 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree$^2$Guide: Gradient-Free Path Integral Control for Enhancing Text-to-Video Generation with Large Vision-Language Models
Paper and Code
Nov 26, 2024
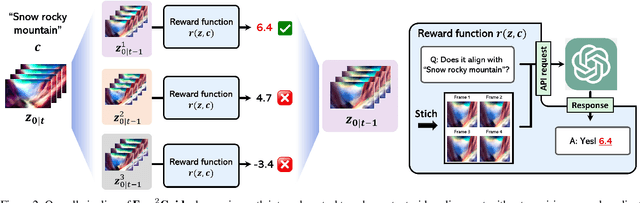
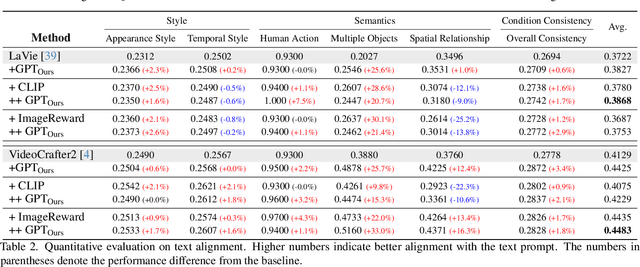

Diffusion models have achieved impressive results in generative tasks like text-to-image (T2I) and text-to-video (T2V) synthesis. However, achieving accurate text alignment in T2V generation remains challenging due to the complex temporal dependency across frames. Existing reinforcement learning (RL)-based approaches to enhance text alignment often require differentiable reward functions or are constrained to limited prompts, hindering their scalability and applicability. In this paper, we propose Free$^2$Guide, a novel gradient-free framework for aligning generated videos with text prompts without requiring additional model training. Leveraging principles from path integral control, Free$^2$Guide approximates guidance for diffusion models using non-differentiable reward functions, thereby enabling the integration of powerful black-box Large Vision-Language Models (LVLMs) as reward model. Additionally, our framework supports the flexible ensembling of multiple reward models, including large-scale image-based models, to synergistically enhance alignment without incurring substantial computational overhead. We demonstrate that Free$^2$Guide significantly improves text alignment across various dimensions and enhances the overall quality of generated videos.