 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised learning of object pose estimation using keypoint prediction
Feb 19, 2023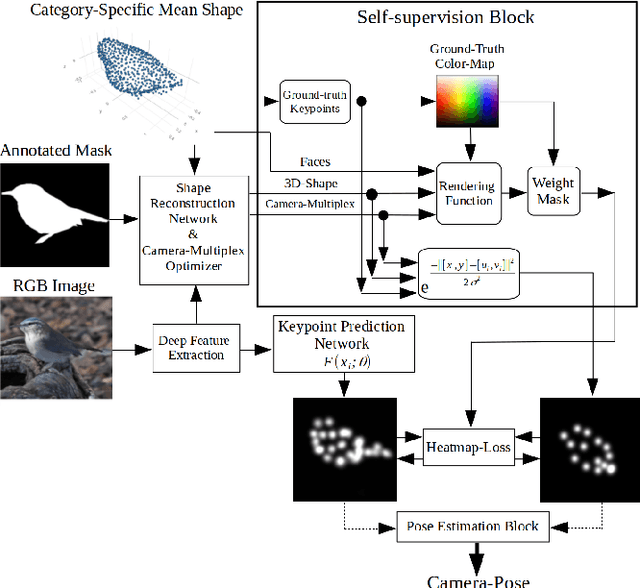



This paper describes recent developments in object specific pose and shape prediction from single images. The main contribution is a new approach to camera pose prediction by self-supervised learning of keypoints corresponding to locations on a category specific deformable shape. We designed a network to generate a proxy ground-truth heatmap from a set of keypoints distributed all over the category-specific mean shape, where each is represented by a unique color on a labeled texture. The proxy ground-truth heatmap is used to train a deep keypoint prediction network, which can be used in online inference. The proposed approach to camera pose prediction show significant improvements when compared with state-of-the-art methods. Our approach to camera pose prediction is used to infer 3D objects from 2D image frames of video sequences online. To train the reconstruction model, it receives only a silhouette mask from a single frame of a video sequence in every training step and a category-specific mean object shape. We conducted experiments using three different datasets representing the bird category: the CUB [51] image dataset, YouTubeVos and the Davis video datasets. The network is trained on the CUB dataset and tested on all three datasets. The online experiments are demonstrated on YouTubeVos and Davis [56] video sequences using a network trained on the CUB training set.
Registration Loss Learning for Deep Probabilistic Point Set Registration
Nov 04, 2020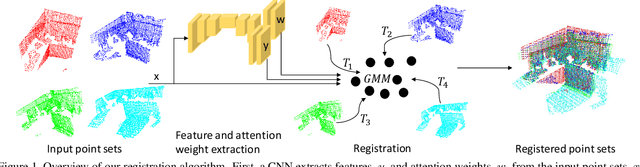
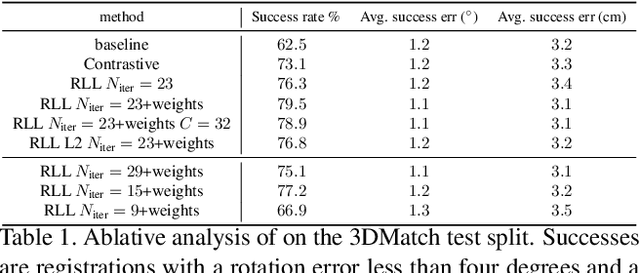
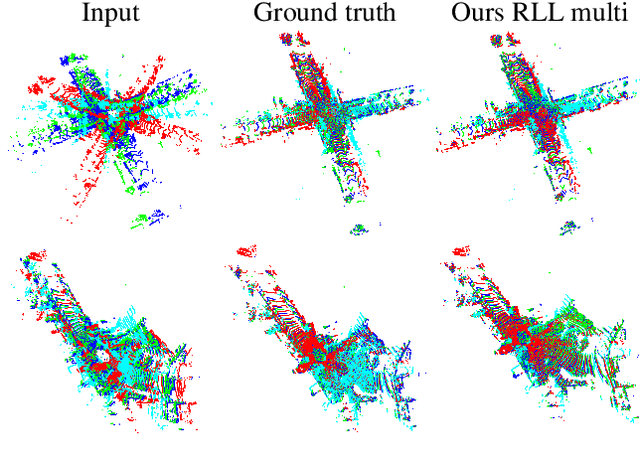
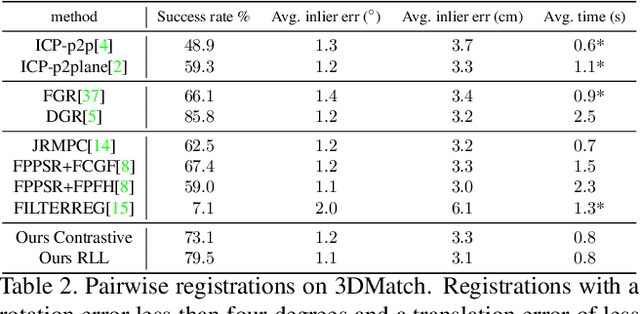
