 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Diffusion Augmented Agents: A Framework for Efficient Exploration and Transfer Learning
Jul 30, 2024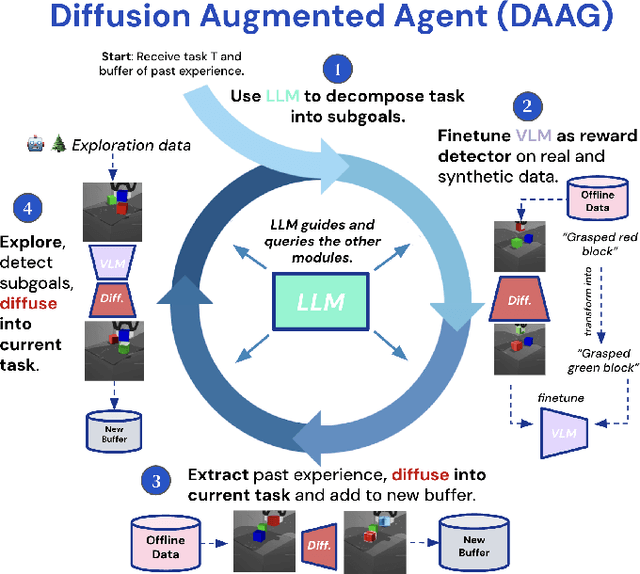
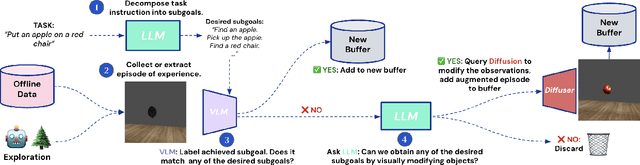


We introduce Diffusion Augmented Agents (DAAG), a novel framework that leverages large language models, vision language models, and diffusion models to improve sample efficiency and transfer learning in reinforcement learning for embodied agents. DAAG hindsight relabels the agent's past experience by using diffusion models to transform videos in a temporally and geometrically consistent way to align with target instructions with a technique we call Hindsight Experience Augmentation. A large language model orchestrates this autonomous process without requiring human supervision, making it well-suited for lifelong learning scenarios. The framework reduces the amount of reward-labeled data needed to 1) finetune a vision language model that acts as a reward detector, and 2) train RL agents on new tasks. We demonstrate the sample efficiency gains of DAAG in simulated robotics environments involving manipulation and navigation. Our results show that DAAG improves learning of reward detectors, transferring past experience, and acquiring new tasks - key abilities for developing efficient lifelong learning agents. Supplementary material and visualizations are available on our website https://sites.google.com/view/diffusion-augmented-agents/
R+X: Retrieval and Execution from Everyday Human Videos
Jul 17, 2024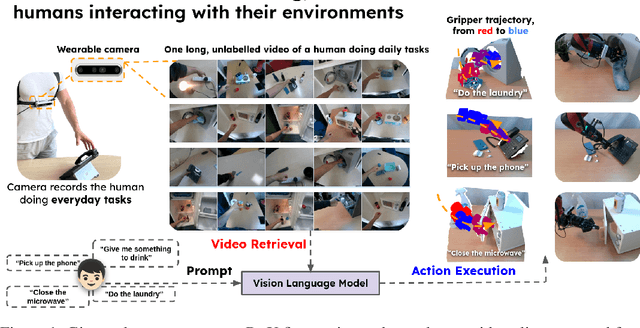
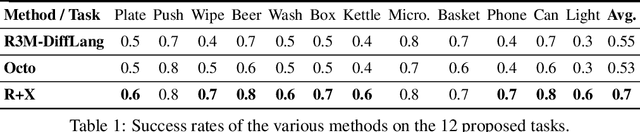

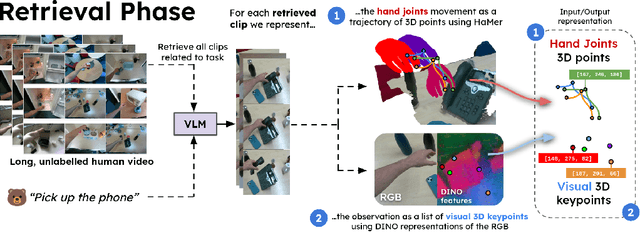
We present R+X, a framework which enables robots to learn skills from long, unlabelled, first-person videos of humans performing everyday tasks. Given a language command from a human, R+X first retrieves short video clips containing relevant behaviour, and then executes the skill by conditioning an in-context imitation learning method on this behaviour. By leveraging a Vision Language Model (VLM) for retrieval, R+X does not require any manual annotation of the videos, and by leveraging in-context learning for execution, robots can perform commanded skills immediately, without requiring a period of training on the retrieved videos. Experiments studying a range of everyday household tasks show that R+X succeeds at translating unlabelled human videos into robust robot skills, and that R+X outperforms several recent alternative methods. Videos are available at https://www.robot-learning.uk/r-plus-x.
Keypoint Action Tokens Enable In-Context Imitation Learning in Robotics
Mar 28, 2024



