 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAN: A World Model for General, Interactable, and Long-Horizon World Simulation
Nov 15, 2025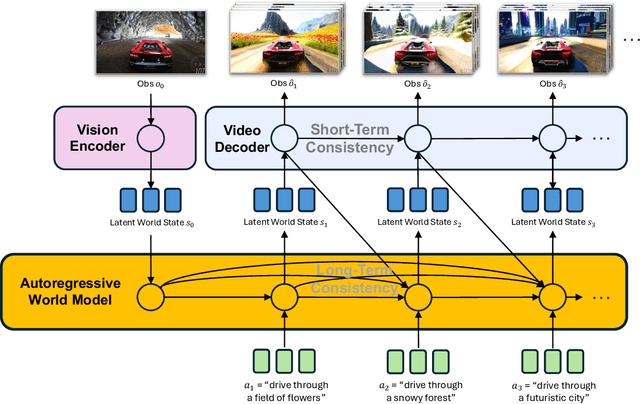
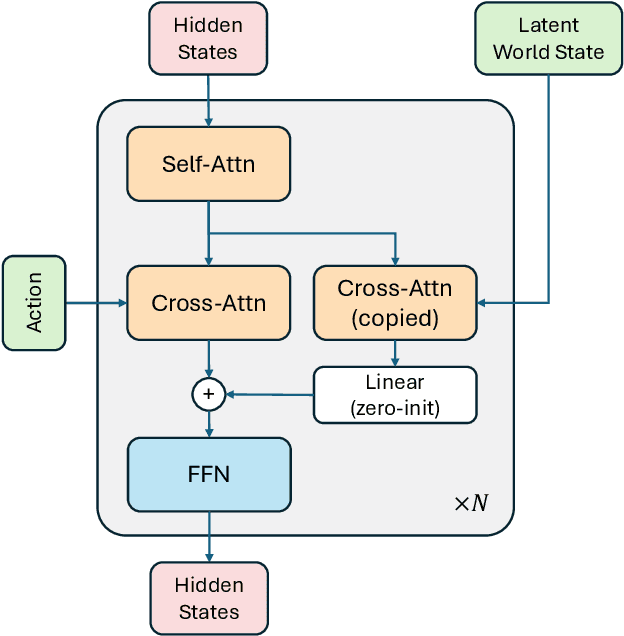
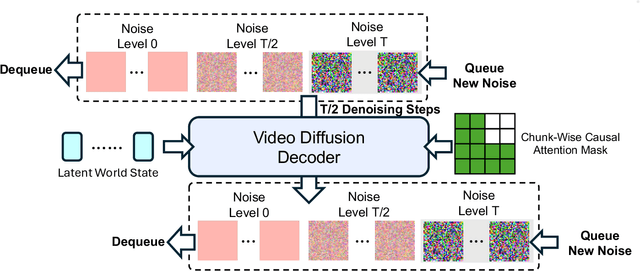
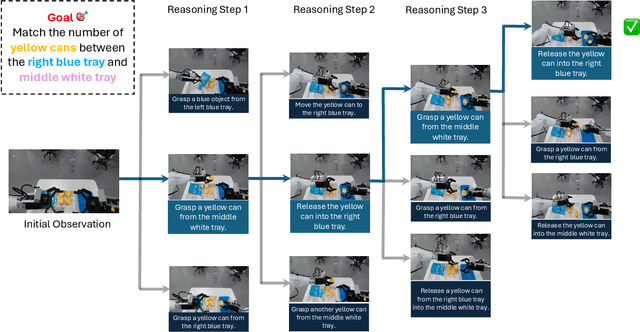
A world model enables an intelligent agent to imagine, predict, and reason about how the world evolves in response to its actions, and accordingly to plan and strategize. While recent video generation models produce realistic visual sequences, they typically operate in the prompt-to-full-video manner without causal control, interactivity, or long-horizon consistency required for purposeful reasoning. Existing world modeling efforts, on the other hand, often focus on restricted domains (e.g., physical, game, or 3D-scene dynamics) with limited depth and controllability, and struggle to generalize across diverse environments and interaction formats. In this work, we introduce PAN, a general, interactable, and long-horizon world model that predicts future world states through high-quality video simulation conditioned on history and natural language actions. PAN employs the Generative Latent Prediction (GLP) architecture that combines an autoregressive latent dynamics backbone based on a large language model (LLM), which grounds simulation in extensive text-based knowledge and enables conditioning on language-specified actions, with a video diffusion decoder that reconstructs perceptually detailed and temporally coherent visual observations, to achieve a unification between latent space reasoning (imagination) and realizable world dynamics (reality). Trained on large-scale video-action pairs spanning diverse domains, PAN supports open-domain, action-conditioned simulation with coherent, long-term dynamics. Extensive experiments show that PAN achieves strong performance in action-conditioned world simulation, long-horizon forecasting, and simulative reasoning compared to other video generators and world models, taking a step towards general world models that enable predictive simulation of future world states for reasoning and acting.
Block-level Text Spotting with LLMs
Jun 19, 2024Text spotting has seen tremendous progress in recent years yielding performant techniques which can extract text at the character, word or line level. However, extracting blocks of text from images (block-level text spotting) is relatively unexplored. Blocks contain more context than individual lines, words or characters and so block-level text spotting would enhance downstream applications, such as translation, which benefit from added context. We propose a novel method, BTS-LLM (Block-level Text Spotting with LLMs), to identify text at the block level. BTS-LLM has three parts: 1) detecting and recognizing text at the line level, 2) grouping lines into blocks and 3) finding the best order of lines within a block using a large language model (LLM). We aim to exploit the strong semantic knowledge in LLMs for accurate block-level text spotting. Consequently if the text spotted is semantically meaningful but has been corrupted during text recognition, the LLM is also able to rectify mistakes in the text and produce a reconstruction of it.