 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoMa v2: Harder Better Faster Denser Feature Matching
Nov 19, 2025Dense feature matching aims to estimate all correspondences between two images of a 3D scene and has recently been established as the gold-standard due to its high accuracy and robustness. However, existing dense matchers still fail or perform poorly for many hard real-world scenarios, and high-precision models are often slow, limiting their applicability. In this paper, we attack these weaknesses on a wide front through a series of systematic improvements that together yield a significantly better model. In particular, we construct a novel matching architecture and loss, which, combined with a curated diverse training distribution, enables our model to solve many complex matching tasks. We further make training faster through a decoupled two-stage matching-then-refinement pipeline, and at the same time, significantly reduce refinement memory usage through a custom CUDA kernel. Finally, we leverage the recent DINOv3 foundation model along with multiple other insights to make the model more robust and unbiased. In our extensive set of experiments we show that the resulting novel matcher sets a new state-of-the-art, being significantly more accurate than its predecessors. Code is available at https://github.com/Parskatt/romav2
Radially Distorted Homographies, Revisited
Aug 28, 2025Homographies are among the most prevalent transformations occurring in geometric computer vision and projective geometry, and homography estimation is consequently a crucial step in a wide assortment of computer vision tasks. When working with real images, which are often afflicted with geometric distortions caused by the camera lens, it may be necessary to determine both the homography and the lens distortion-particularly the radial component, called radial distortion-simultaneously to obtain anything resembling useful estimates. When considering a homography with radial distortion between two images, there are three conceptually distinct configurations for the radial distortion; (i) distortion in only one image, (ii) identical distortion in the two images, and (iii) independent distortion in the two images. While these cases have been addressed separately in the past, the present paper provides a novel and unified approach to solve all three cases. We demonstrate how the proposed approach can be used to construct new fast, stable, and accurate minimal solvers for radially distorted homographies. In all three cases, our proposed solvers are faster than the existing state-of-the-art solvers while maintaining similar accuracy. The solvers are tested on well-established benchmarks including images taken with fisheye cameras. The source code for our solvers will be made available in the event our paper is accepted for publication.
Stronger ViTs With Octic Equivariance
May 21, 2025Recent efforts at scaling computer vision models have established Vision Transformers (ViTs) as the leading architecture. ViTs incorporate weight sharing over image patches as an important inductive bias. In this work, we show that ViTs benefit from incorporating equivariance under the octic group, i.e., reflections and 90-degree rotations, as a further inductive bias. We develop new architectures, octic ViTs, that use octic-equivariant layers and put them to the test on both supervised and self-supervised learning. Through extensive experiments on DeiT-III and DINOv2 training on ImageNet-1K, we show that octic ViTs yield more computationally efficient networks while also improving performance. In particular, we achieve approximately 40% reduction in FLOPs for ViT-H while simultaneously improving both classification and segmentation results.
FACT: Multinomial Misalignment Classification for Point Cloud Registration
Apr 09, 2025



We present FACT, a method for predicting alignment quality (i.e., registration error) of registered lidar point cloud pairs. This is useful e.g. for quality assurance of large, automatically registered 3D models. FACT extracts local features from a registered pair and processes them with a point transformer-based network to predict a misalignment class. We generalize prior work that study binary alignment classification of registration errors, by recasting it as multinomial misalignment classification. To achieve this, we introduce a custom regression-by-classification loss function that combines the cross-entropy and Wasserstein losses, and demonstrate that it outperforms both direct regression and prior binary classification. FACT successfully classifies point-cloud pairs registered with both the classical ICP and GeoTransformer, while other choices, such as standard point-cloud-quality metrics and registration residuals are shown to be poor choices for predicting misalignment. On a synthetically perturbed point-cloud task introduced by the CorAl method, we show that FACT achieves substantially better performance than CorAl. Finally, we demonstrate how FACT can assist experts in correcting misaligned point-cloud maps. Our code is available at https://github.com/LudvigDillen/FACT_for_PCMC.
Less Biased Noise Scale Estimation for Threshold-Robust RANSAC
Mar 17, 2025
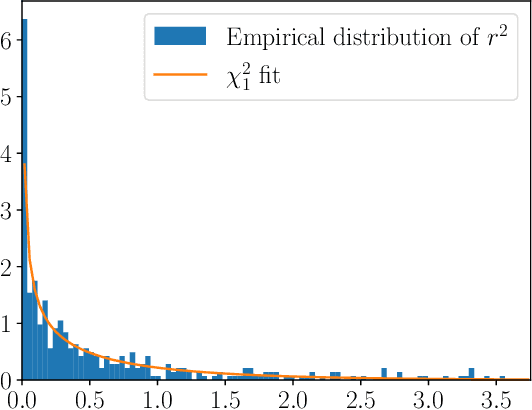

