 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence
Apr 20, 2026Large language models are increasingly expected to serve as general-purpose agents that interact with external, stateful tool environments. The Model Context Protocol (MCP) and broader agent skills offer a unified interface for connecting agents with scalable real-world services, but training robust agents remains limited by the lack of realistic environments and principled mechanisms for life-long learning. In this paper, we present \textbf{Agent-World}, a self-evolving training arena for advancing general agent intelligence through scalable environments. Agent-World has two main components: (1) Agentic Environment-Task Discovery, which autonomously explores topic-aligned databases and executable tool ecosystems from thousands of real-world environment themes and synthesizes verifiable tasks with controllable difficulty; and (2) Continuous Self-Evolving Agent Training, which combines multi-environment reinforcement learning with a self-evolving agent arena that automatically identifies capability gaps through dynamic task synthesis and drives targeted learning, enabling the co-evolution of agent policies and environments. Across 23 challenging agent benchmarks, Agent-World-8B and 14B consistently outperforms strong proprietary models and environment scaling baselines. Further analyses reveal scaling trends in relation to environment diversity and self-evolution rounds, offering insights for building general agent intelligence.
MARS-Bench: A Multi-turn Athletic Real-world Scenario Benchmark for Dialogue Evaluation
May 27, 2025Large Language Models (\textbf{LLMs}), e.g. ChatGPT, have been widely adopted in real-world dialogue applications. However, LLMs' robustness, especially in handling long complex dialogue sessions, including frequent motivation transfer, sophisticated cross-turn dependency, is criticized all along. Nevertheless, no existing benchmarks can fully reflect these weaknesses. We present \textbf{MARS-Bench}, a \textbf{M}ulti-turn \textbf{A}thletic \textbf{R}eal-world \textbf{S}cenario Dialogue \textbf{Bench}mark, designed to remedy the gap. MARS-Bench is constructed from play-by-play text commentary so to feature realistic dialogues specifically designed to evaluate three critical aspects of multi-turn conversations: Ultra Multi-turn, Interactive Multi-turn, and Cross-turn Tasks. Extensive experiments on MARS-Bench also reveal that closed-source LLMs significantly outperform open-source alternatives, explicit reasoning significantly boosts LLMs' robustness on handling long complex dialogue sessions, and LLMs indeed face significant challenges when handling motivation transfer and sophisticated cross-turn dependency. Moreover, we provide mechanistic interpretability on how attention sinks due to special tokens lead to LLMs' performance degradation when handling long complex dialogue sessions based on attention visualization experiment in Qwen2.5-7B-Instruction.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Jan 21, 2025This paper introduces UI-TARS, a native GUI agent model that solely perceives the screenshots as input and performs human-like interactions (e.g., keyboard and mouse operations). Unlike prevailing agent frameworks that depend on heavily wrapped commercial models (e.g., GPT-4o) with expert-crafted prompts and workflows, UI-TARS is an end-to-end model that outperforms these sophisticated frameworks. Experiments demonstrate its superior performance: UI-TARS achieves SOTA performance in 10+ GUI agent benchmarks evaluating perception, grounding, and GUI task execution. Notably, in the OSWorld benchmark, UI-TARS achieves scores of 24.6 with 50 steps and 22.7 with 15 steps, outperforming Claude (22.0 and 14.9 respectively). In AndroidWorld, UI-TARS achieves 46.6, surpassing GPT-4o (34.5). UI-TARS incorporates several key innovations: (1) Enhanced Perception: leveraging a large-scale dataset of GUI screenshots for context-aware understanding of UI elements and precise captioning; (2) Unified Action Modeling, which standardizes actions into a unified space across platforms and achieves precise grounding and interaction through large-scale action traces; (3) System-2 Reasoning, which incorporates deliberate reasoning into multi-step decision making, involving multiple reasoning patterns such as task decomposition, reflection thinking, milestone recognition, etc. (4) Iterative Training with Reflective Online Traces, which addresses the data bottleneck by automatically collecting, filtering, and reflectively refining new interaction traces on hundreds of virtual machines. Through iterative training and reflection tuning, UI-TARS continuously learns from its mistakes and adapts to unforeseen situations with minimal human intervention. We also analyze the evolution path of GUI agents to guide the further development of this domain.
