 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNanoBatch DPSGD: Exploring Differentially Private learning on ImageNet with low batch sizes on the IPU
Paper and Code

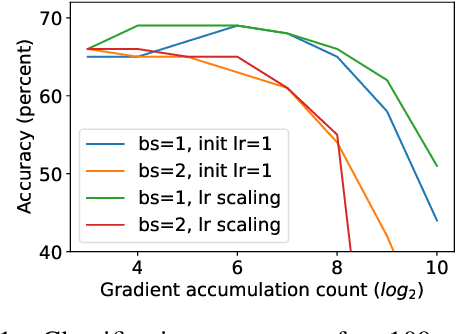
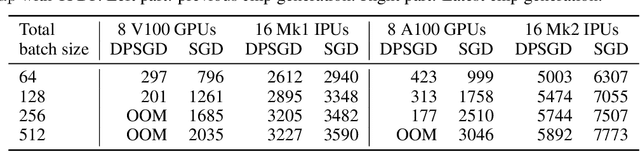

Differentially private SGD (DPSGD) has recently shown promise in deep learning. However, compared to non-private SGD, the DPSGD algorithm places computational overheads that can undo the benefit of batching in GPUs. Microbatching is a standard method to alleviate this and is fully supported in the TensorFlow Privacy library (TFDP). However, this technique, while improving training times also reduces the quality of the gradients and degrades the classification accuracy. Recent works that for example use the JAX framework show promise in also alleviating this but still show degradation in throughput from non-private to private SGD on CNNs, and have not yet shown ImageNet implementations. In our work, we argue that low batch sizes using group normalization on ResNet-50 can yield high accuracy and privacy on Graphcore IPUs. This enables DPSGD training of ResNet-50 on ImageNet in just 6 hours (100 epochs) on an IPU-POD16 system.