 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUWM-JEPA: Predictive World Models That Imagine in Belief Space
May 25, 2026World models for partially observed environments must imagine multiple compatible hidden futures and steer between them under counterfactual actions. Joint Embedding Predictive Architectures (JEPAs) do this in latent space, but a vector-valued latent has no internal structure for carrying the belief over hidden continuations through blind rollout. We introduce the Unitary World Model JEPA (UWM-JEPA), a JEPA world model with a density-matrix latent on a joint system-environment space and a learned unitary predictor. The construction preserves the joint-state spectrum exactly during rollout, so the predictor itself cannot dissipate the represented uncertainty. On a hidden-velocity indicator task requiring five-step forward simulation under a given action sequence with the target observation masked, UWM-JEPA reaches 0.77 accuracy and degrades monotonically as actions are perturbed; a parameter-matched LSTM-JEPA trained under the same counterfactual-target objective and action head collapses to majority-class accuracy (0.53) under every action condition. Under blind rollout, UWM-JEPA loses fewer than ten points of probe R^2 at short horizons while vector-latent baselines lose forty-one and sixty-eight; both nevertheless tie on a held-out context probe, locating the separation in the predictor rather than the encoder. Action sensitivity itself requires training against counterfactual rather than teacher-forced targets, a finding that applies beyond the unitary parameterisation. For JEPA world models to imagine under partial observability, latent geometry and predictor dynamics matter, not frozen context-encoding capacity alone.
Improving BM25 Code Retrieval Under Fixed Generic Tokenization: Adaptive q-Log Odds as a Drop-In BM25 Fix
May 18, 2026In retrieval-augmented coding, failures often begin when the relevant file is absent from the retrieved context. Under frozen generic tokenization, where a BM25 index has been built by a search system whose analyzer the practitioner does not control, this failure is routine: BM25's logarithmic RSJ-odds IDF under-separates the identifier tail that distinguishes one function from another. We replace the outer logarithm of the Robertson-Spärck-Jones odds with a q-logarithm. At q=1 the transform recovers BM25 exactly by L'Hôpital's rule, and for q<1 it is a Box-Cox transform of the RSJ odds with lambda = 1-q. On CoIR CodeSearchNet Go (182K documents), oracle-tuned NDCG@10 rises from 0.2575 to 0.4874 (absolute +0.2299; +89.3% relative; zero sign reversals in 10,000 paired-bootstrap resamples, reported as p <= 10^-4). The effect is graded across code languages and is near-zero on BEIR text. A one-parameter closed form estimates a corpus-level q from hapax density and stays near q=1 on corpora where BM25 is already optimal. The index-time cost is a single pass over the sparse score matrix and query latency is unchanged. A tokenizer ablation shows that identifier-aware tokenization largely removes the incremental gain from q-IDF.
Adaptive Graph of Thoughts: Test-Time Adaptive Reasoning Unifying Chain, Tree, and Graph Structures
Feb 07, 2025Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, yet their performance is highly dependent on the prompting strategy and model scale. While reinforcement learning and fine-tuning have been deployed to boost reasoning, these approaches incur substantial computational and data overhead. In this work, we introduce Adaptive Graph of Thoughts (AGoT), a dynamic, graph-based inference framework that enhances LLM reasoning solely at test time. Rather than relying on fixed-step methods like Chain of Thought (CoT) or Tree of Thoughts (ToT), AGoT recursively decomposes complex queries into structured subproblems, forming an dynamic directed acyclic graph (DAG) of interdependent reasoning steps. By selectively expanding only those subproblems that require further analysis, AGoT unifies the strengths of chain, tree, and graph paradigms into a cohesive framework that allocates computation where it is most needed. We validate our approach on diverse benchmarks spanning multi-hop retrieval, scientific reasoning, and mathematical problem-solving, achieving up to 46.2% improvement on scientific reasoning tasks (GPQA) - comparable to gains achieved through computationally intensive reinforcement learning approaches and outperforming state-of-the-art iterative approaches. These results suggest that dynamic decomposition and structured recursion offer a scalable, cost-effective alternative to post-training modifications, paving the way for more robust, general-purpose reasoning in LLMs.
On the Reasoning Capacity of AI Models and How to Quantify It
Jan 23, 2025Recent advances in Large Language Models (LLMs) have intensified the debate surrounding the fundamental nature of their reasoning capabilities. While achieving high performance on benchmarks such as GPQA and MMLU, these models exhibit limitations in more complex reasoning tasks, highlighting the need for more rigorous evaluation methodologies. We propose a novel phenomenological approach that goes beyond traditional accuracy metrics to probe the underlying mechanisms of model behavior, establishing a framework that could broadly impact how we analyze and understand AI systems. Using positional bias in multiple-choice reasoning tasks as a case study, we demonstrate how systematic perturbations can reveal fundamental aspects of model decision-making. To analyze these behaviors, we develop two complementary phenomenological models: a Probabilistic Mixture Model (PMM) that decomposes model responses into reasoning, memorization, and guessing components and an Information-Theoretic Consistency (ITC) analysis that quantifies the relationship between model confidence and strategy selection. Through controlled experiments on reasoning benchmarks, we show that true reasoning remains challenging for current models, with apparent success often relying on sophisticated combinations of memorization and pattern matching rather than genuine logical deduction. More fundamentally, we demonstrate that accuracy alone often overstates a model's reasoning abilities, as model behavior can be characterized through underlying mechanisms in the phase space of cognitive strategies, revealing how models dynamically balance different approaches when responding to queries. This framework enables quantitative criteria for real-world deployments, allowing applications to specify reliability thresholds based on strategy distributions rather than aggregate performance metrics.
