 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark Dataset for Catalysis on 2D MXenes
May 30, 2026Merging first-principles calculations with machine learning (ML), we aim to accelerate the exploration of catalytic behaviour in novel materials. We focus on two-dimensional (2D) Ti$_2$CT$_y$ MXenes, whose versatile surface chemistry makes them particularly compelling candidates for catalysis. Resolving their composition and structure under realistic conditions exceeds the reach of standard density functional theory (DFT) due to computational cost. To address this challenge, we generate a comprehensive dataset of 50,000 DFT calculations for training and 10,000 for testing, encompassing both Ti$_2$CT$_y$ MXene configurations and molecular systems, along with an additional test dataset with 1000 genuinely new, larger systems to investigate how well models generalise. We train and validate widely used and competitive machine learning interatomic potential (MLIP) models, including EquiformerV2, MACE, MatRIS, and UPET, that accurately predict atomic forces and formation energies -- quantities that DFT must repeatedly compute for structural and catalytic investigations -- for these 2D materials. This combined DFT-ML framework achieves computational acceleration on the order of approximately $1-4 \cdot 10^3$ (on a CPU) while maintaining desired-level accuracy (approximately +/- $10$ meV/A for forces and approximately +/- $1$ meV for per-atom energies), paving the way for more efficient investigations of MXene catalytic behaviour. Moreover, we perform an extensive qualitative evaluation of the trained models, showcasing the importance of comprehensive simulation-based comparison beyond benchmark metrics. The dataset and the trained models with the code are available at https://huggingface.co/datasets/CatalystAnonymous/catalyst_mxenes.
QuaMo: Quaternion Motions for Vision-based 3D Human Kinematics Capture
Jan 27, 2026Vision-based 3D human motion capture from videos remains a challenge in computer vision. Traditional 3D pose estimation approaches often ignore the temporal consistency between frames, causing implausible and jittery motion. The emerging field of kinematics-based 3D motion capture addresses these issues by estimating the temporal transitioning between poses instead. A major drawback in current kinematics approaches is their reliance on Euler angles. Despite their simplicity, Euler angles suffer from discontinuity that leads to unstable motion reconstructions, especially in online settings where trajectory refinement is unavailable. Contrarily, quaternions have no discontinuity and can produce continuous transitions between poses. In this paper, we propose QuaMo, a novel Quaternion Motions method using quaternion differential equations (QDE) for human kinematics capture. We utilize the state-space model, an effective system for describing real-time kinematics estimations, with quaternion state and the QDE describing quaternion velocity. The corresponding angular acceleration is computed from a meta-PD controller with a novel acceleration enhancement that adaptively regulates the control signals as the human quickly changes to a new pose. Unlike previous work, our QDE is solved under the quaternion unit-sphere constraint that results in more accurate estimations. Experimental results show that our novel formulation of the QDE with acceleration enhancement accurately estimates 3D human kinematics with no discontinuity and minimal implausibilities. QuaMo outperforms comparable state-of-the-art methods on multiple datasets, namely Human3.6M, Fit3D, SportsPose and AIST. The code is available at https://github.com/cuongle1206/QuaMo
On the Role of Rotation Equivariance in Monocular 3D Human Pose Estimation
Jan 20, 2026Estimating 3D from 2D is one of the central tasks in computer vision. In this work, we consider the monocular setting, i.e. single-view input, for 3D human pose estimation (HPE). Here, the task is to predict a 3D point set of human skeletal joints from a single 2D input image. While by definition this is an ill-posed problem, recent work has presented methods that solve it with up to several-centimetre error. Typically, these methods employ a two-step approach, where the first step is to detect the 2D skeletal joints in the input image, followed by the step of 2D-to-3D lifting. We find that common lifting models fail when encountering a rotated input. We argue that learning a single human pose along with its in-plane rotations is considerably easier and more geometrically grounded than directly learning a point-to-point mapping. Furthermore, our intuition is that endowing the model with the notion of rotation equivariance without explicitly constraining its parameter space should lead to a more straightforward learning process than one with equivariance by design. Utilising the common HPE benchmarks, we confirm that the 2D rotation equivariance per se improves the model performance on human poses akin to rotations in the image plane, and can be efficiently and straightforwardly learned by augmentation, outperforming state-of-the-art equivariant-by-design methods.