Probabilistic methods for point set registration have interesting theoretical properties, such as linear complexity in the number of used points, and they easily generalize to joint registration of multiple point sets. In this work, we improve their recognition performance to match state of the art. This is done by incorporating learned features, by adding a von Mises-Fisher feature model in each mixture component, and by using learned attention weights. We learn these jointly using a registration loss learning strategy (RLL) that directly uses the registration error as a loss, by back-propagating through the registration iterations. This is possible as the probabilistic registration is fully differentiable, and the result is a learning framework that is truly end-to-end. We perform extensive experiments on the 3DMatch and Kitti datasets. The experiments demonstrate that our approach benefits significantly from the integration of the learned features and our learning strategy, outperforming the state-of-the-art on Kitti. Code is available at https://github.com/felja633/RLLReg.
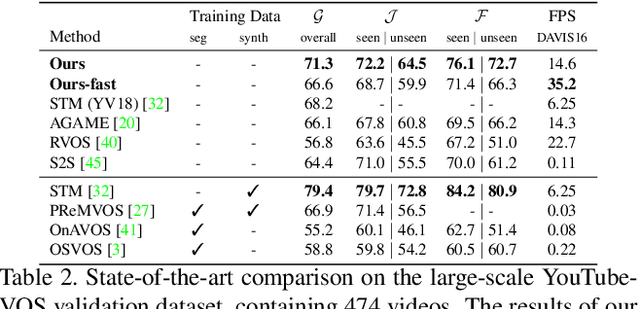
Learning What to Learn for Video Object Segmentation
May 01, 2020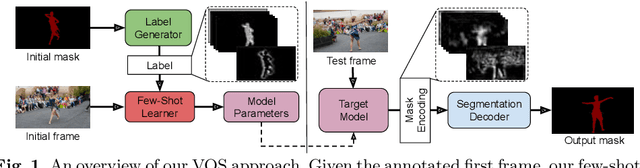

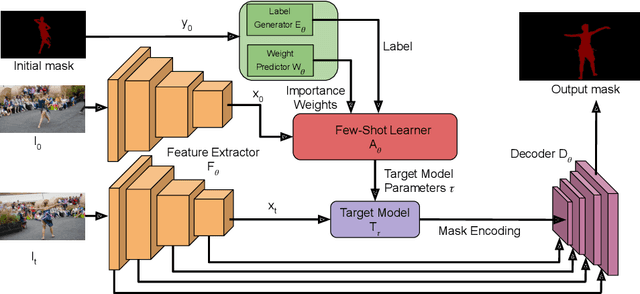
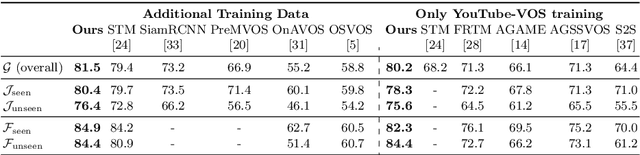
Video object segmentation (VOS) is a highly challenging problem, since the target object is only defined during inference with a given first-frame reference mask. The problem of how to capture and utilize this limited target information remains a fundamental research question. We address this by introducing an end-to-end trainable VOS architecture that integrates a differentiable few-shot learning module. This internal learner is designed to predict a powerful parametric model of the target by minimizing a segmentation error in the first frame. We further go beyond standard few-shot learning techniques by learning what the few-shot learner should learn. This allows us to achieve a rich internal representation of the target in the current frame, significantly increasing the segmentation accuracy of our approach. We perform extensive experiments on multiple benchmarks. Our approach sets a new state-of-the-art on the large-scale YouTube-VOS 2018 dataset by achieving an overall score of 81.5, corresponding to a 2.6% relative improvement over the previous best result.
