 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-Guided Self-Supervised Summarization of Nursing Notes
Jul 04, 2024



Nursing notes, an important component of Electronic Health Records (EHRs), keep track of the progression of a patient's health status during a care episode. Distilling the key information in nursing notes through text summarization techniques can improve clinicians' efficiency in understanding patients' conditions when reviewing nursing notes. However, existing abstractive summarization methods in the clinical setting have often overlooked nursing notes and require the creation of reference summaries for supervision signals, which is time-consuming. In this work, we introduce QGSumm, a query-guided self-supervised domain adaptation framework for nursing note summarization. Using patient-related clinical queries as guidance, our approach generates high-quality, patient-centered summaries without relying on reference summaries for training. Through automatic and manual evaluation by an expert clinician, we demonstrate the strengths of our approach compared to the state-of-the-art Large Language Models (LLMs) in both zero-shot and few-shot settings. Ultimately, our approach provides a new perspective on conditional text summarization, tailored to the specific interests of clinical personnel.
Estimating treatment effects from single-arm trials via latent-variable modeling
Nov 06, 2023Randomized controlled trials (RCTs) are the accepted standard for treatment effect estimation but they can be infeasible due to ethical reasons and prohibitive costs. Single-arm trials, where all patients belong to the treatment group, can be a viable alternative but require access to an external control group. We propose an identifiable deep latent-variable model for this scenario that can also account for missing covariate observations by modeling their structured missingness patterns. Our method uses amortized variational inference to learn both group-specific and identifiable shared latent representations, which can subsequently be used for (i) patient matching if treatment outcomes are not available for the treatment group, or for (ii) direct treatment effect estimation assuming outcomes are available for both groups. We evaluate the model on a public benchmark as well as on a data set consisting of a published RCT study and real-world electronic health records. Compared to previous methods, our results show improved performance both for direct treatment effect estimation as well as for effect estimation via patient matching.
Synergizing Data Imputation and Electronic Health Records for Advancing Prostate Cancer Research: Challenges, and Practical Applications
Oct 24, 2023The presence of detailed clinical information in electronic health record (EHR) systems presents promising prospects for enhancing patient care through automated retrieval techniques. Nevertheless, it is widely acknowledged that accessing data within EHRs is hindered by various methodological challenges. Specifically, the clinical notes stored in EHRs are composed in a narrative form, making them prone to ambiguous formulations and highly unstructured data presentations, while structured reports commonly suffer from missing and/or erroneous data entries. This inherent complexity poses significant challenges when attempting automated large-scale medical knowledge extraction tasks, necessitating the application of advanced tools, such as natural language processing (NLP), as