 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree$^2$Guide: Gradient-Free Path Integral Control for Enhancing Text-to-Video Generation with Large Vision-Language Models
Nov 26, 2024
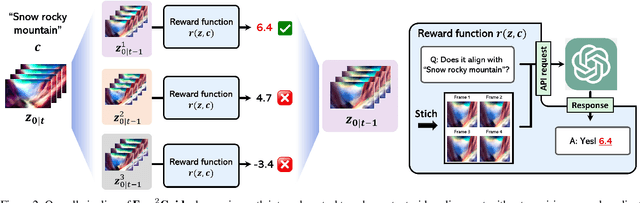
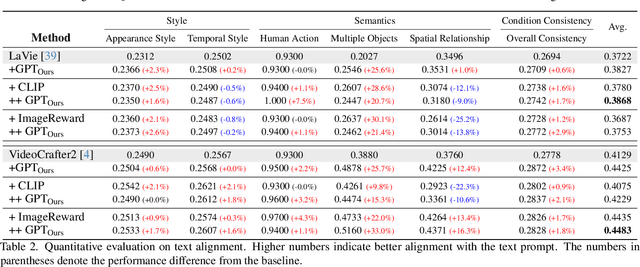

Diffusion models have achieved impressive results in generative tasks like text-to-image (T2I) and text-to-video (T2V) synthesis. However, achieving accurate text alignment in T2V generation remains challenging due to the complex temporal dependency across frames. Existing reinforcement learning (RL)-based approaches to enhance text alignment often require differentiable reward functions or are constrained to limited prompts, hindering their scalability and applicability. In this paper, we propose Free$^2$Guide, a novel gradient-free framework for aligning generated videos with text prompts without requiring additional model training. Leveraging principles from path integral control, Free$^2$Guide approximates guidance for diffusion models using non-differentiable reward functions, thereby enabling the integration of powerful black-box Large Vision-Language Models (LVLMs) as reward model. Additionally, our framework supports the flexible ensembling of multiple reward models, including large-scale image-based models, to synergistically enhance alignment without incurring substantial computational overhead. We demonstrate that Free$^2$Guide significantly improves text alignment across various dimensions and enhances the overall quality of generated videos.
VideoGuide: Improving Video Diffusion Models without Training Through a Teacher's Guide
Oct 06, 2024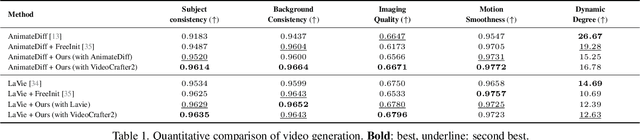
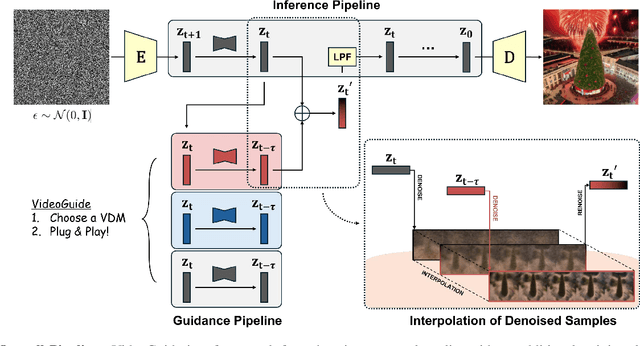


Text-to-image (T2I) diffusion models have revolutionized visual content creation, but extending these capabilities to text-to-video (T2V) generation remains a challenge, particularly in preserving temporal consistency. Existing methods that aim to improve consistency often cause trade-offs such as reduced imaging quality and impractical computational time. To address these issues we introduce VideoGuide, a novel framework that enhances the temporal consistency of pretrained T2V models without the need for additional training or fine-tuning. Instead, VideoGuide leverages any pretrained video diffusion model (VDM) or itself as a guide during the early stages of inference, improving temporal quality by interpolating the guiding model's denoised samples into the sampling model's denoising process. The proposed method brings about significant improvement in temporal consistency and image fidelity, providing a cost-effective and practical solution that synergizes the strengths of various video diffusion models. Furthermore, we demonstrate prior distillation, revealing that base models can achieve enhanced text coherence by utilizing the superior data prior of the guiding model through the proposed method. Project Page: http://videoguide2025.github.io/