 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoke: Evoking Critical Thinking Abilities in LLMs via Reviewer-Author Prompt Editing
Oct 20, 2023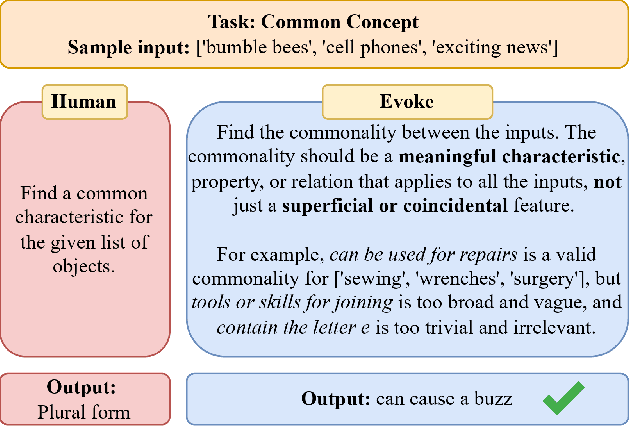
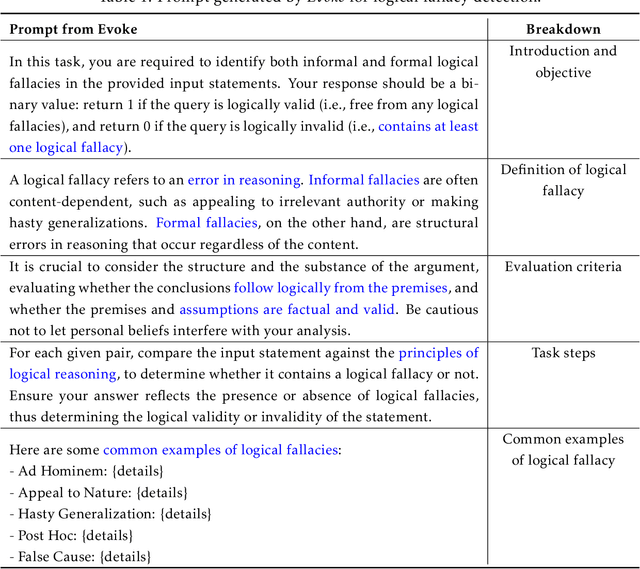
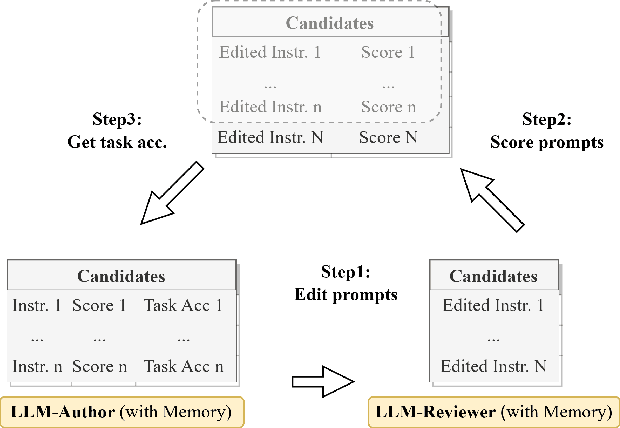
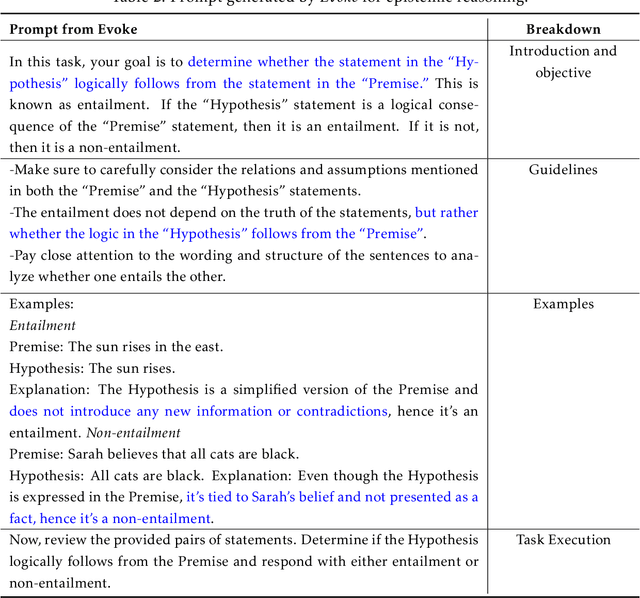
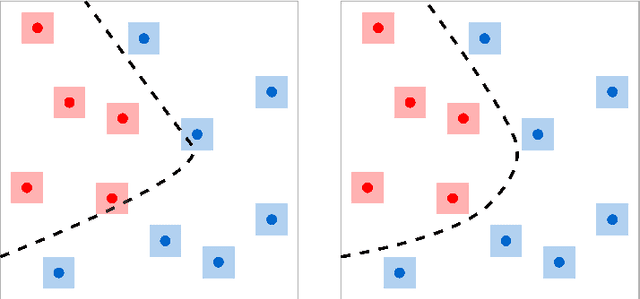
Large language models (LLMs) have made impressive progress in natural language processing. These models rely on proper human instructions (or prompts) to generate suitable responses. However, the potential of LLMs are not fully harnessed by commonly-used prompting methods: many human-in-the-loop algorithms employ ad-hoc procedures for prompt selection; while auto prompt generation approaches are essentially searching all possible prompts randomly and inefficiently. We propose Evoke, an automatic prompt refinement framework. In Evoke, there are two instances of a same LLM: one as a reviewer (LLM-Reviewer), it scores the current prompt; the other as an author (LLM-Author), it edits the prompt by considering the edit history and the reviewer's feedback. Such an author-reviewer feedback loop ensures that the prompt is refined in each iteration. We further aggregate a data selection approach to Evoke, where only the hard samples are exposed to the LLM. The hard samples are more important because the LLM can develop deeper understanding of the tasks out of them, while the model may already know how to solve the easier