 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosine Similarity Knowledge Distillation for Individual Class Information Transfer
Paper and Code
Nov 24, 2023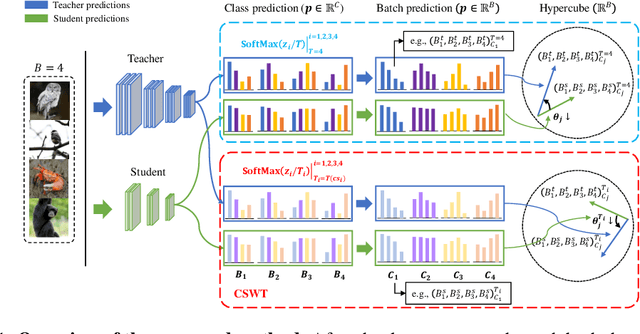

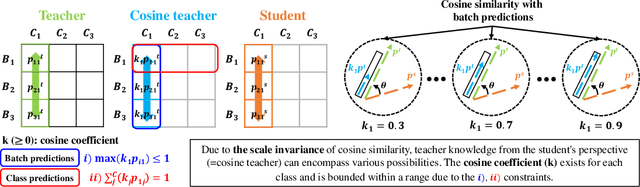

Previous logits-based Knowledge Distillation (KD) have utilized predictions about multiple categories within each sample (i.e., class predictions) and have employed Kullback-Leibler (KL) divergence to reduce the discrepancy between the student and teacher predictions. Despite the proliferation of KD techniques, the student model continues to fall short of achieving a similar level as teachers. In response, we introduce a novel and effective KD method capable of achieving results on par with or superior to the teacher models performance. We utilize teacher and student predictions about multiple samples for each category (i.e., batch predictions) and apply cosine similarity, a commonly used technique in Natural Language Processing (NLP) for measuring the resemblance between text embeddings. This metric's inherent scale-invariance property, which relies solely on vector direction and not magnitude, allows the student to dynamically learn from the teacher's knowledge, rather than being bound by a fixed distribution of the teacher's knowledge. Furthermore, we propose a method called cosine similarity weighted temperature (CSWT) to improve the performance. CSWT reduces the temperature scaling in KD when the cosine similarity between the student and teacher models is high, and conversely, it increases the temperature scaling when the cosine similarity is low. This adjustment optimizes the transfer of information from the teacher to the student model. Extensive experimental results show that our proposed method serves as a viable alternative to existing methods. We anticipate that this approach will offer valuable insights for future research on model compression.