 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning by Hallucinating: Vision-Language Pre-training with Weak Supervision
Paper and Code
Oct 27, 2022

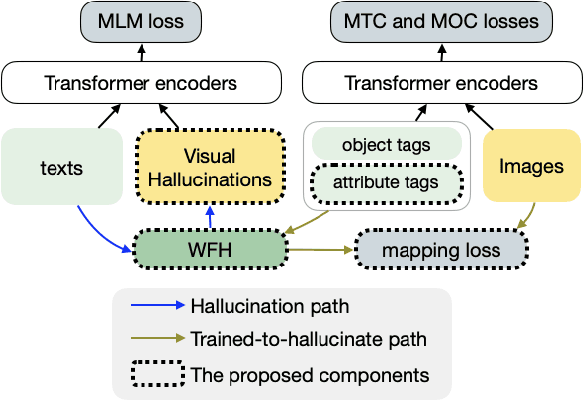
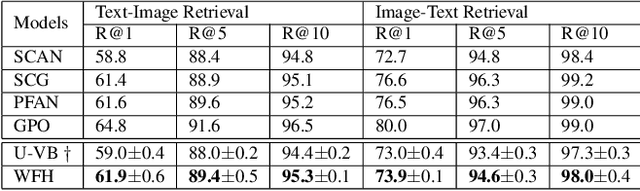
Weakly-supervised vision-language (V-L) pre-training (W-VLP) aims at learning cross-modal alignment with little or no paired data, such as aligned images and captions. Recent W-VLP methods, which pair visual features with object tags, help achieve performances comparable with some VLP models trained with aligned pairs in various V-L downstream tasks. This, however, is not the case in cross-modal retrieval (XMR). We argue that the learning of such a W-VLP model is curbed and biased by the object tags of limited semantics. We address the lack of paired V-L data for model supervision with a novel Visual Vocabulary based Feature Hallucinator (WFH), which is trained via weak supervision as a W-VLP model, not requiring images paired with captions. WFH generates visual hallucinations from texts, which are then paired with the originally unpaired texts, allowing more diverse interactions across modalities. Empirically, WFH consistently boosts the prior W-VLP works, e.g. U-VisualBERT (U-VB), over a variety of V-L tasks, i.e. XMR, Visual Question Answering, etc. Notably, benchmarked with recall@{1,5,10}, it consistently improves U-VB on image-to-text and text-to-image retrieval on two popular datasets Flickr30K and MSCOCO. Meanwhile, it gains by at least 14.5% in cross-dataset generalization tests on these XMR tasks. Moreover, in other V-L downstream tasks considered, our WFH models are on par with models trained with paired V-L data, revealing the utility of unpaired data. These results demonstrate greater generalization of the proposed W-VLP model with WFH.