ICML 2023 Topological Deep Learning Challenge : Design and Results
Oct 02, 2023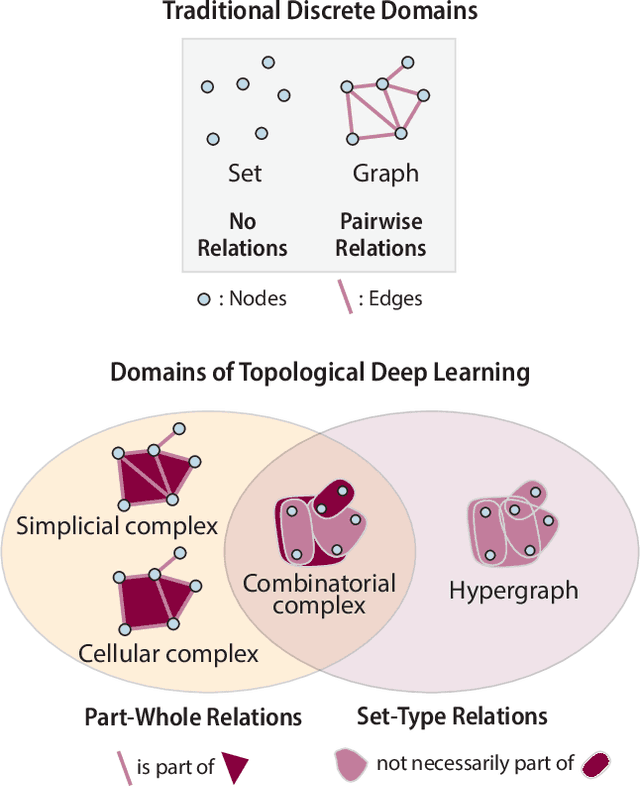
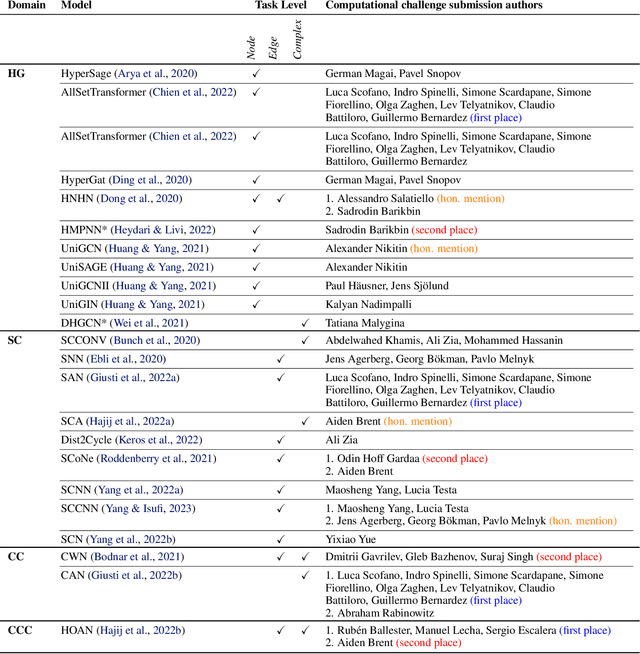
This paper presents the computational challenge on topological deep learning that was hosted within the ICML 2023 Workshop on Topology and Geometry in Machine Learning. The competition asked participants to provide open-source implementations of topological neural networks from the literature by contributing to the python packages TopoNetX (data processing) and TopoModelX (deep learning). The challenge attracted twenty-eight qualifying submissions in its two-month duration. This paper describes the design of the challenge and summarizes its main findings.
