 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance Needs More Care: Rewriting Prompts for Instances Yields Better Zero-Shot Performance
Oct 05, 2023



Enabling large language models (LLMs) to perform tasks in zero-shot has been an appealing goal owing to its labor-saving (i.e., requiring no task-specific annotations); as such, zero-shot prompting approaches also enjoy better task generalizability. To improve LLMs' zero-shot performance, prior work has focused on devising more effective task instructions (e.g., ``let's think step by step'' ). However, we argue that, in order for an LLM to solve them correctly in zero-shot, individual test instances need more carefully designed and customized instructions. To this end, we propose PRoMPTd, an approach that rewrites the task prompt for each individual test input to be more specific, unambiguous, and complete, so as to provide better guidance to the task LLM. We evaluated PRoMPTd on eight datasets covering tasks including arithmetics, logical reasoning, and code generation, using GPT-4 as the task LLM. Notably, PRoMPTd achieves an absolute improvement of around 10% on the complex MATH dataset and 5% on the code generation task on HumanEval, outperforming conventional zero-shot methods. In addition, we also showed that the rewritten prompt can provide better interpretability of how the LLM resolves each test instance, which can potentially be leveraged as a defense mechanism against adversarial prompting. The source code and dataset can be obtained from https://github.com/salokr/PRoMPTd
A Surrogate-based Generic Classifier for Chinese TV Series Reviews
Nov 21, 2016
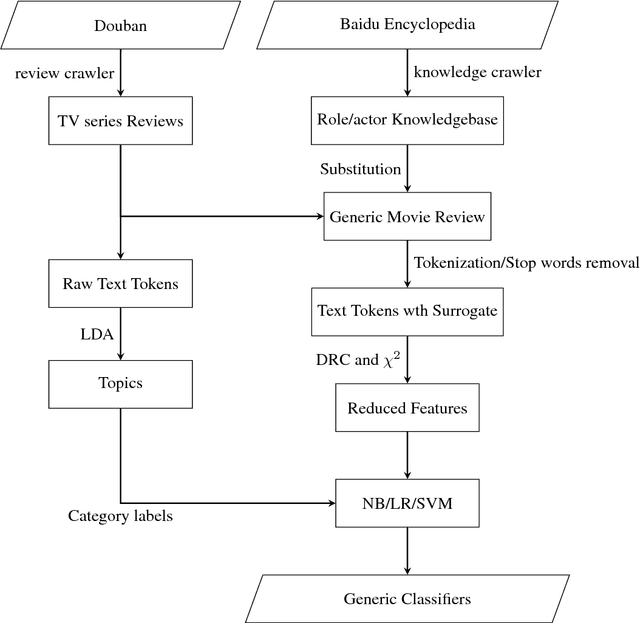
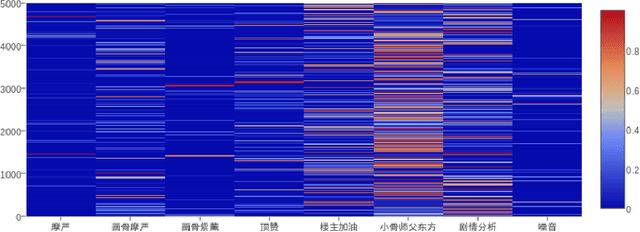

With the emerging of various online video platforms like Youtube, Youku and LeTV, online TV series' reviews become more and more important both for viewers and producers. Customers rely heavily on these reviews before selecting TV series, while producers use them to improve the quality. As a result, automatically classifying reviews according to different requirements evolves as a popular research topic and is essential in our daily life. In this paper, we focused on reviews of hot TV series in China and successfully trained generic classifiers based on eight predefined categories. The experimental results showed promising performance and effectiveness of its generalization to different TV series.