 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBelief States for Cooperative Multi-Agent Reinforcement Learning under Partial Observability
Apr 11, 2025Reinforcement learning in partially observable environments is typically challenging, as it requires agents to learn an estimate of the underlying system state. These challenges are exacerbated in multi-agent settings, where agents learn simultaneously and influence the underlying state as well as each others' observations. We propose the use of learned beliefs on the underlying state of the system to overcome these challenges and enable reinforcement learning with fully decentralized training and execution. Our approach leverages state information to pre-train a probabilistic belief model in a self-supervised fashion. The resulting belief states, which capture both inferred state information as well as uncertainty over this information, are then used in a state-based reinforcement learning algorithm to create an end-to-end model for cooperative multi-agent reinforcement learning under partial observability. By separating the belief and reinforcement learning tasks, we are able to significantly simplify the policy and value function learning tasks and improve both the convergence speed and the final performance. We evaluate our proposed method on diverse partially observable multi-agent tasks designed to exhibit different variants of partial observability.
Joint State-Action Embedding for Efficient Reinforcement Learning
Oct 12, 2020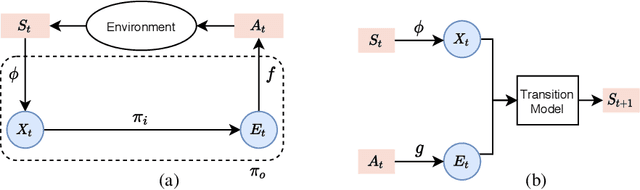
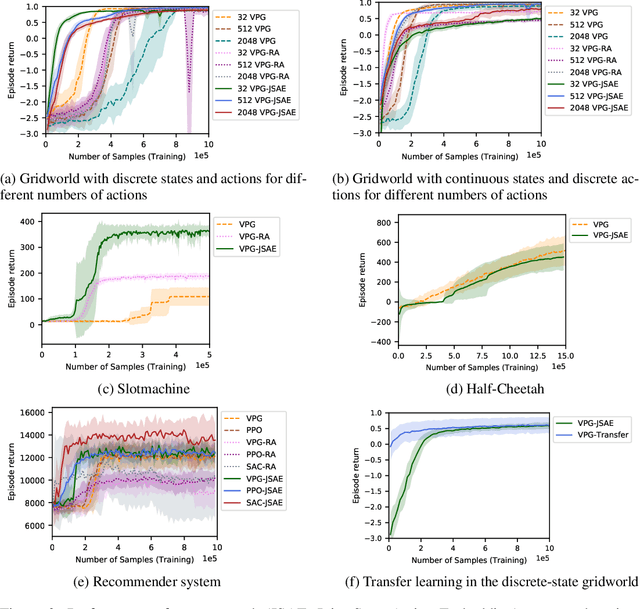
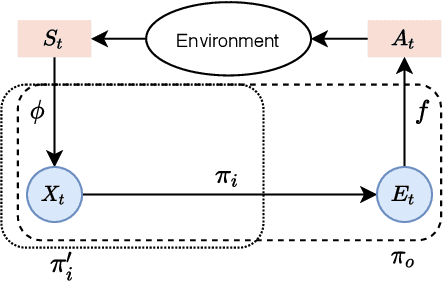
While reinforcement learning has achieved considerable successes in recent years, state-of-the-art models are often still limited by the size of state and action spaces. Model-free reinforcement learning approaches use some form of state representations and the latest work has explored embedding techniques for actions, both with the aim of achieving better generalization and applicability. However, these approaches consider only states or actions, ignoring the interaction between them when generating embedded representations. In this work, we propose a new approach for jointly embedding states and actions that combines aspects of model-free and model-based reinforcement learning, which can be applied in both discrete and continuous domains. Specifically, we use a model of the environment to obtain embeddings for states and actions and present a generic architecture that uses these to learn a policy. In this way, the embedded representations obtained via our approach enable better generalization over both states and actions by capturing similarities in the embedding spaces. Evaluations of our approach on several gaming and recommender system environments show it significantly outperforms state-of-the-art models in discrete domains with large state/action space, thus confirming the efficacy of joint embedding and its overall superior performance.
