 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Function Space View of Bounded Norm Infinite Width ReLU Nets: The Multivariate Case
Paper and Code
Oct 03, 2019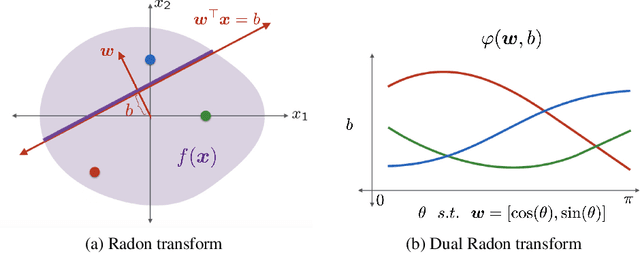
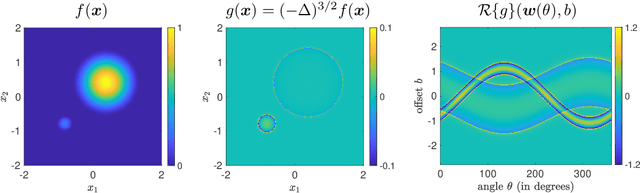
A key element of understanding the efficacy of overparameterized neural networks is characterizing how they represent functions as the number of weights in the network approaches infinity. In this paper, we characterize the norm required to realize a function $f:\mathbb{R}^d\rightarrow\mathbb{R}$ as a single hidden-layer ReLU network with an unbounded number of units (infinite width), but where the Euclidean norm of the weights is bounded, including precisely characterizing which functions can be realized with finite norm. This was settled for univariate univariate functions in Savarese et al. (2019), where it was shown that the required norm is determined by the L1-norm of the second derivative of the function. We extend the characterization to multivariate functions (i.e., networks with d input units), relating the required norm to the L1-norm of the Radon transform of a (d+1)/2-power Laplacian of the function. This characterization allows us to show that all functions in Sobolev spaces $W^{s,1}(\mathbb{R})$, $s\geq d+1$, can be represented with bounded norm, to calculate the required norm for several specific functions, and to obtain a depth separation result. These results have important implications for understanding generalization performance and the distinction between neural networks and more traditional kernel learning.