 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP4IDC: CLIP for Image Difference Captioning
Paper and Code

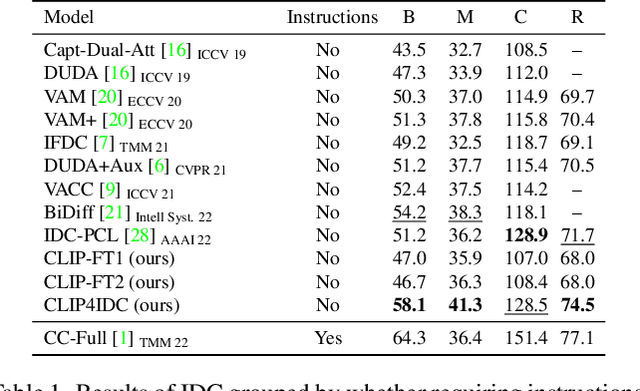
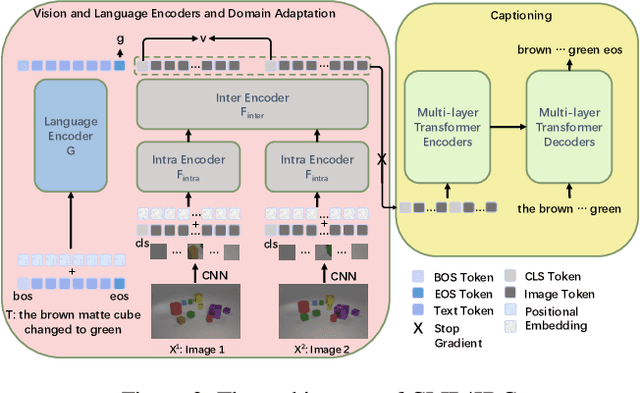

Image Difference Captioning (IDC) aims at generating sentences to describe the differences between two similar-looking images. The conventional approaches learn captioning models on the offline-extracted visual features and the learning can not be propagated back to the fixed feature extractors pre-trained on image classification datasets. Accordingly, potential improvements can be made by fine-tuning the visual features for: 1) narrowing the gap when generalizing the visual extractor trained on image classification to IDC, and 2) relating the extracted visual features to the descriptions of the corresponding changes. We thus propose CLIP4IDC to transfer a CLIP model for the IDC task to attain these improvements. Different from directly fine-tuning CLIP to generate sentences, a task-specific domain adaptation is used to improve the extracted features. Specifically, the target is to train CLIP on raw pixels to relate the image pairs to the described changes. Afterwards, a vanilla Transformer is trained for IDC on the features extracted by the vision encoder of CLIP. Experiments on three IDC benchmark datasets, CLEVR-Change, Spot-the-Diff and Image-Editing-Request, demonstrate the effectiveness of CLIP4IDC. Our code and models will be released at https://github.com/sushizixin/CLIP4IDC.