Augment Features Beyond Color for Domain Generalized Segmentation
Jul 04, 2023Domain generalized semantic segmentation (DGSS) is an essential but highly challenging task, in which the model is trained only on source data and any target data is not available. Previous DGSS methods can be partitioned into augmentation-based and normalization-based ones. The former either introduces extra biased data or only conducts channel-wise adjustments for data augmentation, and the latter may discard beneficial visual information, both of which lead to limited performance in DGSS. Contrarily, our method performs inter-channel transformation and meanwhile evades domain-specific biases, thus diversifying data and enhancing model generalization performance. Specifically, our method consists of two modules: random image color augmentation (RICA) and random feature distribution augmentation (RFDA). RICA converts images from RGB to the CIELAB color model and randomizes color maps in a perception-based way for image enhancement purposes. We further this augmentation by extending it beyond color to feature space using a CycleGAN-based generative network, which complements RICA and further boosts generalization capability. We conduct extensive experiments, and the generalization results from the synthetic GTAV and SYNTHIA to the real Cityscapes, BDDS, and Mapillary datasets show that our method achieves state-of-the-art performance in DGSS.
Deep Equivariant Hyperspheres
May 24, 2023This paper presents an approach to learning nD features equivariant under orthogonal transformations for point cloud analysis, utilizing hyperspheres and regular n-simplexes. Our main contributions are theoretical and tackle major issues in geometric deep learning such as equivariance and invariance under geometric transformations. Namely, we enrich the recently developed theory of steerable 3D spherical neurons -- SO(3)-equivariant filter banks based on neurons with spherical decision surfaces -- by extending said neurons to nD, which we call deep equivariant hyperspheres, and enabling their stacking in multiple layers. Using the ModelNet40 benchmark, we experimentally verify our theoretical contributions and show a potential practical configuration of the proposed equivariant hyperspheres.
