 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartialLoading: User Scheduling and Bandwidth Allocation for Parameter-sharing Edge Inference
Mar 29, 2025By provisioning inference offloading services, edge inference drives the rapid growth of AI applications at the network edge. However, achieving high task throughput with stringent latency requirements remains a significant challenge. To address this issue, we develop a parameter-sharing AI model loading (PartialLoading) framework for multi-user edge inference, which exploits two key insights: 1) the majority of latency arises from loading AI models into server GPU memory, and 2) different AI models can share a significant number of parameters, for which redundant loading should be avoided. Towards this end, we formulate a joint multi-user scheduling and spectrum bandwidth allocation problem to maximize task throughput by exploiting shared parameter blocks across models. The intuition is to judiciously schedule user requests to reuse the shared parameter blocks between consecutively loaded models, thereby reducing model loading time substantially. To facilitate solution finding, we decouple the problem into two sub-problems, i.e., user scheduling and bandwidth allocation, showing that solving them sequentially is equivalent to solving the original problem. Due to the NP-hardness of the problem, we first study an important special case called the "bottom-layer-sharing" case, where AI models share some bottom layers within clusters, and design a dynamic programming-based algorithm to obtain the optimal solution in polynomial time. For the general case, where shared parameter blocks appear at arbitrary positions within AI models, we propose a greedy heuristic to obtain the sub-optimal solution efficiently. Simulation results demonstrate that the proposed framework significantly improves task throughput under deadline constraints compared with user scheduling without exploiting parameter sharing.
TrimCaching: Parameter-sharing AI Model Caching in Wireless Edge Networks
May 07, 2024



Next-generation mobile networks are expected to facilitate fast AI model downloading to end users. By caching models on edge servers, mobile networks can deliver models to end users with low latency, resulting in a paradigm called edge model caching. In this paper, we develop a novel model placement scheme, called parameter-sharing model caching (TrimCaching). TrimCaching exploits the key observation that a wide range of AI models, such as convolutional neural networks or large language models, can share a significant proportion of parameter blocks containing reusable knowledge, thereby improving storage efficiency. To this end, we formulate a parameter-sharing model placement problem to maximize the cache hit ratio in multi-edge wireless networks by balancing the fundamental tradeoff between storage efficiency and service latency. We show that the formulated problem is a submodular maximization problem with submodular constraints, for which no polynomial-time approximation algorithm exists. To overcome this challenge, we study an important special case, where a small fixed number of parameter blocks are shared across models, which often holds in practice. In such a case, a polynomial-time algorithm with $\left(1-\epsilon\right)/2$-approximation guarantee is developed. Subsequently, we address the original problem for the general case by developing a greedy algorithm. Simulation results demonstrate that the proposed TrimCaching framework significantly improves the cache hit ratio compared with state-of-the-art content caching without exploiting shared parameters in AI models.
AdaptSFL: Adaptive Split Federated Learning in Resource-constrained Edge Networks
Mar 19, 2024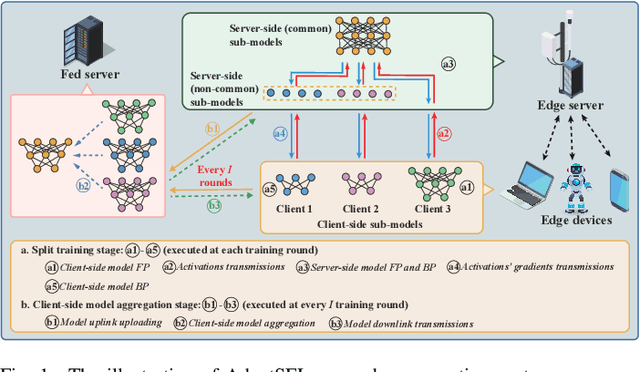
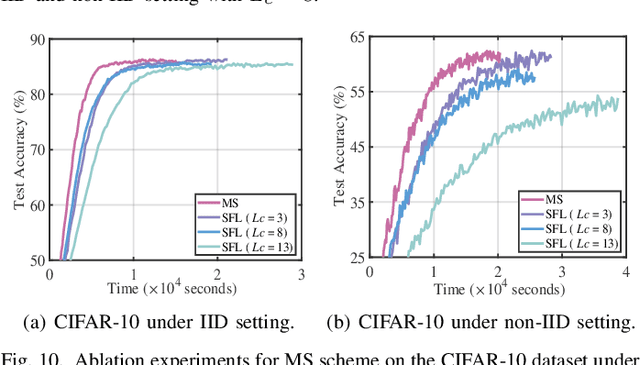
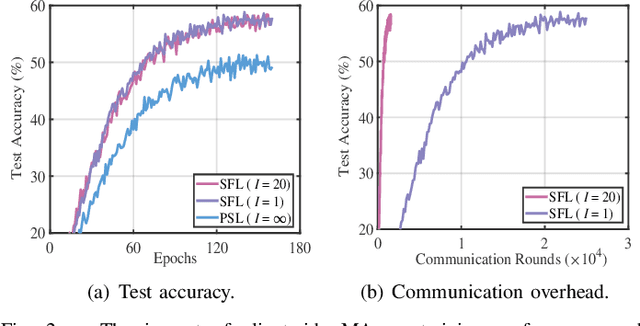
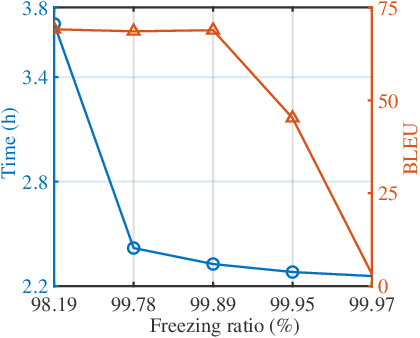
The increasing complexity of deep neural networks poses significant barriers to democratizing them to resource-limited edge devices. To address this challenge, split federated learning (SFL) has emerged as a promising solution by of floading the primary training workload to a server via model partitioning while enabling parallel training among edge devices. However, although system optimization substantially influences the performance of SFL under resource-constrained systems, the problem remains largely uncharted. In this paper, we provide a convergence analysis of SFL which quantifies the impact of model splitting (MS) and client-side model aggregation (MA) on the learning performance, serving as a theoretical foundation. Then, we propose AdaptSFL, a novel resource-adaptive SFL framework, to expedite SFL under resource-constrained edge computing systems. Specifically, AdaptSFL adaptively controls client-side MA and MS to balance communication-computing latency and training convergence. Extensive simulations across various datasets validate that our proposed AdaptSFL framework takes considerably less time to achieve a target accuracy than benchmarks, demonstrating the effectiveness of the proposed strategies.
Pushing Large Language Models to the 6G Edge: Vision, Challenges, and Opportunities
Sep 28, 2023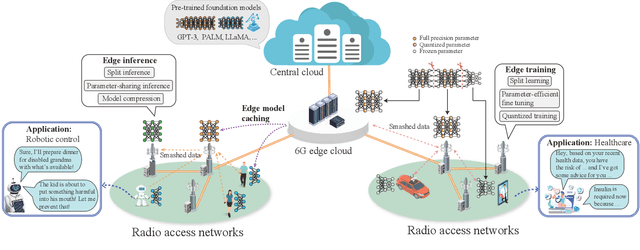
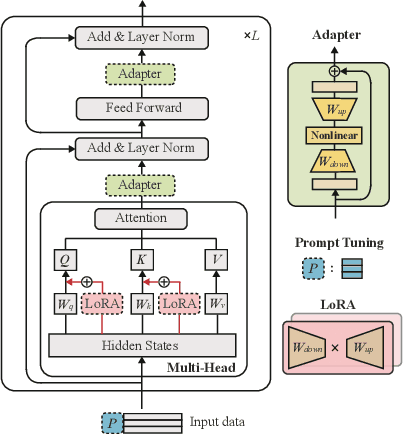