We show that off-the-shelf text-based Transformers, with no additional training, can perform few-shot in-context visual imitation learning, mapping visual observations to action sequences that emulate the demonstrator's behaviour. We achieve this by transforming visual observations (inputs) and trajectories of actions (outputs) into sequences of tokens that a text-pretrained Transformer (GPT-4 Turbo) can ingest and generate, via a framework we call Keypoint Action Tokens (KAT). Despite being trained only on language, we show that these Transformers excel at translating tokenised visual keypoint observations into action trajectories, performing on par or better than state-of-the-art imitation learning (diffusion policies) in the low-data regime on a suite of real-world, everyday tasks. Rather than operating in the language domain as is typical, KAT leverages text-based Transformers to operate in the vision and action domains to learn general patterns in demonstration data for highly efficient imitation learning, indicating promising new avenues for repurposing natural language models for embodied tasks. Videos are available at https://www.robot-learning.uk/keypoint-action-tokens.
DINOBot: Robot Manipulation via Retrieval and Alignment with Vision Foundation Models
Feb 20, 2024



We propose DINOBot, a novel imitation learning framework for robot manipulation, which leverages the image-level and pixel-level capabilities of features extracted from Vision Transformers trained with DINO. When interacting with a novel object, DINOBot first uses these features to retrieve the most visually similar object experienced during human demonstrations, and then uses this object to align its end-effector with the novel object to enable effective interaction. Through a series of real-world experiments on everyday tasks, we show that exploiting both the image-level and pixel-level properties of vision foundation models enables unprecedented learning efficiency and generalisation. Videos and code are available at https://www.robot-learning.uk/dinobot.
On the Effectiveness of Retrieval, Alignment, and Replay in Manipulation
Dec 19, 2023Imitation learning with visual observations is notoriously inefficient when addressed with end-to-end behavioural cloning methods. In this paper, we explore an alternative paradigm which decomposes reasoning into three phases. First, a retrieval phase, which informs the robot what it can do with an object. Second, an alignment phase, which informs the robot where to interact with the object. And third, a replay phase, which informs the robot how to interact with the object. Through a series of real-world experiments on everyday tasks, such as grasping, pouring, and inserting objects, we show that this decomposition brings unprecedented learning efficiency, and effective inter- and intra-class generalisation. Videos are available at https://www.robot-learning.uk/retrieval-alignment-replay.
Language Models as Zero-Shot Trajectory Generators
Oct 17, 2023Large Language Models (LLMs) have recently shown promise as high-level planners for robots when given access to a selection of low-level skills. However, it is often assumed that LLMs do not possess sufficient knowledge to be used for the low-level trajectories themselves. In this work, we address this assumption thoroughly, and investigate if an LLM (GPT-4) can directly predict a dense sequence of end-effector poses for manipulation skills, when given access to only object detection and segmentation vision models. We study how well a single task-agnostic prompt, without any in-context examples, motion primitives, or external trajectory optimisers, can perform across 26 real-world language-based tasks, such as "open the bottle cap" and "wipe the plate with the sponge", and we investigate which design choices in this prompt are the most effective. Our conclusions raise the assumed limit of LLMs for robotics, and we reveal for the first time that LLMs do indeed possess an understanding of low-level robot control sufficient for a range of common tasks, and that they can additionally detect failures and then re-plan trajectories accordingly. Videos, code, and prompts are available at: https://www.robot-learning.uk/language-models-trajectory-generators.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Towards A Unified Agent with Foundation Models
Jul 18, 2023



Language Models and Vision Language Models have recently demonstrated unprecedented capabilities in terms of understanding human intentions, reasoning, scene understanding, and planning-like behaviour, in text form, among many others. In this work, we investigate how to embed and leverage such abilities in Reinforcement Learning (RL) agents. We design a framework that uses language as the core reasoning tool, exploring how this enables an agent to tackle a series of fundamental RL challenges, such as efficient exploration, reusing experience data, scheduling skills, and learning from observations, which traditionally require separate, vertically designed algorithms. We test our method on a sparse-reward simulated robotic manipulation environment, where a robot needs to stack a set of objects. We demonstrate substantial performance improvements over baselines in exploration efficiency and ability to reuse data from offline datasets, and illustrate how to reuse learned skills to solve novel tasks or imitate videos of human experts.
Demonstrate Once, Imitate Immediately (DOME): Learning Visual Servoing for One-Shot Imitation Learning
Apr 06, 2022
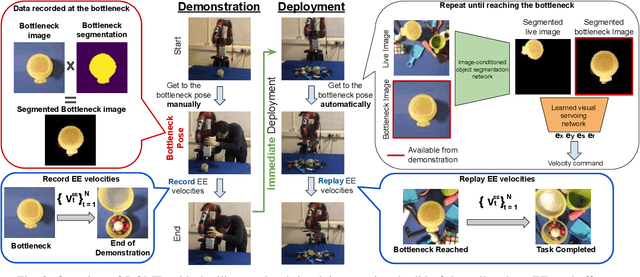


We present DOME, a novel method for one-shot imitation learning, where a task can be learned from just a single demonstration and then be deployed immediately, without any further data collection or training. DOME does not require prior task or object knowledge, and can perform the task in novel object configurations and with distractors. At its core, DOME uses an image-conditioned object segmentation network followed by a learned visual servoing network, to move the robot's end-effector to the same relative pose to the object as during the demonstration, after which the task can be completed by replaying the demonstration's end-effector velocities. We show that DOME achieves near 100% success rate on 7 real-world everyday tasks, and we perform several studies to thoroughly understand each individual component of DOME.