cases. Experimental results show that Evoke significantly outperforms existing methods. For instance, in the challenging task of logical fallacy detection, Evoke scores above 80, while all other baseline methods struggle to reach 20.
DeepTagger: Knowledge Enhanced Named Entity Recognition for Web-Based Ads Queries
Jun 30, 2023

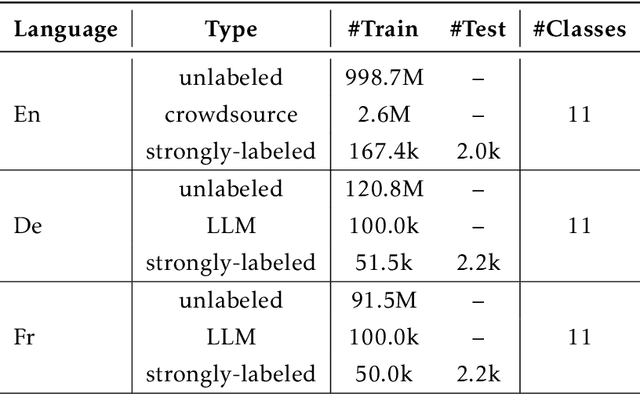
Named entity recognition (NER) is a crucial task for online advertisement. State-of-the-art solutions leverage pre-trained language models for this task. However, three major challenges remain unresolved: web queries differ from natural language, on which pre-trained models are trained; web queries are short and lack contextual information; and labeled data for NER is scarce. We propose DeepTagger, a knowledge-enhanced NER model for web-based ads queries. The proposed knowledge enhancement framework leverages both model-free and model-based approaches. For model-free enhancement, we collect unlabeled web queries to augment domain knowledge; and we collect web search results to enrich the information of ads queries. We further leverage effective prompting methods to automatically generate labels using large language models such as ChatGPT. Additionally, we adopt a model-based knowledge enhancement method based on adversarial data augmentation. We employ a three-stage training framework to train DeepTagger models. Empirical results in various NER tasks demonstrate the effectiveness of the proposed framework.