Large language models (LLMs), which have shown remarkable capabilities, are revolutionizing AI development and potentially shaping our future. However, given their multimodality, the status quo cloud-based deployment faces some critical challenges: 1) long response time; 2) high bandwidth costs; and 3) the violation of data privacy. 6G mobile edge computing (MEC) systems may resolve these pressing issues. In this article, we explore the potential of deploying LLMs at the 6G edge. We start by introducing killer applications powered by multimodal LLMs, including robotics and healthcare, to highlight the need for deploying LLMs in the vicinity of end users. Then, we identify the critical challenges for LLM deployment at the edge and envision the 6G MEC architecture for LLMs. Furthermore, we delve into two design aspects, i.e., edge training and edge inference for LLMs. In both aspects, considering the inherent resource limitations at the edge, we discuss various cutting-edge techniques, including split learning/inference, parameter-efficient fine-tuning, quantization, and parameter-sharing inference, to facilitate the efficient deployment of LLMs. This article serves as a position paper for thoroughly identifying the motivation, challenges, and pathway for empowering LLMs at the 6G edge.
Optimal Resource Allocation for U-Shaped Parallel Split Learning
Aug 17, 2023



Split learning (SL) has emerged as a promising approach for model training without revealing the raw data samples from the data owners. However, traditional SL inevitably leaks label privacy as the tail model (with the last layers) should be placed on the server. To overcome this limitation, one promising solution is to utilize U-shaped architecture to leave both early layers and last layers on the user side. In this paper, we develop a novel parallel U-shaped split learning and devise the optimal resource optimization scheme to improve the performance of edge networks. In the proposed framework, multiple users communicate with an edge server for SL. We analyze the end-to-end delay of each client during the training process and design an efficient resource allocation algorithm, called LSCRA, which finds the optimal computing resource allocation and split layers. Our experimental results show the effectiveness of LSCRA and that U-shaped PSL can achieve a similar performance with other SL baselines while preserving label privacy. Index Terms: U-shaped network, split learning, label privacy, resource allocation, 5G/6G edge networks.
Split Learning in 6G Edge Networks
Jun 24, 2023With the proliferation of distributed edge computing resources, the 6G mobile network will evolve into a network for connected intelligence. Along this line, the proposal to incorporate federated learning into the mobile edge has gained considerable interest in recent years. However, the deployment of federated learning faces substantial challenges as massive resource-limited IoT devices can hardly support on-device model training. This leads to the emergence of split learning (SL) which enables servers to handle the major training workload while still enhancing data privacy. In this article, we offer a brief overview of key advancements in SL and articulate its seamless integration with wireless edge networks. We begin by illustrating the tailored 6G architecture to support edge SL. Then, we examine the critical design issues for edge SL, including innovative resource-efficient learning frameworks and resource management strategies under a single edge server. Additionally, we expand the scope to multi-edge scenarios, exploring multi-edge collaboration and mobility management from a networking perspective. Finally, we discuss open problems for edge SL, including convergence analysis, asynchronous SL and U-shaped SL.