TetraSphere: A Neural Descriptor for O(3)-Invariant Point Cloud Classification
Nov 26, 2022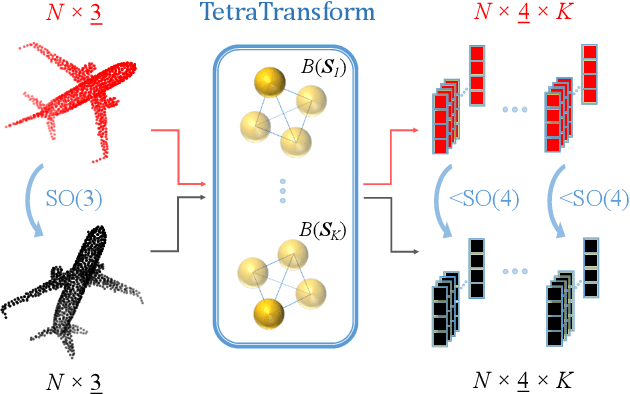
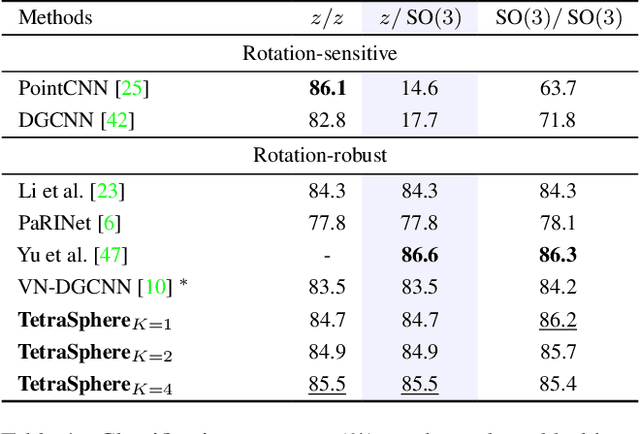
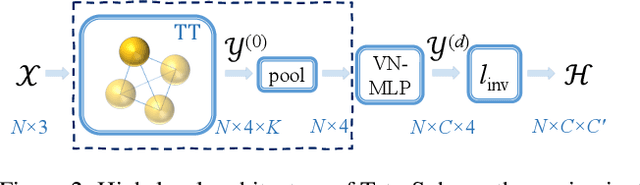
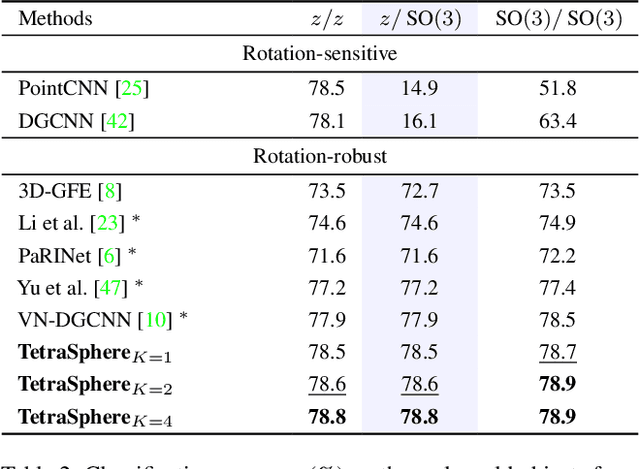
Rotation invariance is an important requirement for the analysis of 3D point clouds. In this paper, we present TetraSphere -- a learnable descriptor for rotation- and reflection-invariant 3D point cloud classification based on recently introduced steerable 3D spherical neurons and vector neurons, as well as the Gram matrix method. Taking 3D points as input, TetraSphere performs TetraTransform -- lifts the 3D input to 4D -- and extracts rotation-equivariant features, subsequently computing pair-wise O(3)-invariant inner products of these features. Remarkably, TetraSphere can be embedded into common point cloud processing models. We demonstrate its effectiveness and versatility by integrating it into DGCNN and VN-DGCNN, performing the classification of arbitrarily rotated ModelNet40 shapes. We show that using TetraSphere improves the performance and reduces the computational complexity by about 10% of the respective baseline methods.
Embed Me If You Can: A Geometric Perceptron
Jun 11, 2020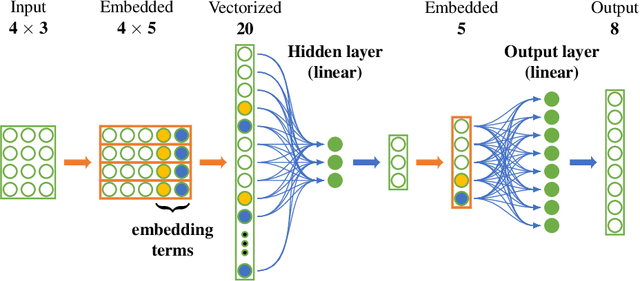

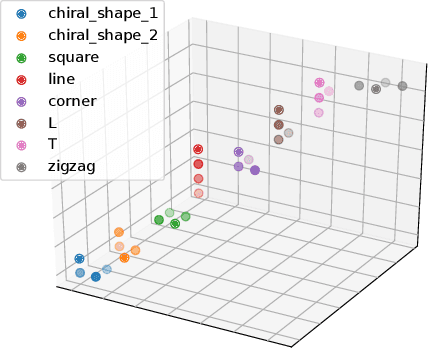
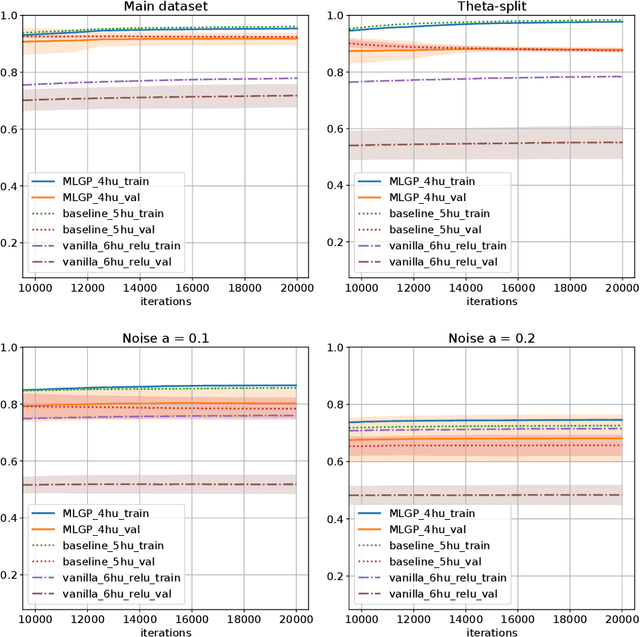
Solving geometric tasks using machine learning is a challenging problem. Standard feed-forward neural networks combine linear or, if the bias parameter is included, affine layers and activation functions. Their geometric modeling is limited, which is why we introduce the alternative model of the multilayer geometric perceptron (MLGP) with units that are geometric neurons, i.e., combinations of hypersphere neurons. The hypersphere neuron is obtained by applying a conformal embedding of Euclidean space. By virtue of Clifford algebra, it can be implemented