 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy Data-Driven Wildfire Risk Prediction and Understanding in Western Canada
Jan 04, 2026In recent decades, the intensification of wildfire activity in western Canada has resulted in substantial socio-economic and environmental losses. Accurate wildfire risk prediction is hindered by the intrinsic stochasticity of ignition and spread and by nonlinear interactions among fuel conditions, meteorology, climate variability, topography, and human activities, challenging the reliability and interpretability of purely data-driven models. We propose a trustworthy data-driven wildfire risk prediction framework based on long-sequence, multi-scale temporal modeling, which integrates heterogeneous drivers while explicitly quantifying predictive uncertainty and enabling process-level interpretation. Evaluated over western Canada during the record-breaking 2023 and 2024 fire seasons, the proposed model outperforms existing time-series approaches, achieving an F1 score of 0.90 and a PR-AUC of 0.98 with low computational cost. Uncertainty-aware analysis reveals structured spatial and seasonal patterns in predictive confidence, highlighting increased uncertainty associated with ambiguous predictions and spatiotemporal decision boundaries. SHAP-based interpretation provides mechanistic understanding of wildfire controls, showing that temperature-related drivers dominate wildfire risk in both years, while moisture-related constraints play a stronger role in shaping spatial and land-cover-specific contrasts in 2024 compared to the widespread hot and dry conditions of 2023. Data and code are available at https://github.com/SynUW/mmFire.
One-shot Generative Domain Adaptation in 3D GANs
Oct 11, 2024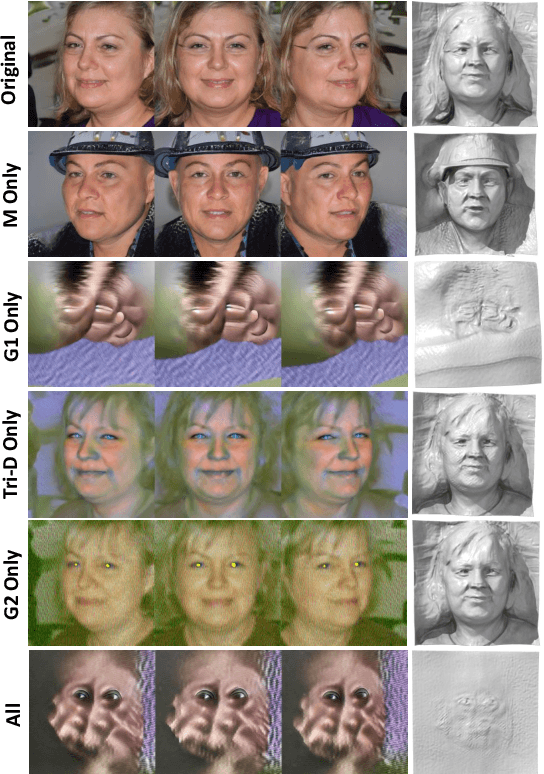
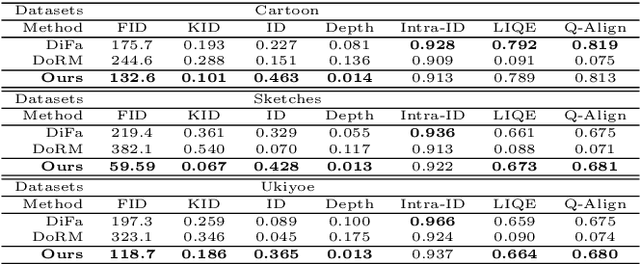
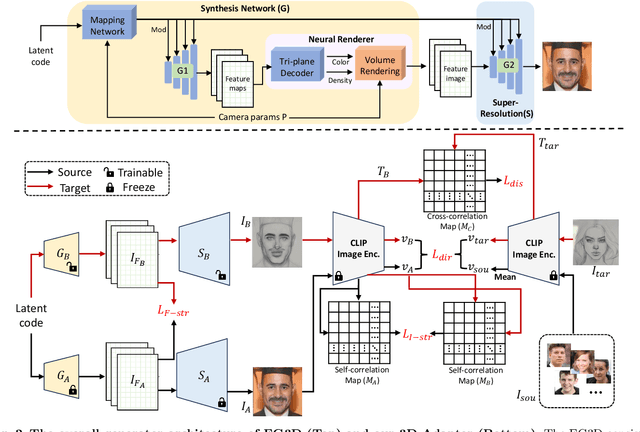

3D-aware image generation necessitates extensive training data to ensure stable training and mitigate the risk of overfitting. This paper first considers a novel task known as One-shot 3D Generative Domain Adaptation (GDA), aimed at transferring a pre-trained 3D generator from one domain to a new one, relying solely on a single reference image. One-shot 3D GDA is characterized by the pursuit of specific attributes, namely, high fidelity, large diversity, cross-domain consistency, and multi-view consistency. Within this paper, we introduce 3D-Adapter, the first one-shot 3D GDA method, for diverse and faithful generation. Our approach begins by judiciously selecting a restricted weight set for fine-tuning, and subsequently leverages four advanced loss functions to facilitate adaptation. An efficient progressive fine-tuning strategy is also implemented to enhance the adaptation process. The synergy of these three technological components empowers 3D-Adapter to achieve remarkable performance, substantiated both quantitatively and qualitatively, across all desired properties of 3D GDA. Furthermore, 3D-Adapter seamlessly extends its capabilities to zero-shot scenarios, and preserves the potential for crucial tasks such as interpolation, reconstruction, and editing within the latent space of the pre-trained generator. Code will be available at https://github.com/iceli1007/3D-Adapter.
