 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning by Hallucinating: Vision-Language Pre-training with Weak Supervision
Oct 27, 2022

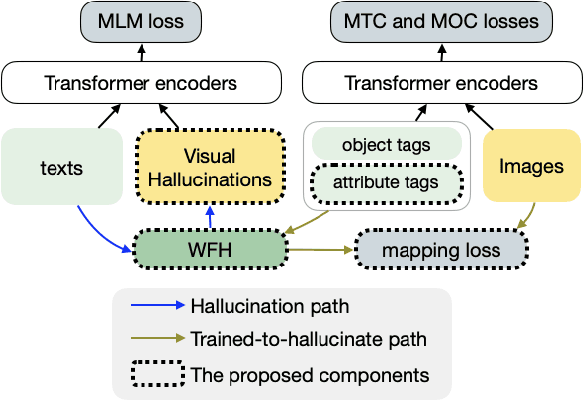
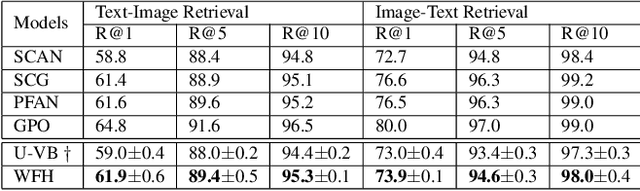
Weakly-supervised vision-language (V-L) pre-training (W-VLP) aims at learning cross-modal alignment with little or no paired data, such as aligned images and captions. Recent W-VLP methods, which pair visual features with object tags, help achieve performances comparable with some VLP models trained with aligned pairs in various V-L downstream tasks. This, however, is not the case in cross-modal retrieval (XMR). We argue that the learning of such a W-VLP model is curbed and biased by the object tags of limited semantics. We address the lack of paired V-L data for model supervision with a novel Visual Vocabulary based Feature Hallucinator (WFH), which is trained via weak supervision as a W-VLP model, not requiring images paired with captions. WFH generates visual hallucinations from texts, which are then paired with the originally unpaired texts, allowing more diverse interactions across modalities. Empirically, WFH consistently boosts the prior W-VLP works, e.g. U-VisualBERT (U-VB), over a variety of V-L tasks, i.e. XMR, Visual Question Answering, etc. Notably, benchmarked with recall@{1,5,10}, it consistently improves U-VB on image-to-text and text-to-image retrieval on two popular datasets Flickr30K and MSCOCO. Meanwhile, it gains by at least 14.5% in cross-dataset generalization tests on these XMR tasks. Moreover, in other V-L downstream tasks considered, our WFH models are on par with models trained with paired V-L data, revealing the utility of unpaired data. These results demonstrate greater generalization of the proposed W-VLP model with WFH.
Learning to hash with semantic similarity metrics and empirical KL divergence
May 11, 2020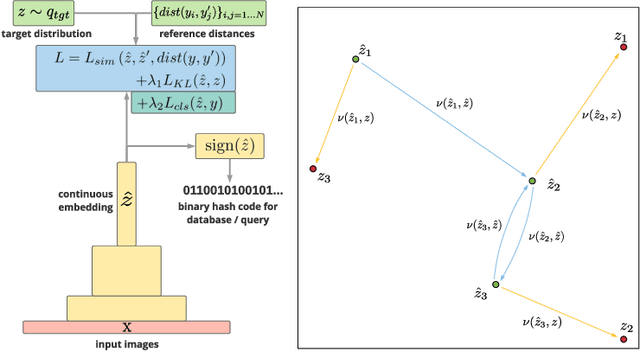