TA&AT: Enhancing Task-Oriented Dialog with Turn-Level Auxiliary Tasks and Action-Tree Based Scheduled Sampling
Jan 28, 2024



Task-oriented dialog systems have witnessed substantial progress due to conversational pre-training techniques. Yet, two significant challenges persist. First, most systems primarily utilize the latest turn's state label for the generator. This practice overlooks the comprehensive value of state labels in boosting the model's understanding for future generations. Second, an overreliance on generated policy often leads to error accumulation, resulting in suboptimal responses when adhering to incorrect actions. To combat these challenges, we propose turn-level multi-task objectives for the encoder. With the guidance of essential information from labeled intermediate states, we establish a more robust representation for both understanding and generation. For the decoder, we introduce an action tree-based scheduled sampling technique. Specifically, we model the hierarchical policy as trees and utilize the similarity between trees to sample negative policy based on scheduled sampling, hoping the model to generate invariant responses under perturbations. This method simulates potential pitfalls by sampling similar negative policy, bridging the gap between task-oriented dialog training and inference. Among methods without continual pre-training, our approach achieved state-of-the-art (SOTA) performance on the MultiWOZ dataset series and was also competitive with pre-trained SOTA methods.
Channel-aware Decoupling Network for Multi-turn Dialogue Comprehension
Jan 11, 2023



Training machines to understand natural language and interact with humans is one of the major goals of artificial intelligence. Recent years have witnessed an evolution from matching networks to pre-trained language models (PrLMs). In contrast to the plain-text modeling as the focus of the PrLMs, dialogue texts involve multiple speakers and reflect special characteristics such as topic transitions and structure dependencies between distant utterances. However, the related PrLM models commonly represent dialogues sequentially by processing the pairwise dialogue history as a whole. Thus the hierarchical information on either utterance interrelation or speaker roles coupled in such representations is not well addressed. In this work, we propose compositional learning for holistic interaction across the utterances beyond the sequential contextualization from PrLMs, in order to capture the utterance-aware and speaker-aware representations entailed in a dialogue history. We decouple the contextualized word representations by masking mechanisms in Transformer-based PrLM, making each word only focus on the words in current utterance, other utterances, and two speaker roles (i.e., utterances of sender and utterances of the receiver), respectively. In addition, we employ domain-adaptive training strategies to help the model adapt to the dialogue domains. Experimental results show that our method substantially boosts the strong PrLM baselines in four public benchmark datasets, achieving new state-of-the-art performance over previous methods.
Filling the Gap of Utterance-aware and Speaker-aware Representation for Multi-turn Dialogue
Sep 14, 2020
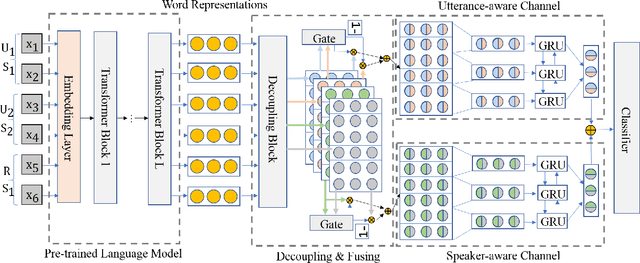
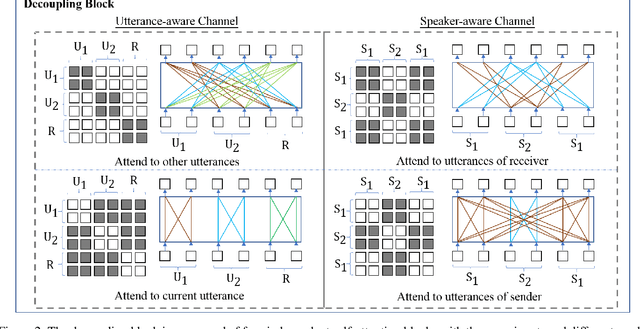
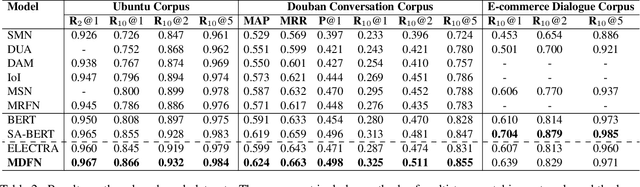
A multi-turn dialogue is composed of multiple utterances from two or more different speaker roles. Thus utterance- and speaker-aware clues are supposed to be well captured in models. However, in the existing retrieval-based multi-turn dialogue modeling, the pre-trained language models (PrLMs) as encoder represent the dialogues coarsely by taking the pairwise dialogue history and candidate response as a whole, the hierarchical information on either utterance interrelation or speaker roles coupled in such representations is not well addressed. In this work, we propose a novel model to fill such a gap by modeling the effective utterance-aware and speaker-aware representations entailed in a dialogue history. In detail, we decouple the contextualized word representations by masking mechanisms in Transformer-based PrLM, making each word only focus on the words in current utterance, other utterances, two speaker roles (i.e., utterances of sender and utterances of receiver), respectively. Experimental results show that our method boosts the strong ELECTRA baseline substantially in four public benchmark datasets, and achieves various new state-of-the-art performance over previous methods. A series of ablation studies are conducted to demonstrate the effectiveness of our method.