 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Prompting Suppresses Overthinking Reasoning Under Constraint: How Batch Prompting Suppresses Overthinking in Reasoning Models
Nov 06, 2025Recent work has explored batch prompting as a strategy to amortize inference cost in large language models (LLMs). In this paper, we show that batching offers an additional, underappreciated benefit: it regularizes model behavior during multi-step reasoning for Large Reasoning Models (LRMs). We conduct a comprehensive study across 13 diverse benchmarks and observe that batching improves accuracy while substantially reducing reasoning token usage, often by 3x-5x. Through detailed behavioral analysis, we find that batching suppresses overthinking, reduces hedging language (e.g., repetitive self-corrections), and encourages more decisive answers. Surprisingly, we also observe emergent collective effects in batched inference: models often generalize patterns from earlier examples to solve harder ones in the same batch. These findings position batching not just as a throughput optimization, but as a powerful inference-time regularizer for more efficient and reliable LLM reasoning.
Real-Time Performance Benchmarking of TinyML Models in Embedded Systems (PICO: Performance of Inference, CPU, and Operations)
Sep 05, 2025



This paper presents PICO-TINYML-BENCHMARK, a modular and platform-agnostic framework for benchmarking the real-time performance of TinyML models on resource-constrained embedded systems. Evaluating key metrics such as inference latency, CPU utilization, memory efficiency, and prediction stability, the framework provides insights into computational trade-offs and platform-specific optimizations. We benchmark three representative TinyML models -- Gesture Classification, Keyword Spotting, and MobileNet V2 -- on two widely adopted platforms, BeagleBone AI64 and Raspberry Pi 4, using real-world datasets. Results reveal critical trade-offs: the BeagleBone AI64 demonstrates consistent inference latency for AI-specific tasks, while the Raspberry Pi 4 excels in resource efficiency and cost-effectiveness. These findings offer actionable guidance for optimizing TinyML deployments, bridging the gap between theoretical advancements and practical applications in embedded systems.
Essential-Web v1.0: 24T tokens of organized web data
Jun 17, 2025

Data plays the most prominent role in how language models acquire skills and knowledge. The lack of massive, well-organized pre-training datasets results in costly and inaccessible data pipelines. We present Essential-Web v1.0, a 24-trillion-token dataset in which every document is annotated with a twelve-category taxonomy covering topic, format, content complexity, and quality. Taxonomy labels are produced by EAI-Distill-0.5b, a fine-tuned 0.5b-parameter model that achieves an annotator agreement within 3% of Qwen2.5-32B-Instruct. With nothing more than SQL-style filters, we obtain competitive web-curated datasets in math (-8.0% relative to SOTA), web code (+14.3%), STEM (+24.5%) and medical (+8.6%). Essential-Web v1.0 is available on HuggingFace: https://huggingface.co/datasets/EssentialAI/essential-web-v1.0
Multimodal Event Detection: Current Approaches and Defining the New Playground through LLMs and VLMs
May 16, 2025In this paper, we study the challenges of detecting events on social media, where traditional unimodal systems struggle due to the rapid and multimodal nature of data dissemination. We employ a range of models, including unimodal ModernBERT and ConvNeXt-V2, multimodal fusion techniques, and advanced generative models like GPT-4o, and LLaVA. Additionally, we also study the effect of providing multimodal generative models (such as GPT-4o) with a single modality to assess their efficacy. Our results indicate that while multimodal approaches notably outperform unimodal counterparts, generative approaches despite having a large number of parameters, lag behind supervised methods in precision. Furthermore, we also found that they lag behind instruction-tuned models because of their inability to generate event classes correctly. During our error analysis, we discovered that common social media issues such as leet speak, text elongation, etc. are effectively handled by generative approaches but are hard to tackle using supervised approaches.
Practical Efficiency of Muon for Pretraining
May 04, 2025We demonstrate that Muon, the simplest instantiation of a second-order optimizer, explicitly expands the Pareto frontier over AdamW on the compute-time tradeoff. We find that Muon is more effective than AdamW in retaining data efficiency at large batch sizes, far beyond the so-called critical batch size, while remaining computationally efficient, thus enabling more economical training. We study the combination of Muon and the maximal update parameterization (muP) for efficient hyperparameter transfer and present a simple telescoping algorithm that accounts for all sources of error in muP while introducing only a modest overhead in resources. We validate our findings through extensive experiments with model sizes up to four billion parameters and ablations on the data distribution and architecture.
