 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTackling the Unannotated: Scene Graph Generation with Bias-Reduced Models
Paper and Code
Aug 18, 2020


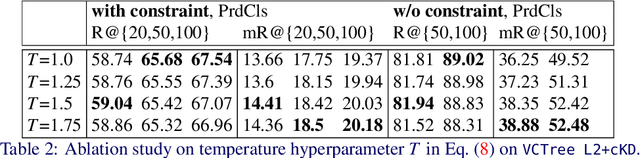
Predicting a scene graph that captures visual entities and their interactions in an image has been considered a crucial step towards full scene comprehension. Recent scene graph generation (SGG) models have shown their capability of capturing the most frequent relations among visual entities. However, the state-of-the-art results are still far from satisfactory, e.g. models can obtain 31% in overall recall R@100, whereas the likewise important mean class-wise recall mR@100 is only around 8% on Visual Genome (VG). The discrepancy between R and mR results urges to shift the focus from pursuing a high R to a high mR with a still competitive R. We suspect that the observed discrepancy stems from both the annotation bias and sparse annotations in VG, in which many visual entity pairs are either not annotated at all or only with a single relation when multiple ones could be valid. To address this particular issue, we propose a novel SGG training scheme that capitalizes on self-learned knowledge. It involves two relation classifiers, one offering a less biased setting for the other to base on. The proposed scheme can be applied to most of the existing SGG models and is straightforward to implement. We observe significant relative improvements in mR (between +6.6% and +20.4%) and competitive or better R (between -2.4% and 0.3%) across all standard SGG tasks.