 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Critical Training
Mar 09, 2026Training large language models (LLMs) as autonomous agents often begins with imitation learning, but it only teaches agents what to do without understanding why: agents never contrast successful actions against suboptimal alternatives and thus lack awareness of action quality. Recent approaches attempt to address this by introducing self-reflection supervision derived from contrasts between expert and alternative actions. However, the training paradigm fundamentally remains imitation learning: the model imitates pre-constructed reflection text rather than learning to reason autonomously. We propose Agentic Critical Training (ACT), a reinforcement learning paradigm that trains agents to identify the better action among alternatives. By rewarding whether the model's judgment is correct, ACT drives the model to autonomously develop reasoning about action quality, producing genuine self-reflection rather than imitating it. Across three challenging agent benchmarks, ACT consistently improves agent performance when combined with different post-training methods. It achieves an average improvement of 5.07 points over imitation learning and 4.62 points over reinforcement learning. Compared to approaches that inject reflection capability through knowledge distillation, ACT also demonstrates clear advantages, yielding an average improvement of 2.42 points. Moreover, ACT enables strong out-of-distribution generalization on agentic benchmarks and improves performance on general reasoning benchmarks without any reasoning-specific training data, highlighting the value of our method. These results suggest that ACT is a promising path toward developing more reflective and capable LLM agents.
PersonaLedger: Generating Realistic Financial Transactions with Persona Conditioned LLMs and Rule Grounded Feedback
Jan 06, 2026Strict privacy regulations limit access to real transaction data, slowing open research in financial AI. Synthetic data can bridge this gap, but existing generators do not jointly achieve behavioral diversity and logical groundedness. Rule-driven simulators rely on hand-crafted workflows and shallow stochasticity, which miss the richness of human behavior. Learning-based generators such as GANs capture correlations yet often violate hard financial constraints and still require training on private data. We introduce PersonaLedger, a generation engine that uses a large language model conditioned on rich user personas to produce diverse transaction streams, coupled with an expert configurable programmatic engine that maintains correctness. The LLM and engine interact in a closed loop: after each event, the engine updates the user state, enforces financial rules, and returns a context aware "nextprompt" that guides the LLM toward feasible next actions. With this engine, we create a public dataset of 30 million transactions from 23,000 users and a benchmark suite with two tasks, illiquidity classification and identity theft segmentation. PersonaLedger offers a realistic, privacy preserving resource that supports rigorous evaluation of forecasting and anomaly detection models. PersonaLedger offers the community a rich, realistic, and privacy preserving resource -- complete with code, rules, and generation logs -- to accelerate innovation in financial AI and enable rigorous, reproducible evaluation.
Hold Onto That Thought: Assessing KV Cache Compression On Reasoning
Dec 12, 2025Large language models (LLMs) have demonstrated remarkable performance on long-context tasks, but are often bottlenecked by memory constraints. Namely, the KV cache, which is used to significantly speed up attention computations, grows linearly with context length. A suite of compression algorithms has been introduced to alleviate cache growth by evicting unimportant tokens. However, several popular strategies are targeted towards the prefill phase, i.e., processing long prompt context, and their performance is rarely assessed on reasoning tasks requiring long decoding. In particular, short but complex prompts, such as those in benchmarks like GSM8K and MATH500, often benefit from multi-step reasoning and self-reflection, resulting in thinking sequences thousands of tokens long. In this work, we benchmark the performance of several popular compression strategies on long-reasoning tasks. For the non-reasoning Llama-3.1-8B-Instruct, we determine that no singular strategy fits all, and that performance is heavily influenced by dataset type. However, we discover that H2O and our decoding-enabled variant of SnapKV are dominant strategies for reasoning models, indicating the utility of heavy-hitter tracking for reasoning traces. We also find that eviction strategies at low budgets can produce longer reasoning traces, revealing a tradeoff between cache size and inference costs.
