 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Ladder Networks
Dec 18, 2017
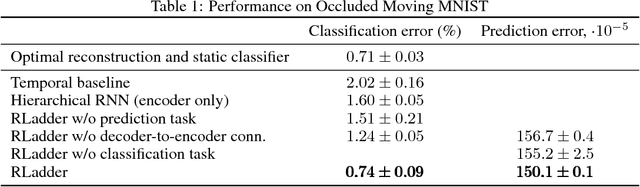
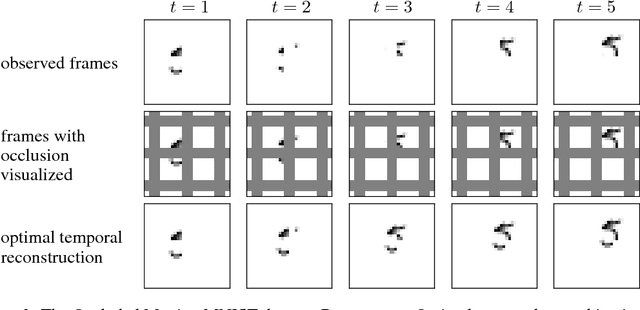

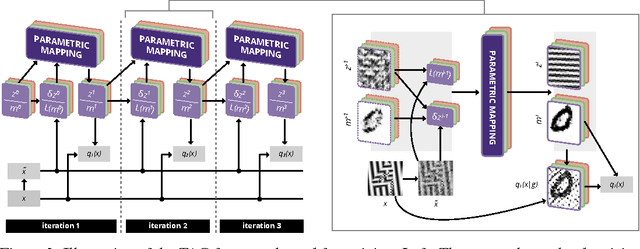
We propose a recurrent extension of the Ladder networks whose structure is motivated by the inference required in hierarchical latent variable models. We demonstrate that the recurrent Ladder is able to handle a wide variety of complex learning tasks that benefit from iterative inference and temporal modeling. The architecture shows close-to-optimal results on temporal modeling of video data, competitive results on music modeling, and improved perceptual grouping based on higher order abstractions, such as stochastic textures and motion cues. We present results for fully supervised, semi-supervised, and unsupervised tasks. The results suggest that the proposed architecture and principles are powerful tools for learning a hierarchy of abstractions, learning iterative inference and handling temporal information.
Tagger: Deep Unsupervised Perceptual Grouping
Nov 28, 2016

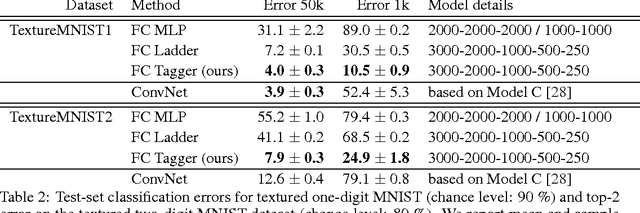
We present a framework for efficient perceptual inference that explicitly reasons about the segmentation of its inputs and features. Rather than being trained for any specific segmentation, our framework learns the grouping process in an unsupervised manner or alongside any supervised task. By enriching the representations of a neural network, we enable it to group the representations of different objects in an iterative manner. By allowing the system to amortize the iterative inference of the groupings, we achieve very fast convergence. In contrast to many other recently proposed methods for addressing multi-object scenes, our system does not assume the inputs to be images and can therefore directly handle other modalities. For multi-digit classification of very cluttered images that require texture segmentation, our method offers improved classification performance over convolutional networks despite being fully connected. Furthermore, we observe that our system greatly improves on the semi-supervised result of a baseline Ladder network on our dataset, indicating that segmentation can also improve sample efficiency.