 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing Trajectory Optimization with Denoising Autoencoders
Mar 28, 2019


Trajectory optimization with learned dynamics models can often suffer from erroneous predictions of out-of-distribution trajectories. We propose to regularize trajectory optimization by means of a denoising autoencoder that is trained on the same trajectories as the dynamics model. We visually demonstrate the effectiveness of the regularization in gradient-based trajectory optimization for open-loop control of an industrial process. We compare with recent model-based reinforcement learning algorithms on a set of popular motor control tasks to demonstrate that the denoising regularization enables state-of-the-art sample-efficiency. We demonstrate the efficacy of the proposed method in regularizing both gradient-based and gradient-free trajectory optimization.
Recurrent Ladder Networks
Dec 18, 2017
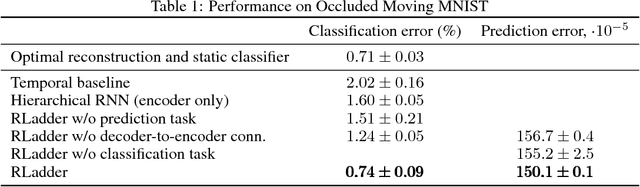
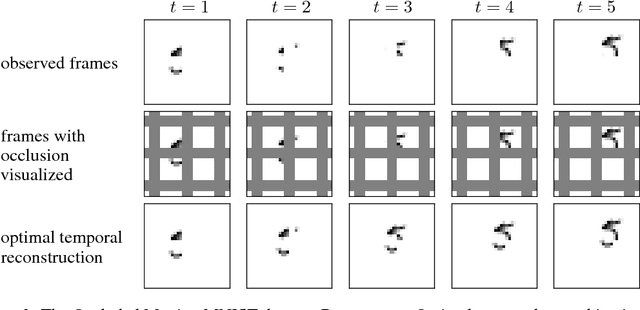

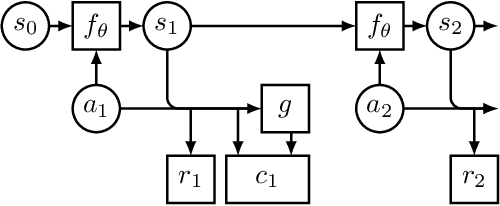
We propose a recurrent extension of the Ladder networks whose structure is motivated by the inference required in hierarchical latent variable models. We demonstrate that the recurrent Ladder is able to handle a wide variety of complex learning tasks that benefit from iterative inference and temporal modeling. The architecture shows close-to-optimal results on temporal modeling of video data, competitive results on music modeling, and improved perceptual grouping based on higher order abstractions, such as stochastic textures and motion cues. We present results for fully supervised, semi-supervised, and unsupervised tasks. The results suggest that the proposed architecture and principles are powerful tools for learning a hierarchy of abstractions, learning iterative inference and handling temporal information.
Tagger: Deep Unsupervised Perceptual Grouping
Nov 28, 2016

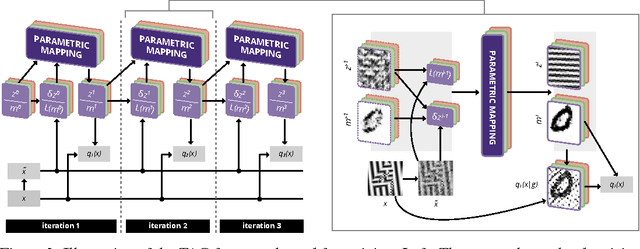
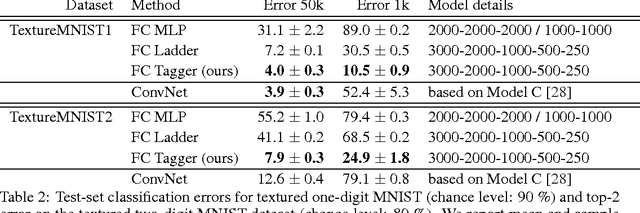
We present a framework for efficient perceptual inference that explicitly reasons about the segmentation of its inputs and features. Rather than being trained for any specific segmentation, our framework learns the grouping process in an unsupervised manner or alongside any supervised task. By enriching the representations of a neural network, we enable it to group the representations of different objects in an iterative manner. By allowing the system to amortize the iterative inference of the groupings, we achieve very fast convergence. In contrast to many other recently proposed methods for addressing multi-object scenes, our system does not assume the inputs to be images and can therefore directly handle other modalities. For multi-digit classification of very cluttered images that require texture segmentation, our method offers improved classification performance over convolutional networks despite being fully connected. Furthermore, we observe that our system greatly improves on the semi-supervised result of a baseline Ladder network on our dataset, indicating that segmentation can also improve sample efficiency.
Semi-Supervised Learning with Ladder Networks
Nov 24, 2015
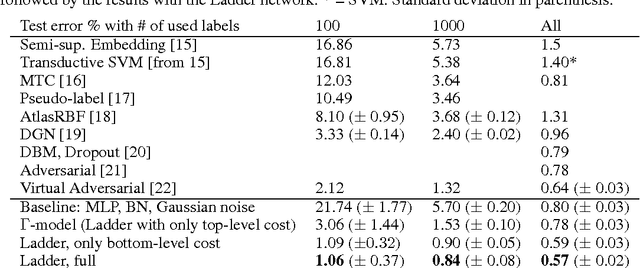