Compositional Image-Text Matching and Retrieval by Grounding Entities
May 04, 2025

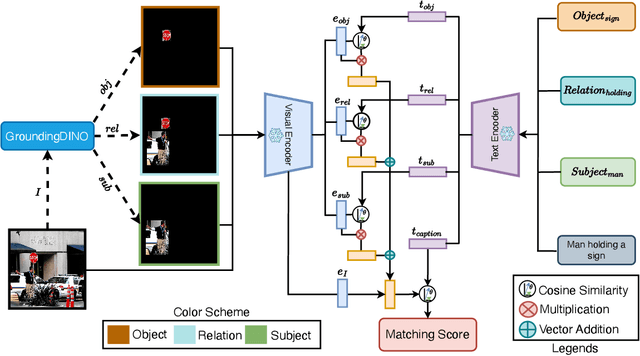
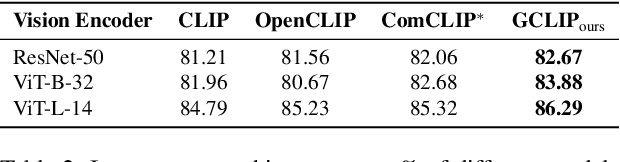
Vision-language pretraining on large datasets of images-text pairs is one of the main building blocks of current Vision-Language Models. While with additional training, these models excel in various downstream tasks, including visual question answering, image captioning, and visual commonsense reasoning. However, a notable weakness of pretrained models like CLIP, is their inability to perform entity grounding and compositional image and text matching~\cite{Jiang2024ComCLIP, yang2023amc, Rajabi2023GroundedVSR, learninglocalizeCVPR24}. In this work we propose a novel learning-free zero-shot augmentation of CLIP embeddings that has favorable compositional properties. We compute separate embeddings of sub-images of object entities and relations that are localized by the state of the art open vocabulary detectors and dynamically adjust the baseline global image embedding. % The final embedding is obtained by computing a weighted combination of the sub-image embeddings. The resulting embedding is then utilized for similarity computation with text embedding, resulting in a average 1.5\% improvement in image-text matching accuracy on the Visual Genome and SVO Probes datasets~\cite{krishna2017visualgenome, svo}. Notably, the enhanced embeddings demonstrate superior retrieval performance, thus achieving significant gains on the Flickr30K and MS-COCO retrieval benchmarks~\cite{flickr30ke, mscoco}, improving the state-of-the-art Recall@1 by 12\% and 0.4\%, respectively. Our code is available at https://github.com/madhukarreddyvongala/GroundingCLIP.
Revisiting Prompt Optimization with Large Reasoning Models-A Case Study on Event Extraction
Apr 10, 2025Large Reasoning Models (LRMs) such as DeepSeek-R1 and OpenAI o1 have demonstrated remarkable capabilities in various reasoning tasks. Their strong capability to generate and reason over intermediate thoughts has also led to arguments that they may no longer require extensive prompt engineering or optimization to interpret human instructions and produce accurate outputs. In this work, we aim to systematically study this open question, using the structured task of event extraction for a case study. We experimented with two LRMs (DeepSeek-R1 and o1) and two general-purpose Large Language Models (LLMs) (GPT-4o and GPT-4.5), when they were used as task models or prompt optimizers. Our results show that on tasks as complicated as event extraction, LRMs as task models still benefit from prompt optimization, and that using LRMs as prompt optimizers yields more effective prompts. Finally, we provide an error analysis of common errors made by LRMs and highlight the stability and consistency of LRMs in refining task instructions and event guidelines.