Composite Learning Units: Generalized Learning Beyond Parameter Updates to Transform LLMs into Adaptive Reasoners
Oct 09, 2024Human learning thrives on the ability to learn from mistakes, adapt through feedback, and refine understanding-processes often missing in static machine learning models. In this work, we introduce Composite Learning Units (CLUs) designed to transform reasoners, such as Large Language Models (LLMs), into learners capable of generalized, continuous learning without conventional parameter updates while enhancing their reasoning abilities through continual interaction and feedback. CLUs are built on an architecture that allows a reasoning model to maintain and evolve a dynamic knowledge repository: a General Knowledge Space for broad, reusable insights and a Prompt-Specific Knowledge Space for task-specific learning. Through goal-driven interactions, CLUs iteratively refine these knowledge spaces, enabling the system to adapt dynamically to complex tasks, extract nuanced insights, and build upon past experiences autonomously. We demonstrate CLUs' effectiveness through a cryptographic reasoning task, where they continuously evolve their understanding through feedback to uncover hidden transformation rules. While conventional models struggle to grasp underlying logic, CLUs excel by engaging in an iterative, goal-oriented process. Specialized components-handling knowledge retrieval, prompt generation, and feedback analysis-work together within a reinforcing feedback loop. This approach allows CLUs to retain the memory of past failures and successes, adapt autonomously, and apply sophisticated reasoning effectively, continually learning from mistakes while also building on breakthroughs.
A quantum generative model for multi-dimensional time series using Hamiltonian learning
Apr 13, 2022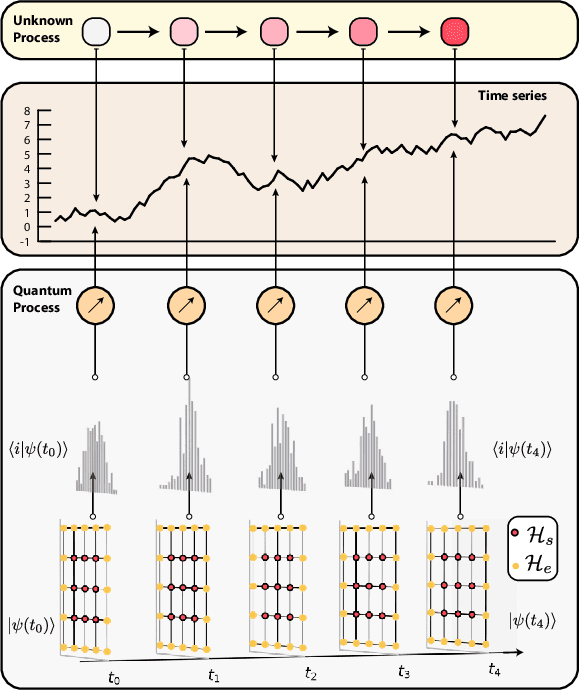
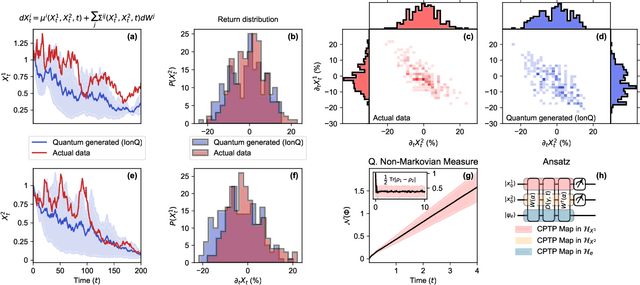
Synthetic data generation has proven to be a promising solution for addressing data availability issues in various domains. Even more challenging is the generation of synthetic time series data, where one has to preserve temporal dynamics, i.e., the generated time series must respect the original relationships between variables across time. Recently proposed techniques such as generative adversarial networks (GANs) and quantum-GANs lack the ability to attend to the time series specific temporal correlations adequately. We propose using the inherent nature of quantum computers to simulate quantum dynamics as a technique to encode such features. We start by assuming that a given time series can be generated by a quantum process, after which we proceed to learn that quantum process using quantum machine learning. We then use the learned model to generate out-of-sample time series and show that it captures unique and complex features of the learned time series. We also study the class of time series that can be modeled using this technique. Finally, we experimentally demonstrate the proposed algorithm on an 11-qubit trapped-ion quantum machine.
Generalized quantum similarity learning
Jan 07, 2022



The similarity between objects is significant in a broad range of areas. While similarity can be measured using off-the-shelf distance functions, they may fail to capture the inherent meaning of similarity, which tends to depend on the underlying data and task. Moreover, conventional distance functions limit the space of similarity measures to be symmetric and do not directly allow comparing objects from different spaces. We propose using quantum networks (GQSim) for learning task-dependent (a)symmetric similarity between data that need not have the same dimensionality. We analyze the properties of such similarity function analytically (for a simple case) and numerically (for a complex case) and showthat these similarity measures can extract salient features of the data. We also demonstrate that the similarity measure derived using this technique is $(\epsilon,\gamma,\tau)$-good, resulting in theoretically guaranteed performance. Finally, we conclude by applying this technique for three relevant applications - Classification, Graph Completion, Generative modeling.