Peer is Your Pillar: A Data-unbalanced Conditional GANs for Few-shot Image Generation
Nov 14, 2023



Few-shot image generation aims to train generative models using a small number of training images. When there are few images available for training (e.g. 10 images), Learning From Scratch (LFS) methods often generate images that closely resemble the training data while Transfer Learning (TL) methods try to improve performance by leveraging prior knowledge from GANs pre-trained on large-scale datasets. However, current TL methods may not allow for sufficient control over the degree of knowledge preservation from the source model, making them unsuitable for setups where the source and target domains are not closely related. To address this, we propose a novel pipeline called Peer is your Pillar (PIP), which combines a target few-shot dataset with a peer dataset to create a data-unbalanced conditional generation. Our approach includes a class embedding method that separates the class space from the latent space, and we use a direction loss based on pre-trained CLIP to improve image diversity. Experiments on various few-shot datasets demonstrate the advancement of the proposed PIP, especially reduces the training requirements of few-shot image generation.
A Proxy-Free Strategy for Practically Improving the Poisoning Efficiency in Backdoor Attacks
Jun 14, 2023



Poisoning efficiency is a crucial factor in poisoning-based backdoor attacks. Attackers prefer to use as few poisoned samples as possible to achieve the same level of attack strength, in order to remain undetected. Efficient triggers have significantly improved poisoning efficiency, but there is still room for improvement. Recently, selecting efficient samples has shown promise, but it requires a proxy backdoor injection task to find an efficient poisoned sample set, which can lead to performance degradation if the proxy attack settings are different from the actual settings used by the victims. In this paper, we propose a novel Proxy-Free Strategy (PFS) that selects efficient poisoned samples based on individual similarity and set diversity, effectively addressing this issue. We evaluate the proposed strategy on several datasets, triggers, poisoning ratios, architectures, and training hyperparameters. Our experimental results demonstrate that PFS achieves higher backdoor attack strength while x500 faster than previous proxy-based selection approaches.