Fast-Fourier-Forecasting Resource Utilisation in Distributed Systems
Jan 25, 2020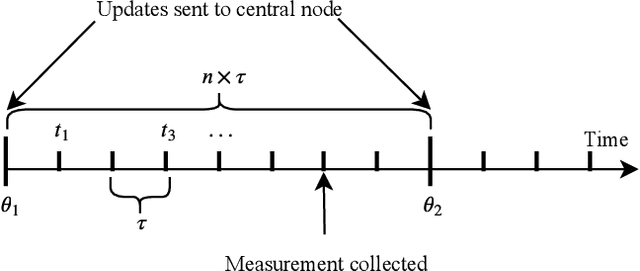
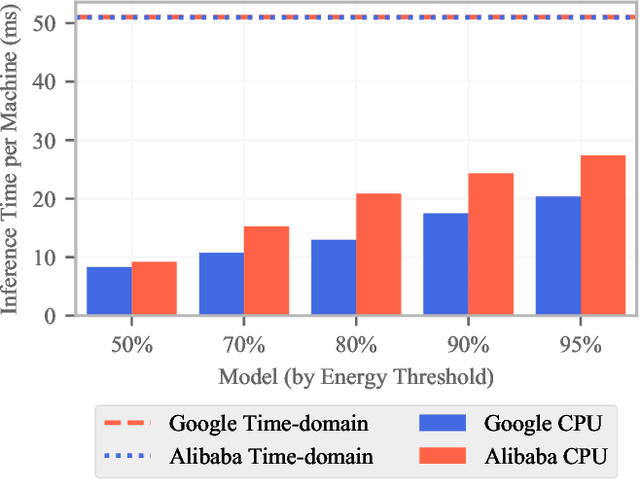
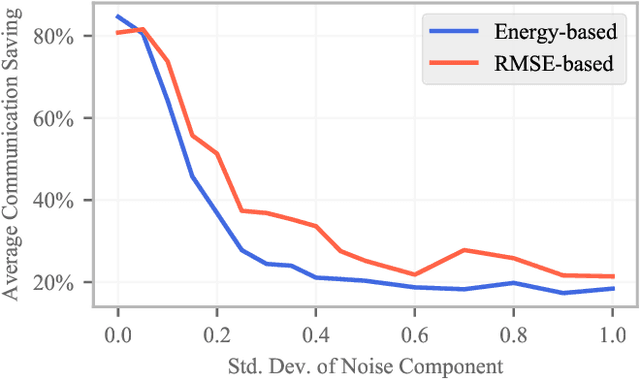
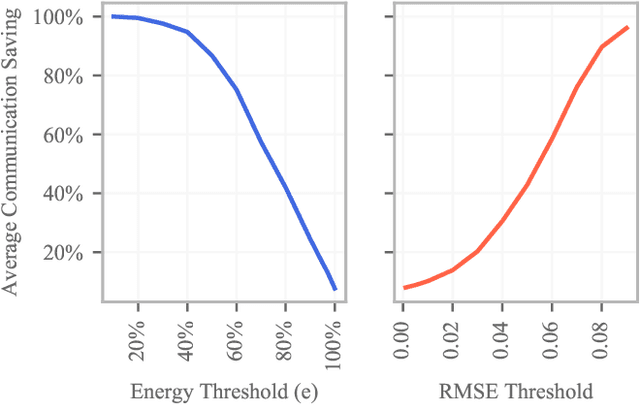
Distributed computing systems often consist of hundreds of nodes, executing tasks with different resource requirements. Efficient resource provisioning and task scheduling in such systems are non-trivial and require close monitoring and accurate forecasting of the state of the system, specifically resource utilisation at its constituent machines. Two challenges present themselves towards these objectives. First, collecting monitoring data entails substantial communication overhead. This overhead can be prohibitively high, especially in networks where bandwidth is limited. Second, forecasting models to predict resource utilisation should be accurate and need to exhibit high inference speed. Mission critical scheduling and resource allocation algorithms use these predictions and rely on their immediate availability. To address the first challenge, we present a communication-efficient data collection mechanism. Resource utilisation data is collected at the individual machines in the system and transmitted to a central controller in batches. Each batch is processed by an adaptive data-reduction algorithm based on Fourier transforms and truncation in the frequency domain. We show that the proposed mechanism leads to a significant reduction in communication overhead while incurring only minimal error and adhering to accuracy guarantees. To address the second challenge, we propose a deep learning architecture using complex Gated Recurrent Units to forecast resource utilisation. This architecture is directly integrated with the above data collection mechanism to improve inference speed of our forecasting model. Using two real-world datasets, we demonstrate the effectiveness of our approach, both in terms of forecasting accuracy and inference speed. Our approach resolves challenges encountered in resource provisioning frameworks and can be applied to other forecasting problems.