MORSE-500: A Programmatically Controllable Video Benchmark to Stress-Test Multimodal Reasoning
Jun 05, 2025Despite rapid advances in vision-language models (VLMs), current benchmarks for multimodal reasoning fall short in three key dimensions. First, they overwhelmingly rely on static images, failing to capture the temporal complexity of real-world environments. Second, they narrowly focus on mathematical problem-solving, neglecting the broader spectrum of reasoning skills -- including abstract, physical, planning, spatial, and temporal capabilities -- required for robust multimodal intelligence. Third, many benchmarks quickly saturate, offering limited headroom for diagnosing failure modes or measuring continued progress. We introduce MORSE-500 (Multimodal Reasoning Stress-test Environment), a video benchmark composed of 500 fully scripted clips with embedded questions spanning six complementary reasoning categories. Each instance is programmatically generated using deterministic Python scripts (via Manim, Matplotlib, MoviePy), generative video models, and curated real footage. This script-driven design allows fine-grained control over visual complexity, distractor density, and temporal dynamics -- enabling difficulty to be scaled systematically as models improve. Unlike static benchmarks that become obsolete once saturated, MORSE-500 is built to evolve: its controllable generation pipeline supports the creation of arbitrarily challenging new instances, making it ideally suited for stress-testing next-generation models. Initial experiments with state-of-the-art systems -- including various Gemini 2.5 Pro and OpenAI o3 which represent the strongest available at the time, alongside strong open-source models -- reveal substantial performance gaps across all categories, with particularly large deficits in abstract and planning tasks. We release the full dataset, generation scripts, and evaluation harness to support transparent, reproducible, and forward-looking multimodal reasoning research.
HashEvict: A Pre-Attention KV Cache Eviction Strategy using Locality-Sensitive Hashing
Dec 24, 2024



Transformer-based large language models (LLMs) use the key-value (KV) cache to significantly accelerate inference by storing the key and value embeddings of past tokens. However, this cache consumes significant GPU memory. In this work, we introduce HashEvict, an algorithm that uses locality-sensitive hashing (LSH) to compress the KV cache. HashEvict quickly locates tokens in the cache that are cosine dissimilar to the current query token. This is achieved by computing the Hamming distance between binarized Gaussian projections of the current token query and cached token keys, with a projection length much smaller than the embedding dimension. We maintain a lightweight binary structure in GPU memory to facilitate these calculations. Unlike existing compression strategies that compute attention to determine token retention, HashEvict makes these decisions pre-attention, thereby reducing computational costs. Additionally, HashEvict is dynamic - at every decoding step, the key and value of the current token replace the embeddings of a token expected to produce the lowest attention score. We demonstrate that HashEvict can compress the KV cache by 30%-70% while maintaining high performance across reasoning, multiple-choice, long-context retrieval and summarization tasks.
Learning Normal Flow Directly From Event Neighborhoods
Dec 15, 2024



Event-based motion field estimation is an important task. However, current optical flow methods face challenges: learning-based approaches, often frame-based and relying on CNNs, lack cross-domain transferability, while model-based methods, though more robust, are less accurate. To address the limitations of optical flow estimation, recent works have focused on normal flow, which can be more reliably measured in regions with limited texture or strong edges. However, existing normal flow estimators are predominantly model-based and suffer from high errors. In this paper, we propose a novel supervised point-based method for normal flow estimation that overcomes the limitations of existing event learning-based approaches. Using a local point cloud encoder, our method directly estimates per-event normal flow from raw events, offering multiple unique advantages: 1) It produces temporally and spatially sharp predictions. 2) It supports more diverse data augmentation, such as random rotation, to improve robustness across various domains. 3) It naturally supports uncertainty quantification via ensemble inference, which benefits downstream tasks. 4) It enables training and inference on undistorted data in normalized camera coordinates, improving transferability across cameras. Extensive experiments demonstrate our method achieves better and more consistent performance than state-of-the-art methods when transferred across different datasets. Leveraging this transferability, we train our model on the union of datasets and release it for public use. Finally, we introduce an egomotion solver based on a maximum-margin problem that uses normal flow and IMU to achieve strong performance in challenging scenarios.