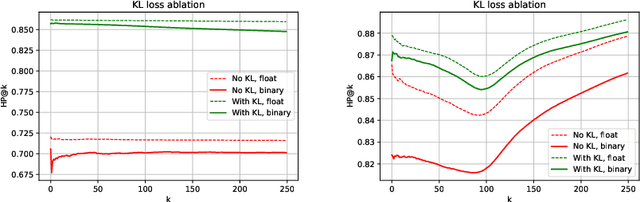
Learning to hash is an efficient paradigm for exact and approximate nearest neighbor search from massive databases. Binary hash codes are typically extracted from an image by rounding output features from a CNN, which is trained on a supervised binary similar/ dissimilar task. Drawbacks of this approach are: (i) resulting codes do not necessarily capture semantic similarity of the input data (ii) rounding results in information loss, manifesting as decreased retrieval performance and (iii) Using only class-wise similarity as a target can lead to trivial solutions, simply encoding classifier outputs rather than learning more intricate relations, which is not detected by most performance metrics. We overcome (i) via a novel loss function encouraging the relative hash code distances of learned features to match those derived from their targets. We address (ii) via a differentiable estimate of the KL divergence between network outputs and a binary target distribution, resulting in minimal information loss when the features are rounded to binary. Finally, we resolve (iii) by focusing on a hierarchical precision metric. Efficiency of the methods is demonstrated with semantic image retrieval on the CIFAR-100, ImageNet and Conceptual Captions datasets, using similarities inferred from the WordNet label hierarchy or sentence embeddings.
SHREWD: Semantic Hierarchy-based Relational Embeddings for Weakly-supervised Deep Hashing
Aug 12, 2019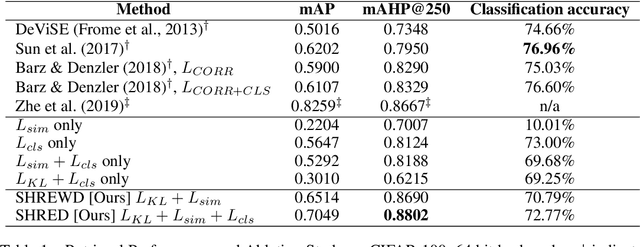

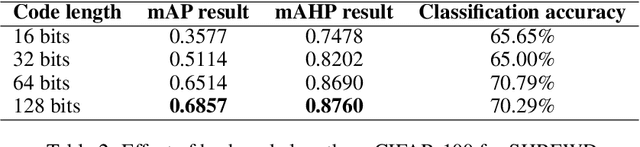

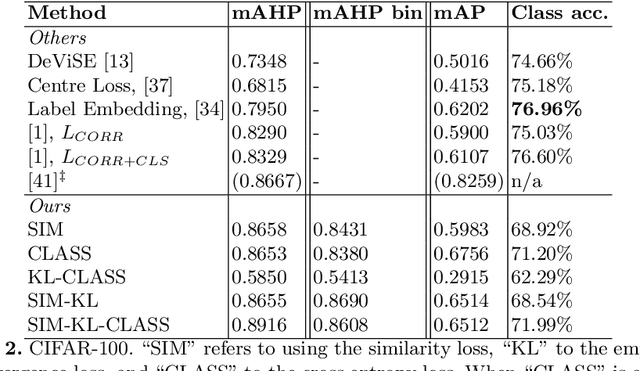
Using class labels to represent class similarity is a typical approach to training deep hashing systems for retrieval; samples from the same or different classes take binary 1 or 0 similarity values. This similarity does not model the full rich knowledge of semantic relations that may be present between data points. In this work we build upon the idea of using semantic hierarchies to form distance metrics between all available sample labels; for example cat to dog has a smaller distance than cat to guitar. We combine this type of semantic distance into a loss function to promote similar distances between the deep neural network embeddings. We also introduce an empirical Kullback-Leibler divergence loss term to promote binarization and uniformity of the embeddings. We test the resulting SHREWD method and demonstrate improvements in hierarchical retrieval scores using compact, binary hash codes instead of real valued ones, and show that in a weakly supervised hashing setting we are able to learn competitively without explicitly relying on class labels, but instead on similarities between labels.
On the exact relationship between the denoising function and the data distribution
Sep 06, 2017We prove an exact relationship between the optimal denoising function and the data distribution in the case of additive Gaussian noise, showing that denoising implicitly models the structure of data allowing it to be exploited in the unsupervised learning of representations. This result generalizes a known relationship [2], which is valid only in the limit of small corruption noise.