 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR+X: Retrieval and Execution from Everyday Human Videos
Paper and Code
Jul 17, 2024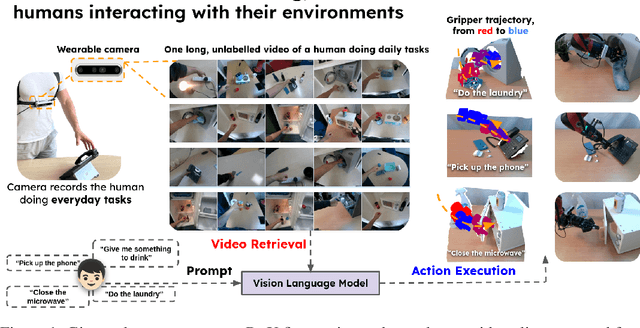
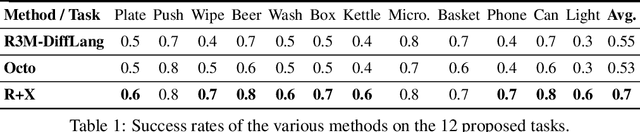

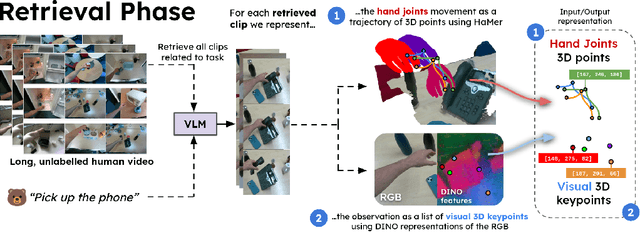
We present R+X, a framework which enables robots to learn skills from long, unlabelled, first-person videos of humans performing everyday tasks. Given a language command from a human, R+X first retrieves short video clips containing relevant behaviour, and then executes the skill by conditioning an in-context imitation learning method on this behaviour. By leveraging a Vision Language Model (VLM) for retrieval, R+X does not require any manual annotation of the videos, and by leveraging in-context learning for execution, robots can perform commanded skills immediately, without requiring a period of training on the retrieved videos. Experiments studying a range of everyday household tasks show that R+X succeeds at translating unlabelled human videos into robust robot skills, and that R+X outperforms several recent alternative methods. Videos are available at https://www.robot-learning.uk/r-plus-x.