 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnow Your Surroundings: Exploiting Scene Information for Object Tracking
Paper and Code
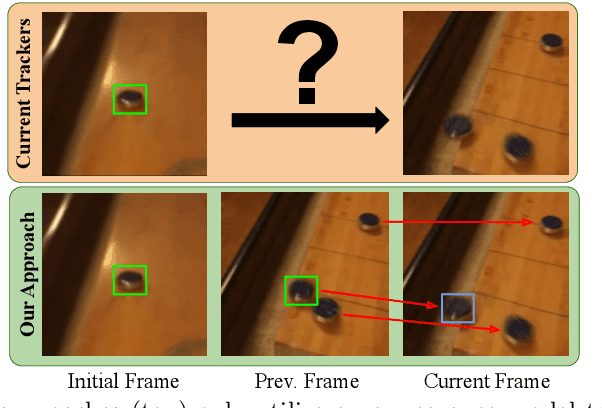

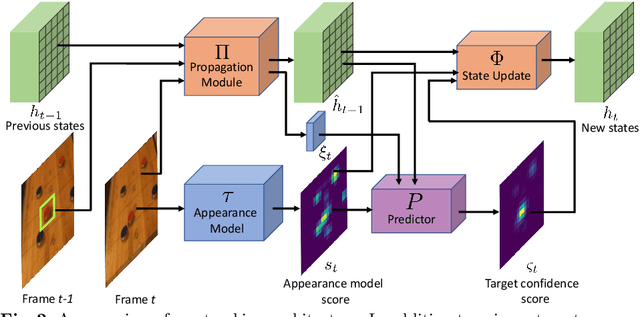

Current state-of-the-art trackers only rely on a target appearance model in order to localize the object in each frame. Such approaches are however prone to fail in case of e.g. fast appearance changes or presence of distractor objects, where a target appearance model alone is insufficient for robust tracking. Having the knowledge about the presence and locations of other objects in the surrounding scene can be highly beneficial in such cases. This scene information can be propagated through the sequence and used to, for instance, explicitly avoid distractor objects and eliminate target candidate regions. In this work, we propose a novel tracking architecture which can utilize scene information for tracking. Our tracker represents such information as dense localized state vectors, which can encode, for example, if the local region is target, background, or distractor. These state vectors are propagated through the sequence and combined with the appearance model output to localize the target. Our network is learned to effectively utilize the scene information by directly maximizing tracking performance on video segments. The proposed approach sets a new state-of-the-art on 3 tracking benchmarks, achieving an AO score of 63.6% on the recent GOT-10k dataset.