Rethinking Reflection in Pre-Training
Apr 05, 2025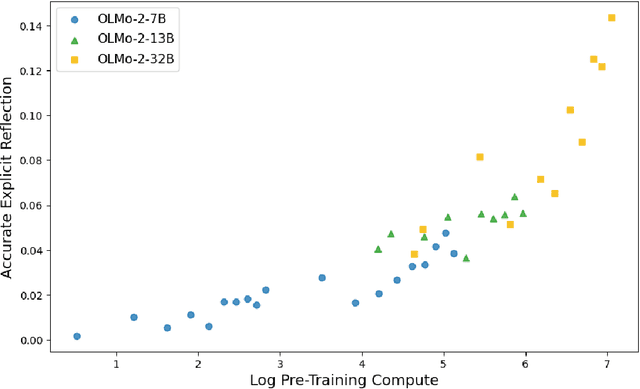
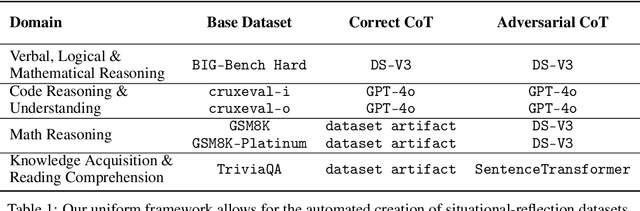
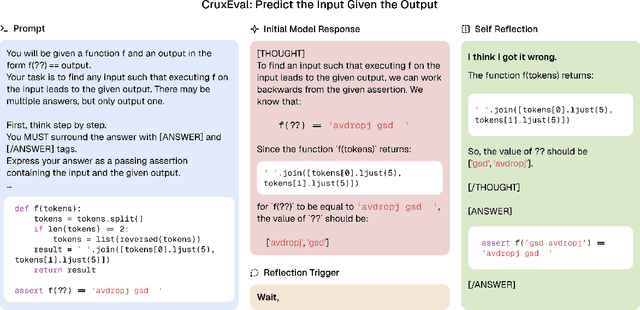
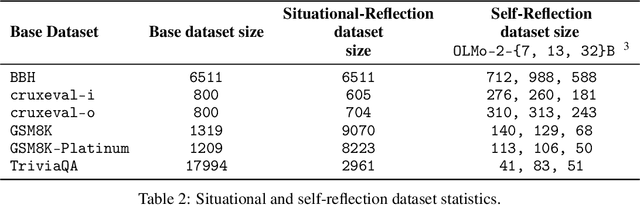
A language model's ability to reflect on its own reasoning provides a key advantage for solving complex problems. While most recent research has focused on how this ability develops during reinforcement learning, we show that it actually begins to emerge much earlier - during the model's pre-training. To study this, we introduce deliberate errors into chains-of-thought and test whether the model can still arrive at the correct answer by recognizing and correcting these mistakes. By tracking performance across different stages of pre-training, we observe that this self-correcting ability appears early and improves steadily over time. For instance, an OLMo2-7B model pre-trained on 4 trillion tokens displays self-correction on our six self-reflection tasks.
Instruction-Tuning LLMs for Event Extraction with Annotation Guidelines
Feb 22, 2025In this work, we study the effect of annotation guidelines -- textual descriptions of event types and arguments, when instruction-tuning large language models for event extraction. We conducted a series of experiments with both human-provided and machine-generated guidelines in both full- and low-data settings. Our results demonstrate the promise of annotation guidelines when there is a decent amount of training data and highlight its effectiveness in improving cross-schema generalization and low-frequency event-type performance.
Functional Benchmarks for Robust Evaluation of Reasoning Performance, and the Reasoning Gap
Feb 29, 2024



We propose a framework for robust evaluation of reasoning capabilities of language models, using functional variants of benchmarks. Models that solve a reasoning test should exhibit no difference in performance over the static version of a problem compared to a snapshot of the functional variant. We have rewritten the relevant fragment of the MATH benchmark into its functional variant MATH(), with functionalization of other benchmarks to follow. When evaluating current state-of-the-art models over snapshots of MATH(), we find a reasoning gap -- the percentage difference between the static and functional accuracies. We find reasoning gaps from 58.35% to 80.31% among the state-of-the-art closed and open weights models that perform well on static benchmarks, with the caveat that the gaps are likely to be smaller with more sophisticated prompting strategies. Here we show that models which anecdotally have good reasoning performance over real-world tasks, have quantifiable lower gaps, motivating the open problem of building "gap 0" models. Code for evaluation and new evaluation datasets, three MATH() snapshots, are publicly available at https://github.com/consequentai/fneval/.