Learning Fast and Robust Target Models for Video Object Segmentation
Feb 27, 2020

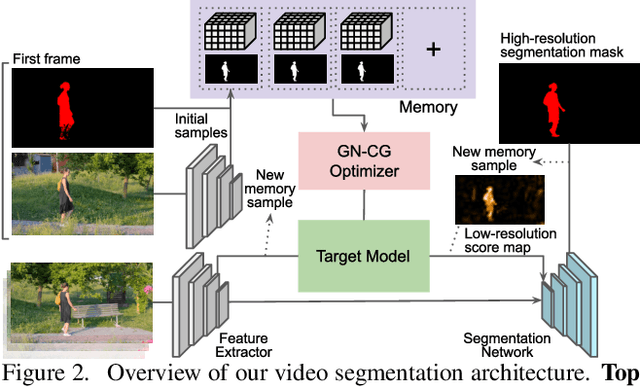
Video object segmentation (VOS) is a highly challenging problem since the initial mask, defining the target object, is only given at test-time. The main difficulty is to effectively handle appearance changes and similar background objects, while maintaining accurate segmentation. Most previous approaches fine-tune segmentation networks on the first frame, resulting in impractical frame-rates and risk of overfitting. More recent methods integrate generative target appearance models, but either achieve limited robustness or require large amounts of training data. We propose a novel VOS architecture consisting of two network components. The target appearance model consists of a light-weight module, learned during the inference stage using fast optimization techniques to predict a coarse but robust target segmentation. The segmentation model is exclusively trained offline, designed to process the coarse scores into high quality segmentation masks. Our method is fast, easily trainable and remains is highly effective in cases of limited training data. We perform extensive experiments on the challenging YouTube-VOS and DAVIS datasets. Our network achieves favorable performance, while operating at significantly higher frame-rates compared to state-of-the-art. Code is available at https://github.com/andr345/frtm-vos.