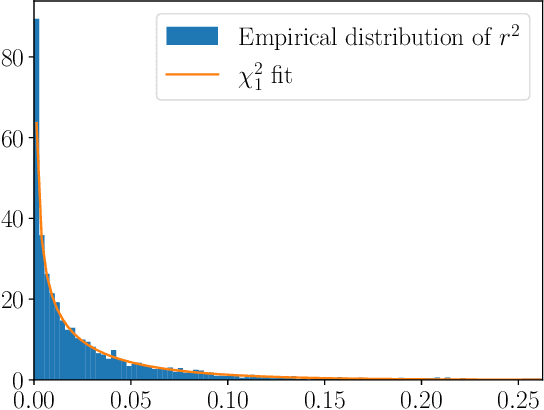
The gold-standard for robustly estimating relative pose through image matching is RANSAC. While RANSAC is powerful, it requires setting the inlier threshold that determines whether the error of a correspondence under an estimated model is sufficiently small to be included in its consensus set. Setting this threshold is typically done by hand, and is difficult to tune without a access to ground truth data. Thus, a method capable of automatically determining the optimal threshold would be desirable. In this paper we revisit inlier noise scale estimation, which is an attractive approach as the inlier noise scale is linear to the optimal threshold. We revisit the noise scale estimation method SIMFIT and find bias in the estimate of the noise scale. In particular, we fix underestimates from using the same data for fitting the model as estimating the inlier noise, and from not taking the threshold itself into account. Secondly, since the optimal threshold within a scene is approximately constant we propose a multi-pair extension of SIMFIT++, by filtering of estimates, which improves results. Our approach yields robust performance across a range of thresholds, shown in Figure 1.
DaD: Distilled Reinforcement Learning for Diverse Keypoint Detection
Mar 11, 2025Keypoints are what enable Structure-from-Motion (SfM) systems to scale to thousands of images. However, designing a keypoint detection objective is a non-trivial task, as SfM is non-differentiable. Typically, an auxiliary objective involving a descriptor is optimized. This however induces a dependency on the descriptor, which is undesirable. In this paper we propose a fully self-supervised and descriptor-free objective for keypoint detection, through reinforcement learning. To ensure training does not degenerate, we leverage a balanced top-K sampling strategy. While this already produces competitive models, we find that two qualitatively different types of detectors emerge, which are only able to detect light and dark keypoints respectively. To remedy this, we train a third detector, DaD, that optimizes the Kullback-Leibler divergence of the pointwise maximum of both light and dark detectors. Our approach significantly improve upon SotA across a range of benchmarks. Code and model weights are publicly available at https://github.com/parskatt/dad
Affine steerers for structured keypoint description
Aug 26, 2024
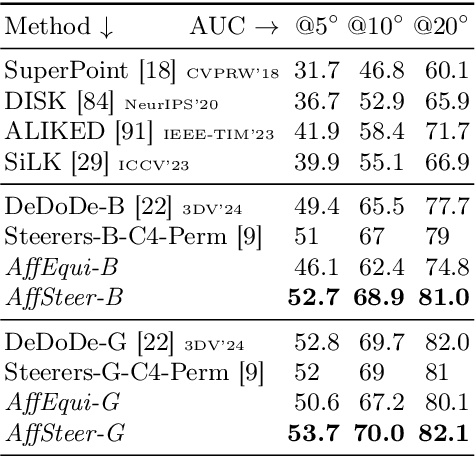
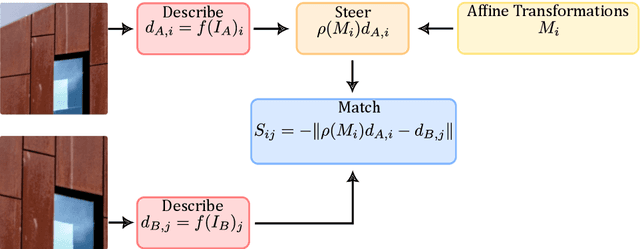

