 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACDC: Autoregressive Coherent Multimodal Generation using Diffusion Correction
Paper and Code


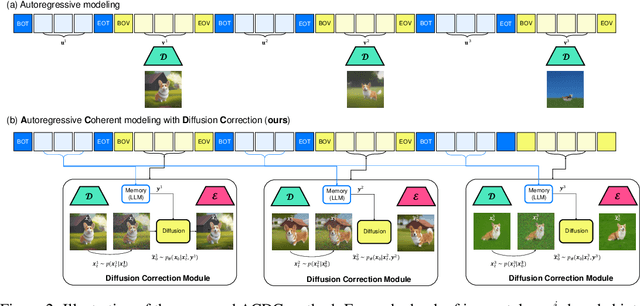
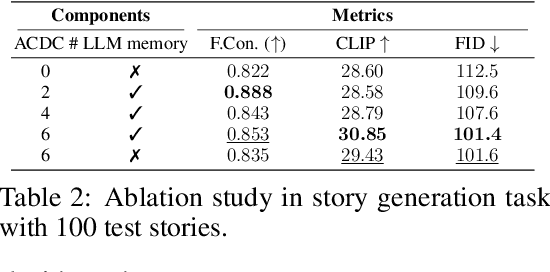
Autoregressive models (ARMs) and diffusion models (DMs) represent two leading paradigms in generative modeling, each excelling in distinct areas: ARMs in global context modeling and long-sequence generation, and DMs in generating high-quality local contexts, especially for continuous data such as images and short videos. However, ARMs often suffer from exponential error accumulation over long sequences, leading to physically implausible results, while DMs are limited by their local context generation capabilities. In this work, we introduce Autoregressive Coherent multimodal generation with Diffusion Correction (ACDC), a zero-shot approach that combines the strengths of both ARMs and DMs at the inference stage without the need for additional fine-tuning. ACDC leverages ARMs for global context generation and memory-conditioned DMs for local correction, ensuring high-quality outputs by correcting artifacts in generated multimodal tokens. In particular, we propose a memory module based on large language models (LLMs) that dynamically adjusts the conditioning texts for the DMs, preserving crucial global context information. Our experiments on multimodal tasks, including coherent multi-frame story generation and autoregressive video generation, demonstrate that ACDC effectively mitigates the accumulation of errors and significantly enhances the quality of generated outputs, achieving superior performance while remaining agnostic to specific ARM and DM architectures. Project page: https://acdc2025.github.io/