Discriminative Online Learning for Fast Video Object Segmentation
Apr 18, 2019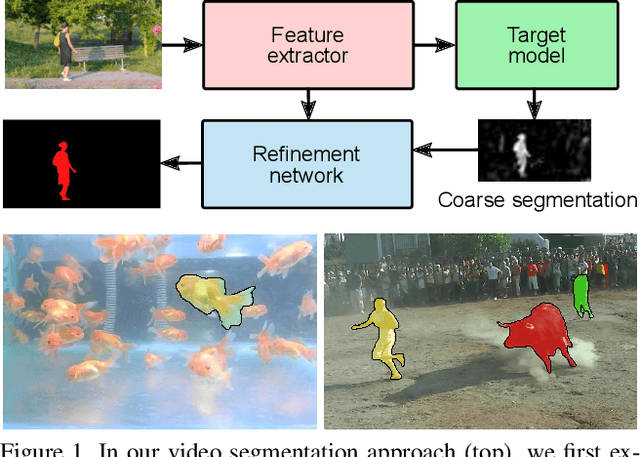

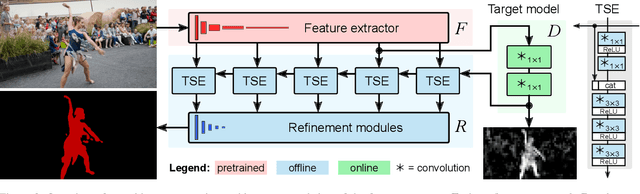
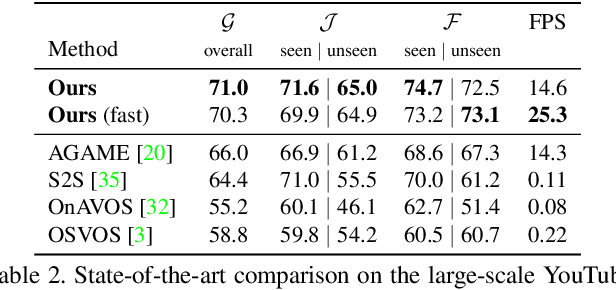
We address the highly challenging problem of video object segmentation. Given only the initial mask, the task is to segment the target in the subsequent frames. In order to effectively handle appearance changes and similar background objects, a robust representation of the target is required. Previous approaches either rely on fine-tuning a segmentation network on the first frame, or employ generative appearance models. Although partially successful, these methods often suffer from impractically low frame rates or unsatisfactory robustness. We propose a novel approach, based on a dedicated target appearance model that is exclusively learned online to discriminate between the target and background image regions. Importantly, we design a specialized loss and customized optimization techniques to enable highly efficient online training. Our light-weight target model is integrated into a carefully designed segmentation network, trained offline to enhance the predictions generated by the target model. Extensive experiments are performed on three datasets. Our approach achieves an overall score of over 70 on YouTube-VOS, while operating at 25 frames per second.
Density Adaptive Point Set Registration
Oct 23, 2018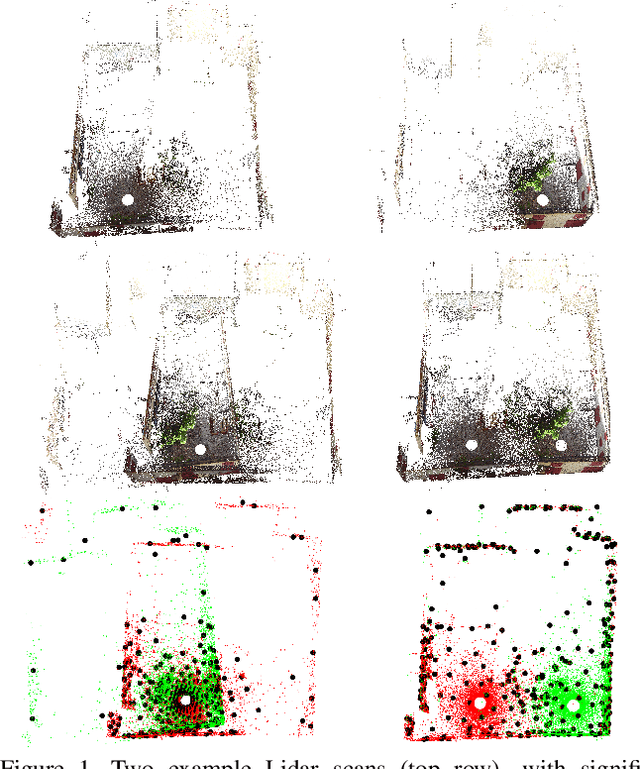
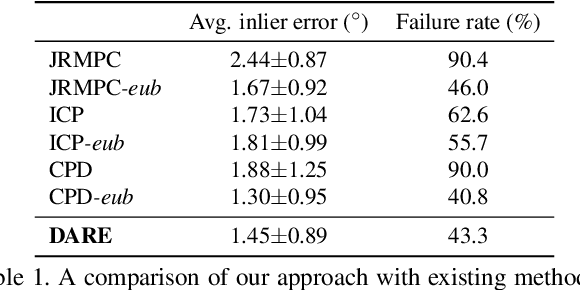
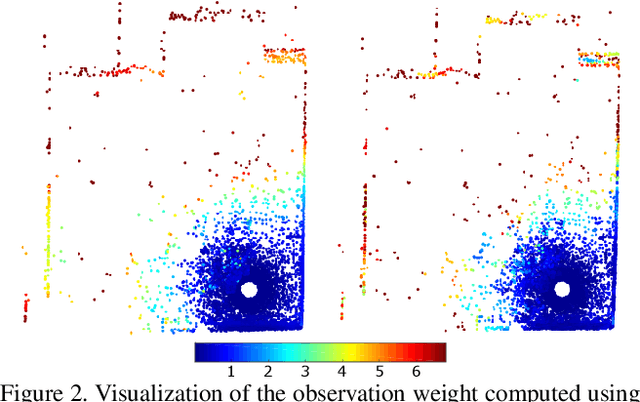
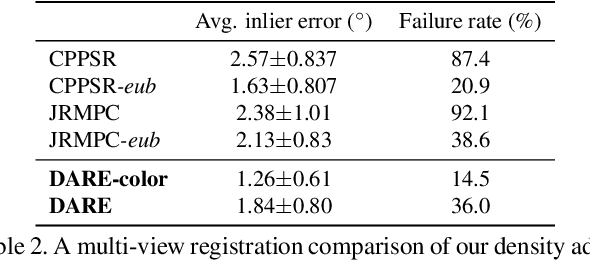
