 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiTL: Cross-modal Retrieval with Weakly-supervised Vision-language Pre-training via Prompting
Jul 14, 2023



Vision-language (VL) Pre-training (VLP) has shown to well generalize VL models over a wide range of VL downstream tasks, especially for cross-modal retrieval. However, it hinges on a huge amount of image-text pairs, which requires tedious and costly curation. On the contrary, weakly-supervised VLP (W-VLP) explores means with object tags generated by a pre-trained object detector (OD) from images. Yet, they still require paired information, i.e. images and object-level annotations, as supervision to train an OD. To further reduce the amount of supervision, we propose Prompts-in-The-Loop (PiTL) that prompts knowledge from large language models (LLMs) to describe images. Concretely, given a category label of an image, e.g. refinery, the knowledge, e.g. a refinery could be seen with large storage tanks, pipework, and ..., extracted by LLMs is used as the language counterpart. The knowledge supplements, e.g. the common relations among entities most likely appearing in a scene. We create IN14K, a new VL dataset of 9M images and 1M descriptions of 14K categories from ImageNet21K with PiTL. Empirically, the VL models pre-trained with PiTL-generated pairs are strongly favored over other W-VLP works on image-to-text (I2T) and text-to-image (T2I) retrieval tasks, with less supervision. The results reveal the effectiveness of PiTL-generated pairs for VLP.
Learning by Hallucinating: Vision-Language Pre-training with Weak Supervision
Oct 27, 2022

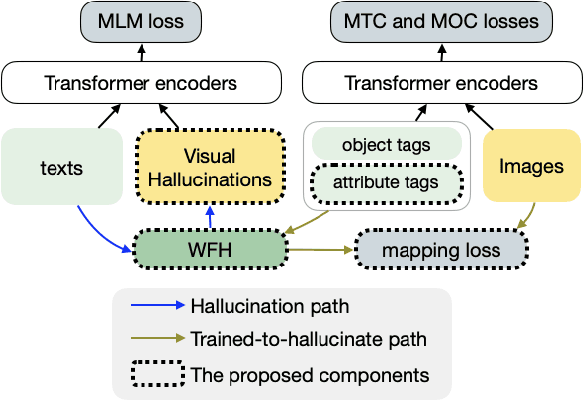
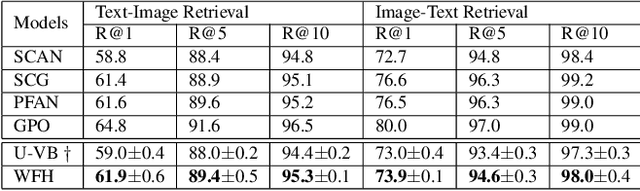
Weakly-supervised vision-language (V-L) pre-training (W-VLP) aims at learning cross-modal alignment with little or no paired data, such as aligned images and captions. Recent W-VLP methods, which pair visual features with object tags, help achieve performances comparable with some VLP models trained with aligned pairs in various V-L downstream tasks. This, however, is not the case in cross-modal retrieval (XMR). We argue that the learning of such a W-VLP model is curbed and biased by the object tags of limited semantics. We address the lack of paired V-L data for model supervision with a novel Visual Vocabulary based Feature Hallucinator (WFH), which is trained via weak supervision as a W-VLP model, not requiring images paired with captions. WFH generates visual hallucinations from texts, which are then paired with the originally unpaired texts, allowing more diverse interactions across modalities. Empirically, WFH consistently boosts the prior W-VLP works, e.g. U-VisualBERT (U-VB), over a variety of V-L tasks, i.e. XMR, Visual Question Answering, etc. Notably, benchmarked with recall@{1,5,10}, it consistently improves U-VB on image-to-text and text-to-image retrieval on two popular datasets Flickr30K and MSCOCO. Meanwhile, it gains by at least 14.5% in cross-dataset generalization tests on these XMR tasks. Moreover, in other V-L downstream tasks considered, our WFH models are on par with models trained with paired V-L data, revealing the utility of unpaired data. These results demonstrate greater generalization of the proposed W-VLP model with WFH.
CLIP4IDC: CLIP for Image Difference Captioning
Jun 01, 2022
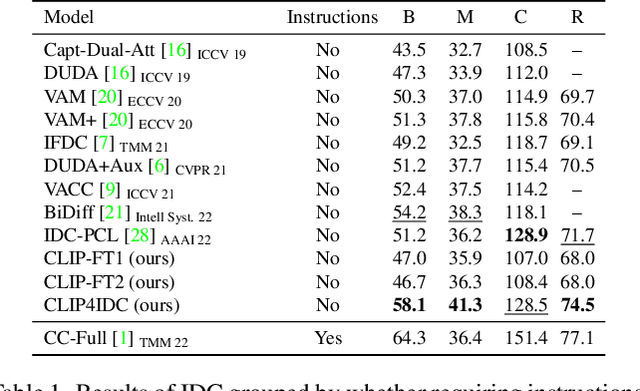
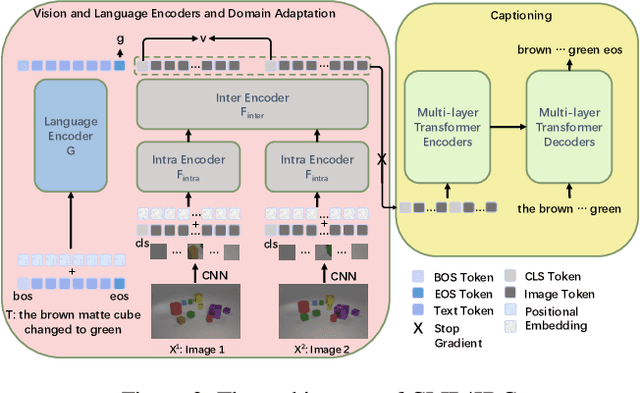