well as data audit techniques. This work aims to address these obstacles by creating and validating a novel pipeline designed to extract relevant data pertaining to prostate cancer patients. The objective is to exploit the inherent redundancies available within the integrated structured and unstructured data entries within EHRs in order to generate comprehensive and reliable medical databases, ready to be used in advanced research studies. Additionally, the study explores potential opportunities arising from these data, offering valuable prospects for advancing research in prostate cancer.
Longitudinal Variational Autoencoder
Jun 17, 2020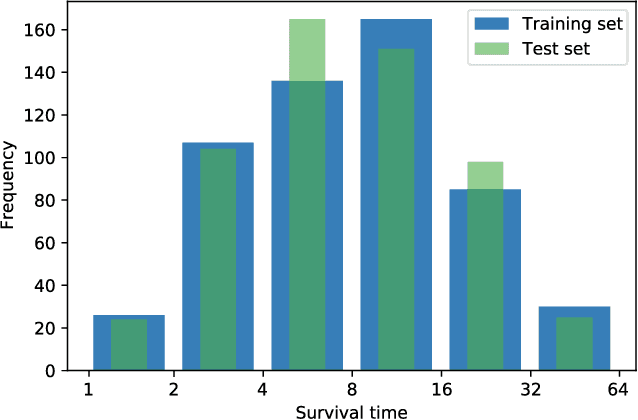

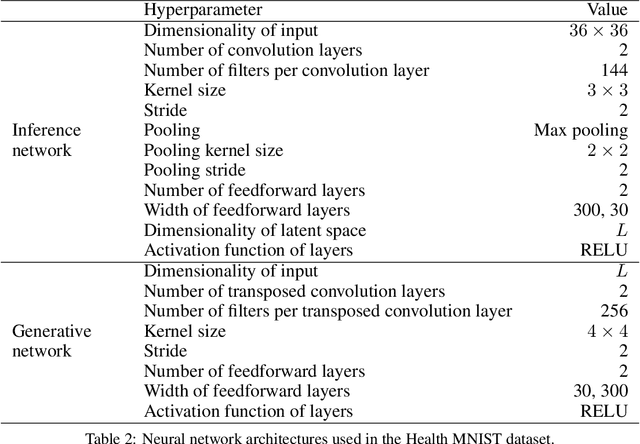
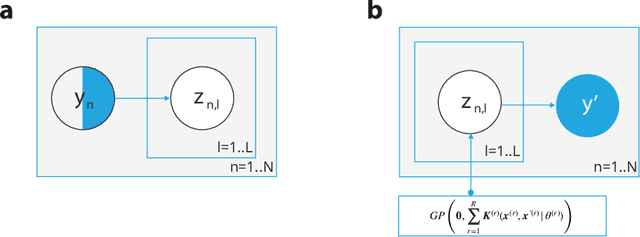
Longitudinal datasets measured repeatedly over time from individual subjects, arise in many biomedical, psychological, social, and other studies. Such multivariate time-series are often high-dimensional and contain missing values. A common approach to analyse this kind of data is to learn a low-dimensional representation using variational autoencoders (VAEs). However, standard VAEs assume that the learned representations are i.i.d., and fail to capture the correlations between the data samples. We propose a novel deep generative model, Longitudinal VAE (L-VAE), that uses a multi-output additive Gaussian process (GP) prior to extend the VAE's capability to learn structured low-dimensional representations imposed by auxiliary covariate information, and also derive a new divergence upper bound for such GPs. Our approach can simultaneously accommodate both time-varying shared and random effects, produce structured low-dimensional representations, disentangle effects of individual covariates or their interactions, and achieve highly accurate predictive performance. We compare our model against previous methods on synthetic and clinical datasets, and demonstrate the state-of-the-art performance in data imputation, reconstruction, and long-term prediction tasks.
Latent Gaussian process with composite likelihoods for data-driven disease stratification
Sep 04, 2019
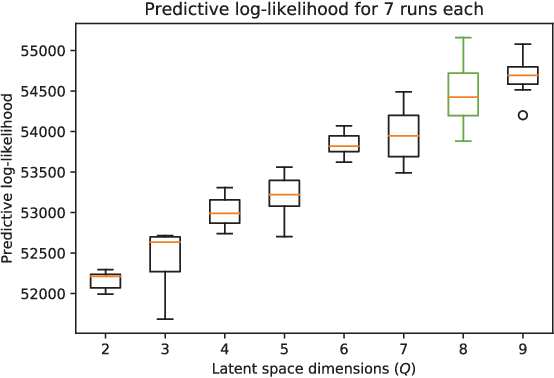
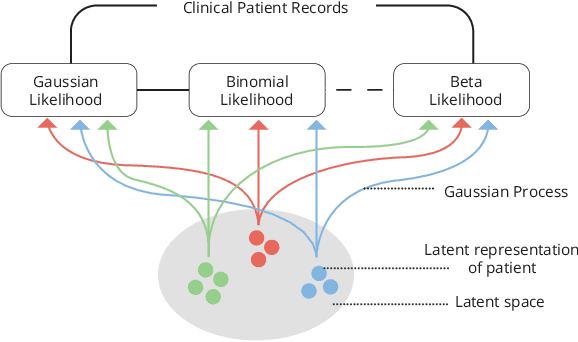
Data-driven techniques for identifying disease subtypes using medical records can greatly benefit the management of patients' health and unravel the underpinnings of diseases. Clinical patient records are typically collected from disparate sources and result in high-dimensional data comprising of multiple likelihoods with noisy and missing values. Probabilistic methods capable of analysing large-scale patient records have a central role in biomedical research and are expected to become even more important when data-driven personalised medicine will be established in clinical practise. In this work we propose an unsupervised, generative model that can identify clustering among patients in a latent space while making use of all available data (i.e. in a heterogeneous data setting with noisy and missing values). We make use of the Gaussian process latent variable models (GPLVM) and deep neural networks to create a non-linear dimensionality reduction technique for heterogeneous data. The effectiveness of our model is demonstrated on clinical data of Parkinson's disease patients treated at the HUS Helsinki University Hospital. We demonstrate sub-groups from the heterogeneous patient data, evaluate the robustness of the findings, and interpret cluster characteristics.