Probabilistic methods for point set registration have demonstrated competitive results in recent years. These techniques estimate a probability distribution model of the point clouds. While such a representation has shown promise, it is highly sensitive to variations in the density of 3D points. This fundamental problem is primarily caused by changes in the sensor location across point sets. We revisit the foundations of the probabilistic registration paradigm. Contrary to previous works, we model the underlying structure of the scene as a latent probability distribution, and thereby induce invariance to point set density changes. Both the probabilistic model of the scene and the registration parameters are inferred by minimizing the Kullback-Leibler divergence in an Expectation Maximization based framework. Our density-adaptive registration successfully handles severe density variations commonly encountered in terrestrial Lidar applications. We perform extensive experiments on several challenging real-world Lidar datasets. The results demonstrate that our approach outperforms state-of-the-art probabilistic methods for multi-view registration, without the need of re-sampling. Code is available at https://github.com/felja633/DARE.
* CVPR 2018 (Oral)
Deep Projective 3D Semantic Segmentation
May 09, 2017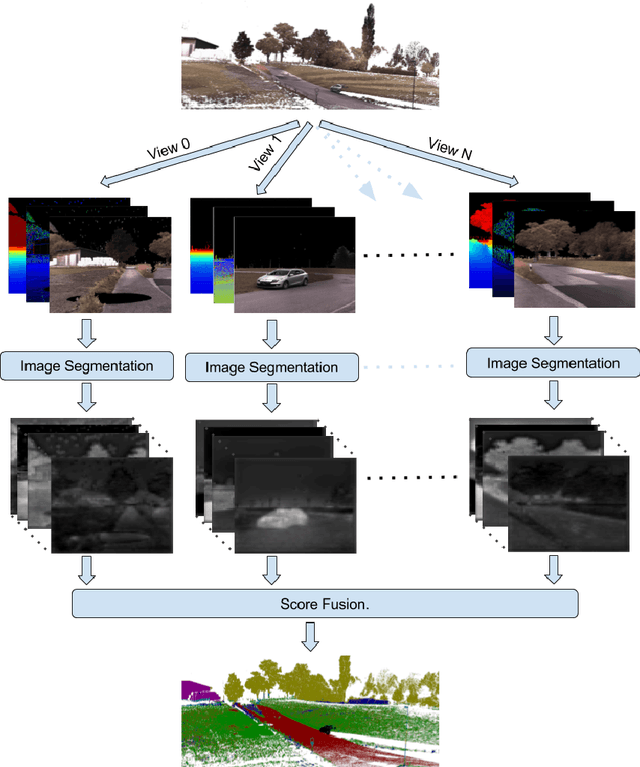


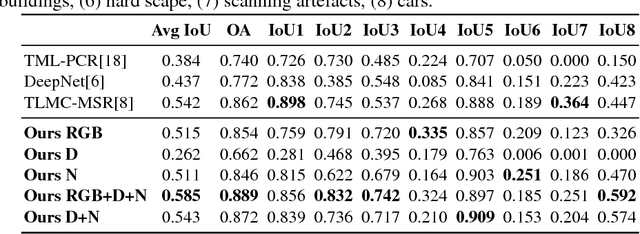
Semantic segmentation of 3D point clouds is a challenging problem with numerous real-world applications. While deep learning has revolutionized the field of image semantic segmentation, its impact on point cloud data has been limited so far. Recent attempts, based on 3D deep learning approaches (3D-CNNs), have achieved below-expected results. Such methods require voxelizations of the underlying point cloud data, leading to decreased spatial resolution and increased memory consumption. Additionally, 3D-CNNs greatly suffer from the limited availability of annotated datasets. In this paper, we propose an alternative framework that avoids the limitations of 3D-CNNs. Instead of directly solving