Constructing Sub-scale Surrogate Model for Proppant Settling in Inclined Fractures from Simulation Data with Multi-fidelity Neural Network
Sep 25, 2021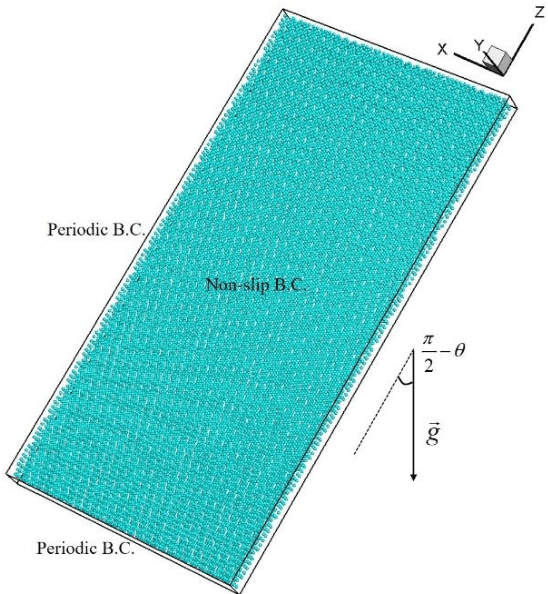
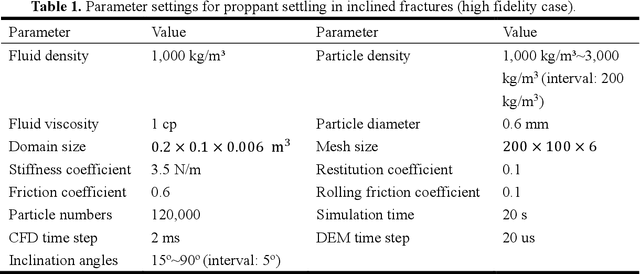
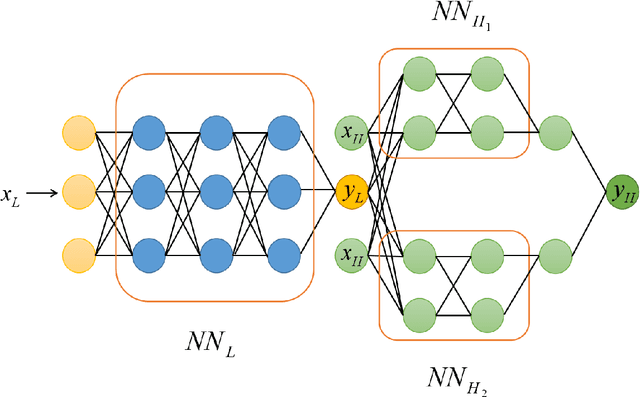
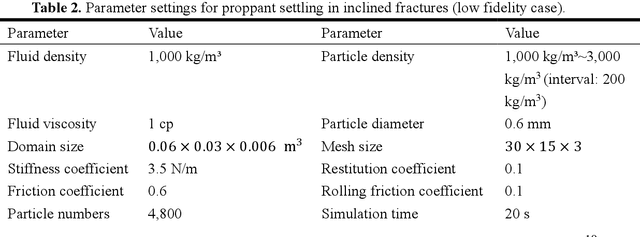
Particle settling in inclined channels is an important phenomenon that occurs during hydraulic fracturing of shale gas production. Generally, in order to accurately simulate the large-scale (field-scale) proppant transport process, constructing a fast and accurate sub-scale proppant settling model, or surrogate model, becomes a critical issue, since mapping between physical parameters and proppant settling velocity is complex. Previously, particle settling has usually been investigated via high-fidelity experiments and meso-scale numerical simulations, both of which are time-consuming. In this work, a new method is proposed and utilized, i.e., the multi-fidelity neural network (MFNN), to construct a settling surrogate model, which could utilize both high-fidelity and low-fidelity (thus, less expensive) data. The results demonstrate that constructing the settling surrogate with the MFNN can reduce the need for high-fidelity data and thus computational cost by 80%, while the accuracy lost is less than 5% compared to a high-fidelity surrogate. Moreover, the investigated particle settling surrogate is applied in macro-scale proppant transport simulation, which shows that the settling model is significant to proppant transport and yields accurate results. This opens novel pathways for rapidly predicting proppant settling velocity in reservoir applications.