 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffSF: Diffusion Models for Scene Flow Estimation
Mar 14, 2024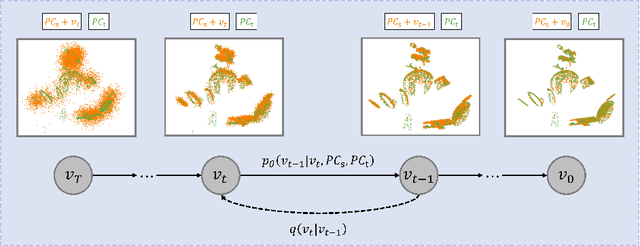
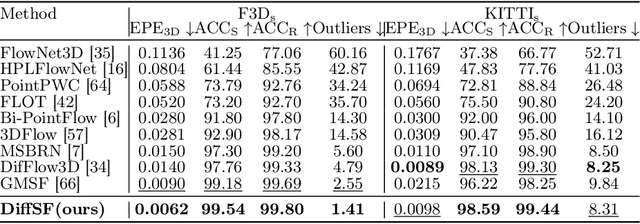
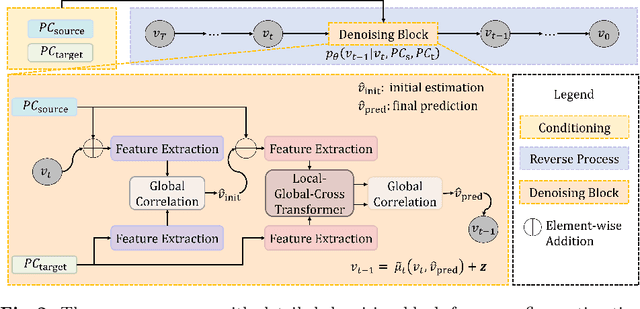
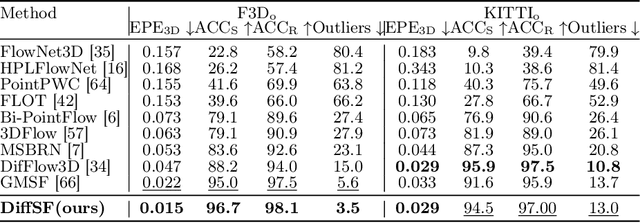
Scene flow estimation is an essential ingredient for a variety of real-world applications, especially for autonomous agents, such as self-driving cars and robots. While recent scene flow estimation approaches achieve a reasonable accuracy, their applicability to real-world systems additionally benefits from a reliability measure. Aiming at improving accuracy while additionally providing an estimate for uncertainty, we propose DiffSF that combines transformer-based scene flow estimation with denoising diffusion models. In the diffusion process, the ground truth scene flow vector field is gradually perturbed by adding Gaussian noise. In the reverse process, starting from randomly sampled Gaussian noise, the scene flow vector field prediction is recovered by conditioning on a source and a target point cloud. We show that the diffusion process greatly increases the robustness of predictions compared to prior approaches resulting in state-of-the-art performance on standard scene flow estimation benchmarks. Moreover, by sampling multiple times with different initial states, the denoising process predicts multiple hypotheses, which enables measuring the output uncertainty, allowing our approach to detect a majority of the inaccurate predictions. The code is available at https://github.com/ZhangYushan3/DiffSF.
GMSF: Global Matching Scene Flow
May 27, 2023We tackle the task of scene flow estimation from point clouds. Given a source and a target point cloud, the objective is to estimate a translation from each point in the source point cloud to the target, resulting in a 3D motion vector field. Previous dominant scene flow estimation methods require complicated coarse-to-fine or recurrent architectures as a multi-stage refinement. In contrast, we propose a significantly simpler single-scale one-shot global matching to address the problem. Our key finding is that reliable feature similarity between point pairs is essential and sufficient to estimate accurate scene flow. To this end, we propose to decompose the feature extraction step via a hybrid local-global-cross transformer architecture which is crucial to accurate and robust feature representations. Extensive experiments show that GMSF sets a new state-of-the-art on multiple scene flow estimation benchmarks. On FlyingThings3D, with the presence of occlusion points, GMSF reduces the outlier percentage from the previous best performance of 27.4% to 11.7%. On KITTI Scene Flow, without any fine-tuning, our proposed method shows state-of-the-art performance.
Flow-guided Semi-supervised Video Object Segmentation
Jan 25, 2023We propose an optical flow-guided approach for semi-supervised video object segmentation. Optical flow is usually exploited as additional guidance information in unsupervised video object segmentation. However, its relevance in semi-supervised video object segmentation has not been fully explored. In this work, we follow an encoder-decoder approach to address the segmentation task. A model to extract the combined information from optical flow and the image is proposed, which is then used as input to the target model and the decoder network. Unlike previous methods where concatenation is used to integrate information from image data and optical flow, a simple yet effective attention mechanism is exploited in our work. Experiments on DAVIS 2017 and YouTube-VOS 2019 show that by integrating the information extracted from optical flow into the original image branch results in a strong performance gain and our method achieves state-of-the-art performance.