the problem in 3D, we first project the point cloud onto a set of synthetic 2D-images. These images are then used as input to a 2D-CNN, designed for semantic segmentation. Finally, the obtained prediction scores are re-projected to the point cloud to obtain the segmentation results. We further investigate the impact of multiple modalities, such as color, depth and surface normals, in a multi-stream network architecture. Experiments are performed on the recent Semantic3D dataset. Our approach sets a new state-of-the-art by achieving a relative gain of 7.9 %, compared to the previous best approach.
Efficient Multi-Frequency Phase Unwrapping using Kernel Density Estimation
Aug 18, 2016
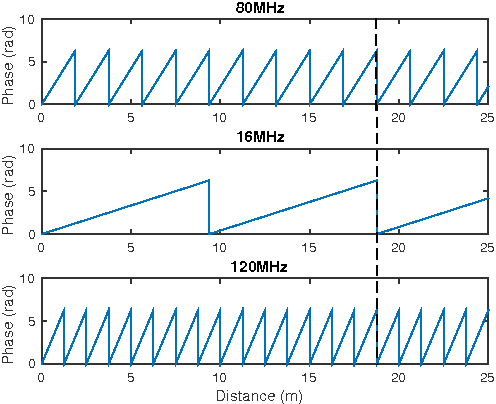

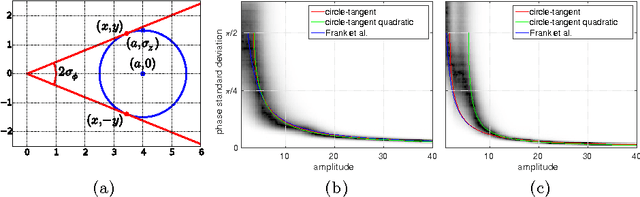
In this paper we introduce an efficient method to unwrap multi-frequency phase estimates for time-of-flight ranging. The algorithm generates multiple depth hypotheses and uses a spatial kernel density estimate (KDE) to rank them. The confidence produced by the KDE is also an effective means to detect outliers. We also introduce a new closed-form expression for phase noise prediction, that better fits real data. The method is applied to depth decoding for the Kinect v2 sensor, and compared to the Microsoft Kinect SDK and to the open source driver libfreenect2. The intended Kinect v2 use case is scenes with less than 8m range, and for such cases we observe consistent improvements, while maintaining real-time performance. When extending the depth range to the maximal value of 8.75m, we get about 52% more valid measurements than libfreenect2. The effect is that the sensor can now be used in large depth scenes, where it was previously not a good choice. Code and supplementary material are available at http://www.cvl.isy.liu.se/research/datasets/kinect2-dataset.