROC) ranging from 0.82 to 0.95 over different stages of a hospital stay on the test datasets of the four hospitals. The sepsis models achieved AUROC ranging from 0.88 to 0.95, and the AKI models achieved AUROC ranging from 0.85 to 0.92. Discussion: The scalability discussed in this paper is based on building common data representations (syntactic interoperability) between EHRs stored in different hospitals. Semantic interoperability, a more challenging requirement that different EHRs share the same meaning of data, e.g. a same lab coding system, is not mandated with our approach. Conclusions: Our study describes a method to develop and deploy clinical risk prediction models in a scalable way. We demonstrate its feasibility by developing risk prediction models for three diseases across four hospitals.
AutoADR: Automatic Model Design for Ad Relevance
Oct 14, 2020


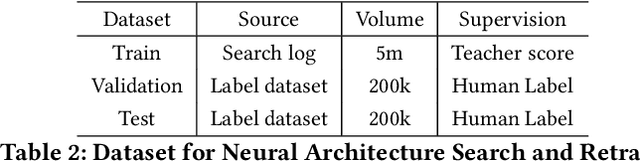
Large-scale pre-trained models have attracted extensive attention in the research community and shown promising results on various tasks of natural language processing. However, these pre-trained models are memory and computation intensive, hindering their deployment into industrial online systems like Ad Relevance. Meanwhile, how to design an effective yet efficient model architecture is another challenging problem in online Ad Relevance. Recently, AutoML shed new lights on architecture design, but how to integrate it with pre-trained language models remains unsettled. In this paper, we propose AutoADR (Automatic model design for AD Relevance) -- a novel end-to-end framework to address this challenge, and share our experience to ship these cutting-edge techniques into online Ad Relevance system at Microsoft Bing. Specifically, AutoADR leverages a one-shot neural architecture search algorithm to find a tailored network architecture for Ad Relevance. The search process is simultaneously guided by knowledge distillation from a large pre-trained teacher model (e.g. BERT), while taking the online serving constraints (e.g. memory and latency) into consideration. We add the model designed by AutoADR as a sub-model into the production Ad Relevance model. This additional sub-model improves the Precision-Recall AUC (PR AUC) on top of the original Ad Relevance model by 2.65X of the normalized shipping bar. More importantly, adding this automatically designed sub-model leads to a statistically significant 4.6% Bad-Ad ratio reduction in online A/B testing. This model has been shipped into Microsoft Bing Ad Relevance Production model.