Channel Self-Supervision for Online Knowledge Distillation
Mar 23, 2022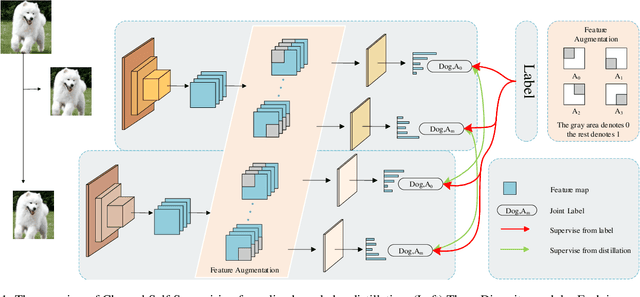
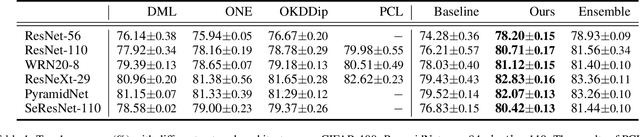
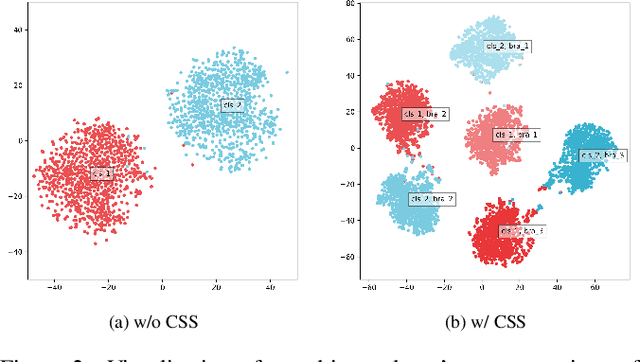
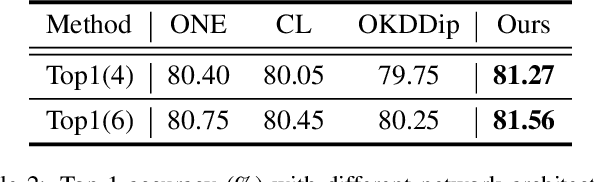
Recently, researchers have shown an increased interest in the online knowledge distillation. Adopting an one-stage and end-to-end training fashion, online knowledge distillation uses aggregated intermediated predictions of multiple peer models for training. However, the absence of a powerful teacher model may result in the homogeneity problem between group peers, affecting the effectiveness of group distillation adversely. In this paper, we propose a novel online knowledge distillation method, \textbf{C}hannel \textbf{S}elf-\textbf{S}upervision for Online Knowledge Distillation (CSS), which structures diversity in terms of input, target, and network to alleviate the homogenization problem. Specifically, we construct a dual-network multi-branch structure and enhance inter-branch diversity through self-supervised learning, adopting the feature-level transformation and augmenting the corresponding labels. Meanwhile, the dual network structure has a larger space of independent parameters to resist the homogenization problem during distillation. Extensive quantitative experiments on CIFAR-100 illustrate that our method provides greater diversity than OKDDip and we also give pretty performance improvement, even over the state-of-the-art such as PCL. The results on three fine-grained datasets (StanfordDogs, StanfordCars, CUB-200-211) also show the significant generalization capability of our approach.
