 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminative Online Learning for Fast Video Object Segmentation
Paper and Code
Apr 18, 2019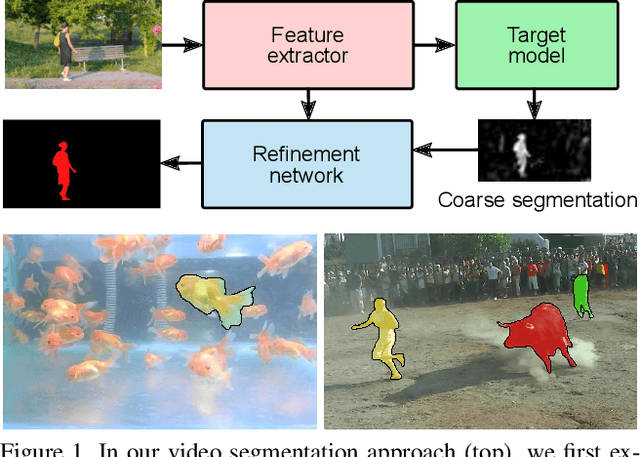

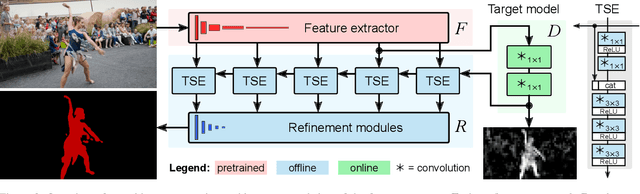
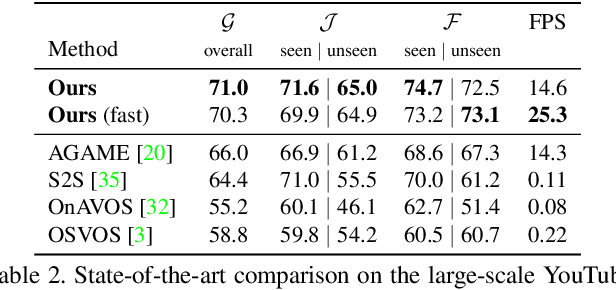
We address the highly challenging problem of video object segmentation. Given only the initial mask, the task is to segment the target in the subsequent frames. In order to effectively handle appearance changes and similar background objects, a robust representation of the target is required. Previous approaches either rely on fine-tuning a segmentation network on the first frame, or employ generative appearance models. Although partially successful, these methods often suffer from impractically low frame rates or unsatisfactory robustness. We propose a novel approach, based on a dedicated target appearance model that is exclusively learned online to discriminate between the target and background image regions. Importantly, we design a specialized loss and customized optimization techniques to enable highly efficient online training. Our light-weight target model is integrated into a carefully designed segmentation network, trained offline to enhance the predictions generated by the target model. Extensive experiments are performed on three datasets. Our approach achieves an overall score of over 70 on YouTube-VOS, while operating at 25 frames per second.