We propose a way to train deep learning based keypoint descriptors that makes them approximately equivariant for locally affine transformations of the image plane. The main idea is to use the representation theory of GL(2) to generalize the recently introduced concept of steerers from rotations to affine transformations. Affine steerers give high control over how keypoint descriptions transform under image transformations. We demonstrate the potential of using this control for image matching. Finally, we propose a way to finetune keypoint descriptors with a set of steerers on upright images and obtain state-of-the-art results on several standard benchmarks. Code will be published at github.com/georg-bn/affine-steerers.
From 2D to 3D: AISG-SLA Visual Localization Challenge
Jul 26, 2024



Research in 3D mapping is crucial for smart city applications, yet the cost of acquiring 3D data often hinders progress. Visual localization, particularly monocular camera position estimation, offers a solution by determining the camera's pose solely through visual cues. However, this task is challenging due to limited data from a single camera. To tackle these challenges, we organized the AISG-SLA Visual Localization Challenge (VLC) at IJCAI 2023 to explore how AI can accurately extract camera pose data from 2D images in 3D space. The challenge attracted over 300 participants worldwide, forming 50+ teams. Winning teams achieved high accuracy in pose estimation using images from a car-mounted camera with low frame rates. The VLC dataset is available for research purposes upon request via vlc-dataset@aisingapore.org.
DeDoDe v2: Analyzing and Improving the DeDoDe Keypoint Detector
Apr 13, 2024



In this paper, we analyze and improve into the recently proposed DeDoDe keypoint detector. We focus our analysis on some key issues. First, we find that DeDoDe keypoints tend to cluster together, which we fix by performing non-max suppression on the target distribution of the detector during training. Second, we address issues related to data augmentation. In particular, the DeDoDe detector is sensitive to large rotations. We fix this by including 90-degree rotations as well as horizontal flips. Finally, the decoupled nature of the DeDoDe detector makes evaluation of downstream usefulness problematic. We fix this by matching the keypoints with a pretrained dense matcher (RoMa) and evaluating two-view pose estimates. We find that the original long training is detrimental to performance, and therefore propose a much shorter training schedule. We integrate all these improvements into our proposed detector DeDoDe v2 and evaluate it with the original DeDoDe descriptor on the MegaDepth-1500 and IMC2022 benchmarks. Our proposed detector significantly increases pose estimation results, notably from 75.9 to 78.3 mAA on the IMC2022 challenge. Code and weights are available at https://github.com/Parskatt/DeDoDe
Steerers: A framework for rotation equivariant keypoint descriptors
Dec 04, 2023



Image keypoint descriptions that are discriminative and matchable over large changes in viewpoint are vital for 3D reconstruction. However, descriptions output by learned descriptors are typically not robust to camera rotation. While they can be made more robust by, e.g., data augmentation, this degrades performance on upright images. Another approach is test-time augmentation, which incurs a significant increase in runtime. We instead learn a linear transform in description space that encodes rotations of the input image. We call this linear transform a steerer since it allows us to transform the descriptions as if the image was rotated. From representation theory we know all possible steerers for the rotation group. Steerers can be optimized (A) given a fixed descriptor, (B) jointly with a descriptor or (C) we can optimize a descriptor given a fixed steerer. We perform experiments in all of these three settings and obtain state-of-the-art results on the rotation invariant image matching benchmarks AIMS and Roto-360. We publish code and model weights at github.com/georg-bn/rotation-steerers.