as the Cartesian dot product. We validate our method on the public 3D Tetris dataset consisting of coordinates of geometric shapes and we show that our method has the capability of generalization over geometric transformations. We demonstrate that our model is superior to the vanilla multilayer perceptron (MLP) while having fewer parameters and no activation function in the hidden layers other than the embedding. In the presence of noise in the data, our model is also superior to the multilayer hypersphere perceptron (MLHP) proposed in prior work. In contrast to the latter, our method reflects the 3D-geometry and provides a topological interpretation of the learned coefficients in the geometric neurons.
A High-Performance CNN Method for Offline Handwritten Chinese Character Recognition and Visualization
Dec 30, 2018
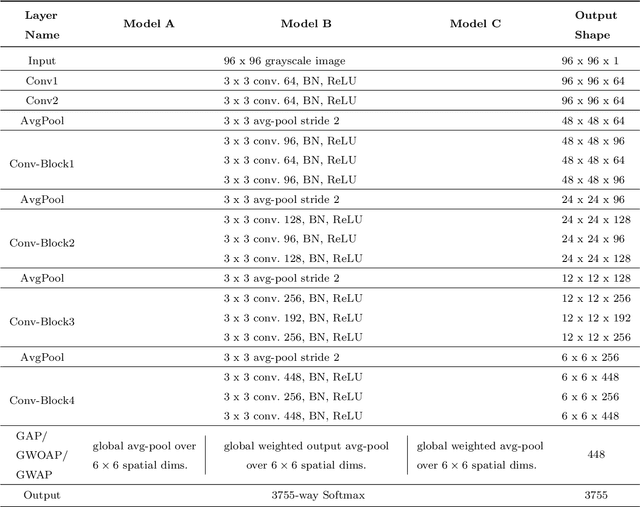


Recent researches introduced fast, compact and efficient convolutional neural networks (CNNs) for offline handwritten Chinese character recognition (HCCR). However, many of them did not address the problem of the network interpretability. We propose a new architecture of a deep CNN with a high recognition performance which is capable of learning deep features for visualization. A special characteristic of our model is the bottleneck layers which enable us to retain its expressiveness while reducing the number of multiply-accumulate operations and the required storage. We introduce a modification of global weighted average pooling (GWAP) - global weighted output average pooling (GWOAP). This paper demonstrates how they allow us to calculate class activation maps (CAMs) in order to indicate the most relevant input character image regions used by our CNN to identify a certain class. Evaluating on the ICDAR-2013 offline HCCR competition dataset, we show that our model enables a relative 0.83% error reduction having 49% fewer parameters and the same computational cost compared to the current state-of-the-art single-network method trained only on handwritten data. Our solution outperforms even recent residual learning approaches.