Temporally Resolution Decrement: Utilizing the Shape Consistency for Higher Computational Efficiency
Dec 02, 2021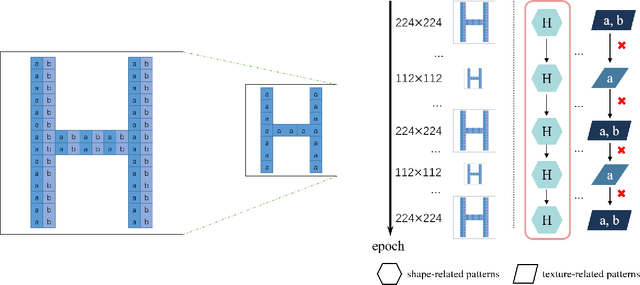
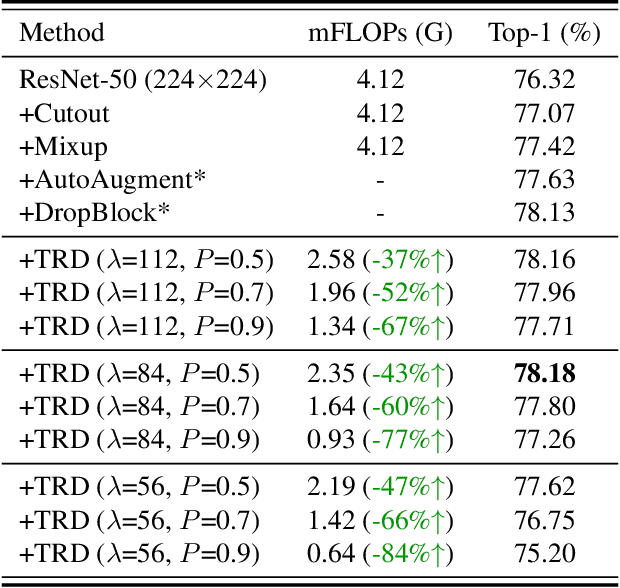
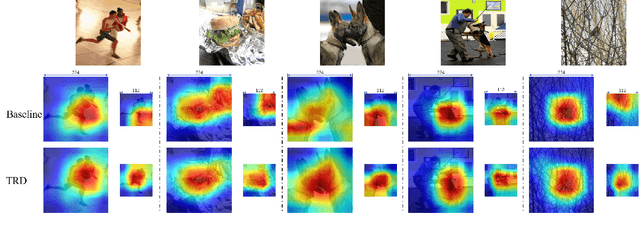
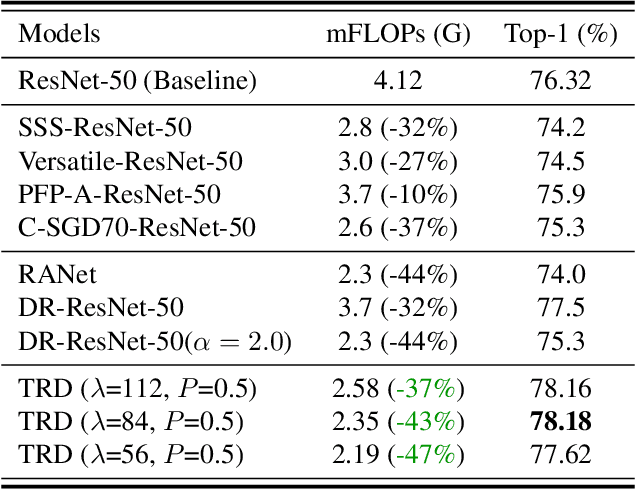
Image resolution that has close relations with accuracy and computational cost plays a pivotal role in network training. In this paper, we observe that the reduced image retains relatively complete shape semantics but loses extensive texture information. Inspired by the consistency of the shape semantics as well as the fragility of the texture information, we propose a novel training strategy named Temporally Resolution Decrement. Wherein, we randomly reduce the training images to a smaller resolution in the time domain. During the alternate training with the reduced images and the original images, the unstable texture information in the images results in a weaker correlation between the texture-related patterns and the correct label, naturally enforcing the model to rely more on shape properties that are robust and conform to the human decision rule. Surprisingly, our approach greatly improves the computational efficiency of convolutional neural networks. On ImageNet classification, using only 33% calculation quantity (randomly reducing the training image to 112$\times$112 within 90% epochs) can still improve ResNet-50 from 76.32% to 77.71%, and using 63% calculation quantity (randomly reducing the training image to 112 x 112 within 50% epochs) can improve ResNet-50 to 78.18%.