Image Difference Captioning (IDC) aims at generating sentences to describe the differences between two similar-looking images. The conventional approaches learn captioning models on the offline-extracted visual features and the learning can not be propagated back to the fixed feature extractors pre-trained on image classification datasets. Accordingly, potential improvements can be made by fine-tuning the visual features for: 1) narrowing the gap when generalizing the visual extractor trained on image classification to IDC, and 2) relating the extracted visual features to the descriptions of the corresponding changes. We thus propose CLIP4IDC to transfer a CLIP model for the IDC task to attain these improvements. Different from directly fine-tuning CLIP to generate sentences, a task-specific domain adaptation is used to improve the extracted features. Specifically, the target is to train CLIP on raw pixels to relate the image pairs to the described changes. Afterwards, a vanilla Transformer is trained for IDC on the features extracted by the vision encoder of CLIP. Experiments on three IDC benchmark datasets, CLEVR-Change, Spot-the-Diff and Image-Editing-Request, demonstrate the effectiveness of CLIP4IDC. Our code and models will be released at https://github.com/sushizixin/CLIP4IDC.
Tackling the Unannotated: Scene Graph Generation with Bias-Reduced Models
Aug 18, 2020


Predicting a scene graph that captures visual entities and their interactions in an image has been considered a crucial step towards full scene comprehension. Recent scene graph generation (SGG) models have shown their capability of capturing the most frequent relations among visual entities. However, the state-of-the-art results are still far from satisfactory, e.g. models can obtain 31% in overall recall R@100, whereas the likewise important mean class-wise recall mR@100 is only around 8% on Visual Genome (VG). The discrepancy between R and mR results urges to shift the focus from pursuing a high R to a high mR with a still competitive R. We suspect that the observed discrepancy stems from both the annotation bias and sparse annotations in VG, in which many visual entity pairs are either not annotated at all or only with a single relation when multiple ones could be valid. To address this particular issue, we propose a novel SGG training scheme that capitalizes on self-learned knowledge. It involves two relation classifiers, one offering a less biased setting for the other to base on. The proposed scheme can be applied to most of the existing SGG models and is straightforward to implement. We observe significant relative improvements in mR (between +6.6% and +20.4%) and competitive or better R (between -2.4% and 0.3%) across all standard SGG tasks.