We combine supervised learning with unsupervised learning in deep neural networks. The proposed model is trained to simultaneously minimize the sum of supervised and unsupervised cost functions by backpropagation, avoiding the need for layer-wise pre-training. Our work builds on the Ladder network proposed by Valpola (2015), which we extend by combining the model with supervision. We show that the resulting model reaches state-of-the-art performance in semi-supervised MNIST and CIFAR-10 classification, in addition to permutation-invariant MNIST classification with all labels.
Lateral Connections in Denoising Autoencoders Support Supervised Learning
Apr 30, 2015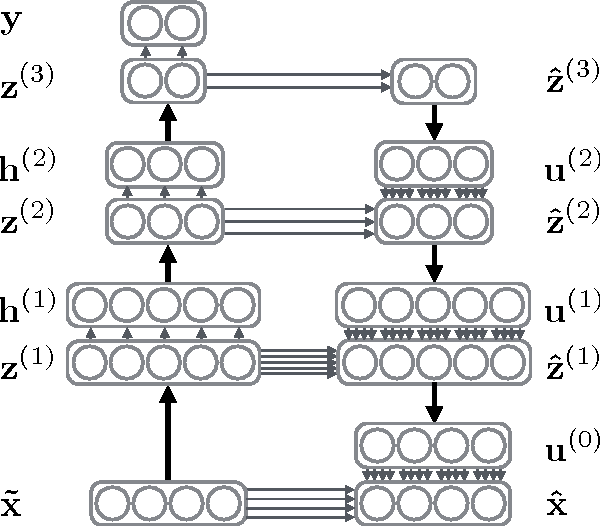

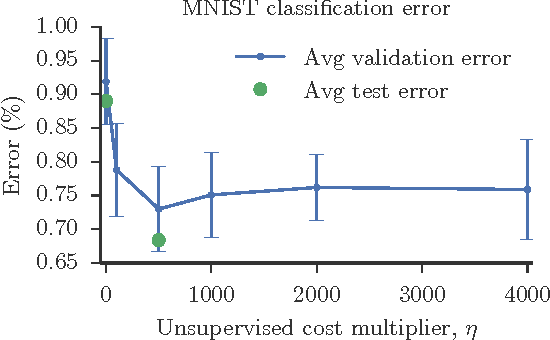
We show how a deep denoising autoencoder with lateral connections can be used as an auxiliary unsupervised learning task to support supervised learning. The proposed model is trained to minimize simultaneously the sum of supervised and unsupervised cost functions by back-propagation, avoiding the need for layer-wise pretraining. It improves the state of the art significantly in the permutation-invariant MNIST classification task.
Denoising autoencoder with modulated lateral connections learns invariant representations of natural images
Mar 31, 2015
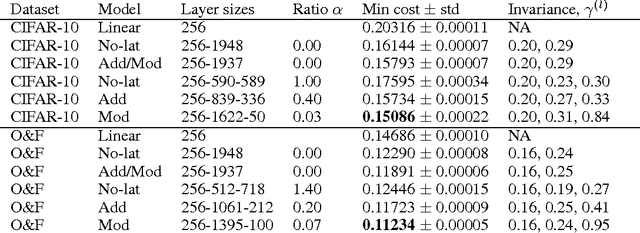

Suitable lateral connections between encoder and decoder are shown to allow higher layers of a denoising autoencoder (dAE) to focus on invariant representations. In regular autoencoders, detailed information needs to be carried through the highest layers but lateral connections from encoder to decoder relieve this pressure. It is shown that abstract invariant features can be translated to detailed reconstructions when invariant features are allowed to modulate the strength of the lateral connection. Three dAE structures with modulated and additive lateral connections, and without lateral connections were compared in experiments using real-world images. The experiments verify that adding modulated lateral connections to the model 1) improves the accuracy of the probability model for inputs, as measured by denoising performance; 2) results in representations whose degree of invariance grows faster towards the higher layers; and 3) supports the formation of diverse invariant poolings.