 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Limitations of the Transformer Architecture
Feb 26, 2024


What are the root causes of hallucinations in large language models (LLMs)? We use Communication Complexity to prove that the Transformer layer is incapable of composing functions (e.g., identify a grandparent of a person in a genealogy) if the domains of the functions are large enough; we show through examples that this inability is already empirically present when the domains are quite small. We also point out that several mathematical tasks that are at the core of the so-called compositional tasks thought to be hard for LLMs are unlikely to be solvable by Transformers, for large enough instances and assuming that certain well accepted conjectures in the field of Computational Complexity are true.
UGIF: UI Grounded Instruction Following
Nov 14, 2022



New smartphone users have difficulty engaging with it and often use only a limited set of features like calling and messaging. These users are hesitant to explore using the smartphone and rely on experienced users to teach them how to use the phone. However, experienced users are not always around to guide them. To help new users learn how to use the phone on their own, we propose a natural language based instruction following agent that operates over the UI and shows the user how to perform various tasks. Common how-to questions, such as "How to block calls from unknown numbers?", are documented on support sites with a sequence of steps in natural language describing what the user should do. We parse these steps using Large Language Models (LLMs) and generate macros that can be executed on-device when the user asks a query. To evaluate this agent, we introduce UGIF-DataSet, a multi-lingual, multi-modal UI grounded dataset for step-by-step task completion on the smartphone. It contains 523 natural language instructions with paired sequences of multilingual UI screens and actions that show how to execute the task in eight languages. We compare the performance of different large language models including PaLM, GPT3, etc. and find that the end-to-end task completion success rate is 48% for English UI but the performance drops to 32% for non-English languages. We analyse the common failure modes of existing models on this task and point out areas for improvement.
MiQA: A Benchmark for Inference on Metaphorical Questions
Oct 14, 2022


We propose a benchmark to assess the capability of large language models to reason with conventional metaphors. Our benchmark combines the previously isolated topics of metaphor detection and commonsense reasoning into a single task that requires a model to make inferences by accurately selecting between the literal and metaphorical register. We examine the performance of state-of-the-art pre-trained models on binary-choice tasks and find a large discrepancy between the performance of small and very large models, going from chance to near-human level. We also analyse the largest model in a generative setting and find that although human performance is approached, careful multiple-shot prompting is required.
Real-Time Sign Language Detection using Human Pose Estimation
Sep 13, 2020



We propose a lightweight real-time sign language detection model, as we identify the need for such a case in videoconferencing. We extract optical flow features based on human pose estimation and, using a linear classifier, show these features are meaningful with an accuracy of 80%, evaluated on the DGS Corpus. Using a recurrent model directly on the input, we see improvements of up to 91% accuracy, while still working under 4ms. We describe a demo application to sign language detection in the browser in order to demonstrate its usage possibility in videoconferencing applications.
Stiffness: A New Perspective on Generalization in Neural Networks
Jan 28, 2019
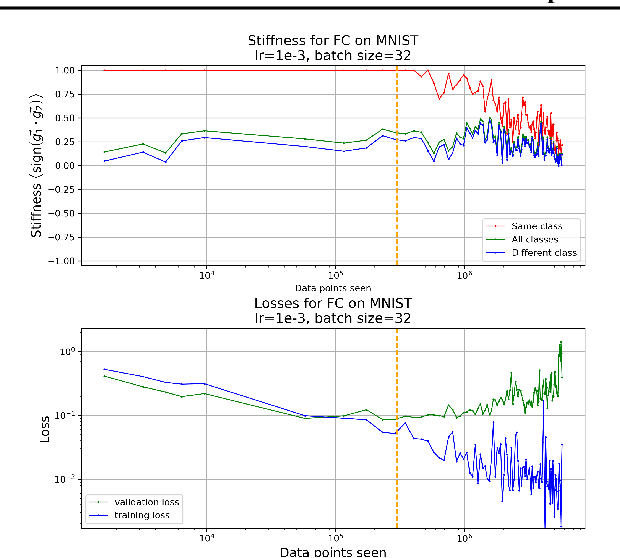
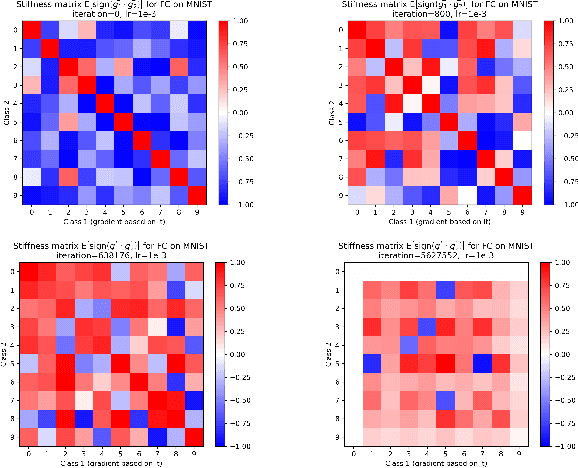
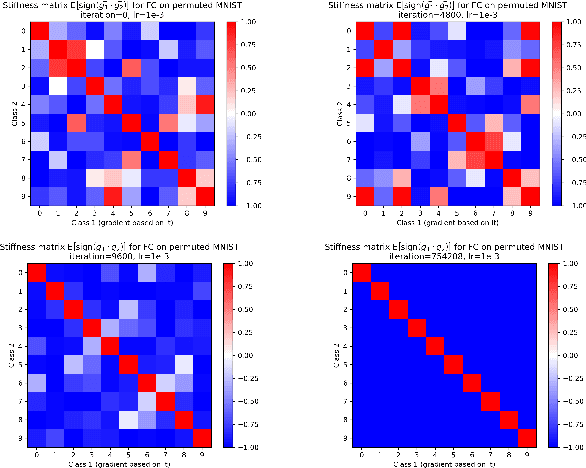
We investigate neural network training and generalization using the concept of stiffness. We measure how stiff a network is by looking at how a small gradient step on one example affects the loss on another example. In particular, we study how stiffness varies with 1) class membership, 2) distance between data points (in the input space as well as in latent spaces), 3) training iteration, and 4) learning rate. We empirically study the evolution of stiffness on MNIST, FASHION MNIST, CIFAR-10 and CIFAR-100 using fully-connected and convolutional neural networks. Our results demonstrate that stiffness is a useful concept for diagnosing and characterizing generalization. We observe that small learning rates lead to initial learning of more specific features that do not translate well to improvements on inputs from all classes, whereas high learning rates initially benefit all classes at once. We measure stiffness as a function of distance between data points and observe that higher learning rates induce positive correlation between changes in loss further apart, pointing towards a regularization effect of learning rate. When training on CIFAR-100, the stiffness matrix exhibits a coarse-grained behavior suggestive of the model's awareness of super-class membership.