Are High-Frequency Components Beneficial for Training of Generative Adversarial Networks
Mar 20, 2021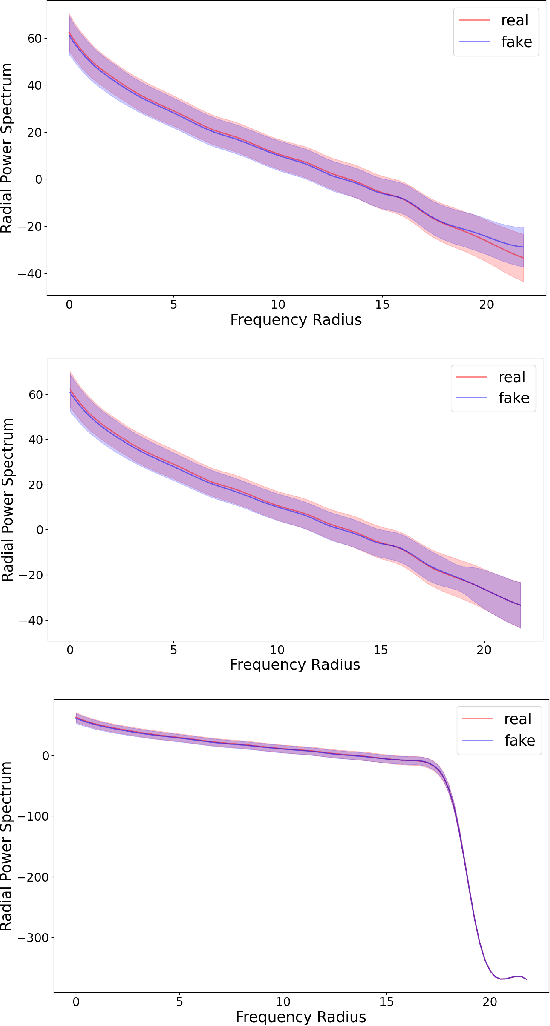
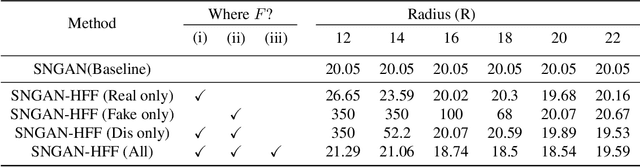
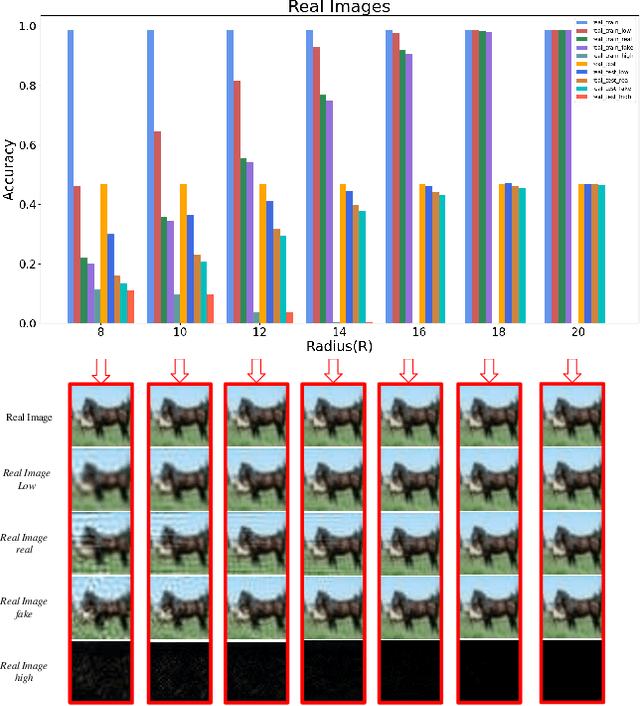
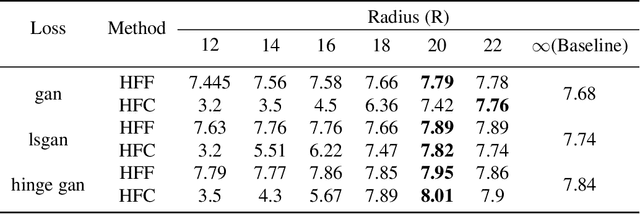
Advancements in Generative Adversarial Networks (GANs) have the ability to generate realistic images that are visually indistinguishable from real images. However, recent studies of the image spectrum have demonstrated that generated and real images share significant differences at high frequency. Furthermore, the high-frequency components invisible to human eyes affect the decision of CNNs and are related to the robustness of it. Similarly, whether the discriminator will be sensitive to the high-frequency differences, thus reducing the fitting ability of the generator to the low-frequency components is an open problem. In this paper, we demonstrate that the discriminator in GANs is sensitive to such high-frequency differences that can not be distinguished by humans and the high-frequency components of images are not conducive to the training of GANs. Based on these, we propose two preprocessing methods eliminating high-frequency differences in GANs training: High-Frequency Confusion (HFC) and High-Frequency Filter (HFF). The proposed methods are general and can be easily applied to most existing GANs frameworks with a fraction of the cost. The advanced performance of the proposed method is verified on multiple loss functions, network architectures, and datasets.