Feature Mining: A Novel Training Strategy for Convolutional Neural Network
Jul 18, 2021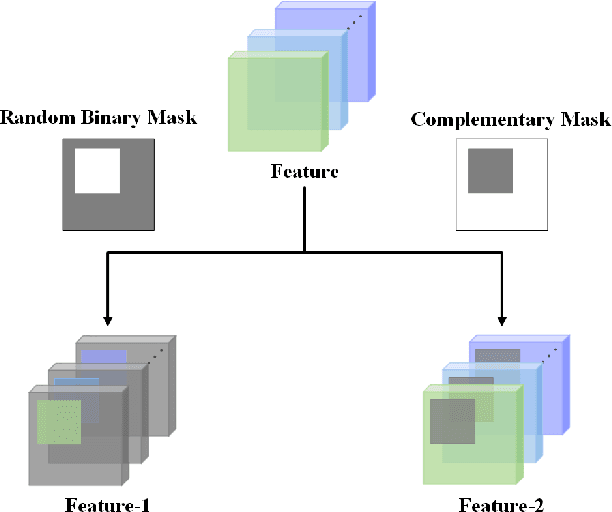
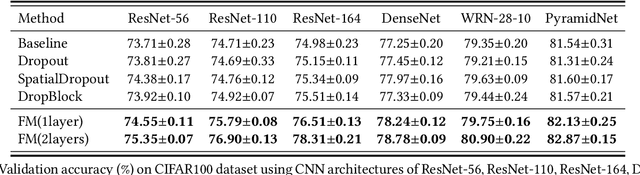


In this paper, we propose a novel training strategy for convolutional neural network(CNN) named Feature Mining, that aims to strengthen the network's learning of the local feature. Through experiments, we find that semantic contained in different parts of the feature is different, while the network will inevitably lose the local information during feedforward propagation. In order to enhance the learning of local feature, Feature Mining divides the complete feature into two complementary parts and reuse these divided feature to make the network learn more local information, we call the two steps as feature segmentation and feature reusing. Feature Mining is a parameter-free method and has plug-and-play nature, and can be applied to any CNN models. Extensive experiments demonstrate the wide applicability, versatility, and compatibility of our method.
Learning from Miscellaneous Other-Class Words for Few-shot Named Entity Recognition
Jun 29, 2021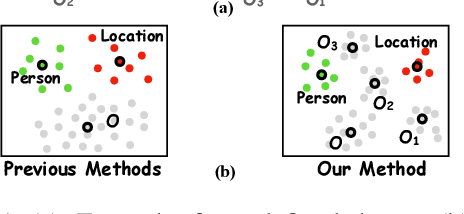
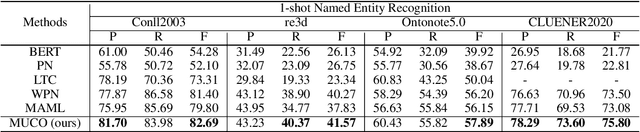
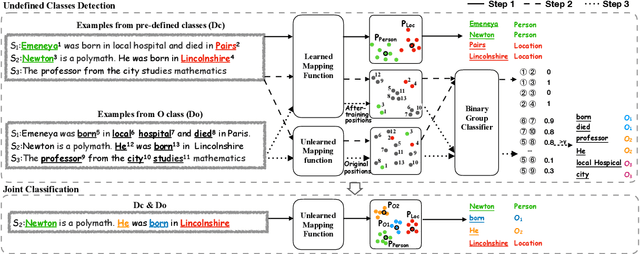
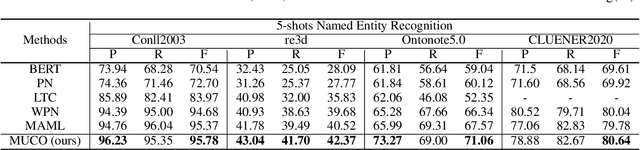
Few-shot Named Entity Recognition (NER) exploits only a handful of annotations to identify and classify named entity mentions. Prototypical network shows superior performance on few-shot NER. However, existing prototypical methods fail to differentiate rich semantics in other-class words, which will aggravate overfitting under few shot scenario. To address the issue, we propose a novel model, Mining Undefined Classes from Other-class (MUCO), that can automatically induce different undefined classes from the other class to improve few-shot NER. With these extra-labeled undefined classes, our method will improve the discriminative ability of NER classifier and enhance the understanding of predefined classes with stand-by semantic knowledge. Experimental results demonstrate that our model outperforms five state-of-the-art models in both 1-shot and 5-shots settings on four NER benchmarks. We will release the code upon acceptance. The source code is released on https: //github.com/shuaiwa16/OtherClassNER.git.