 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuzzCoder: Byte-level Fuzzing Test via Large Language Model
Sep 03, 2024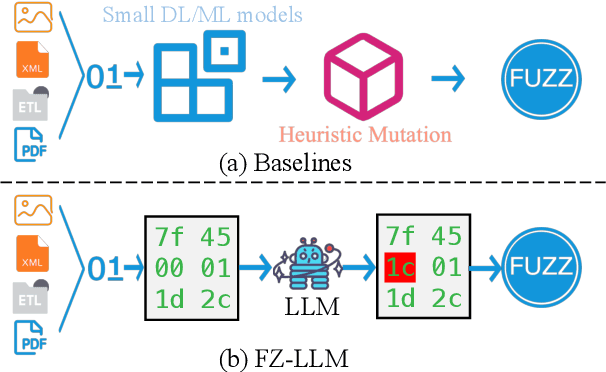
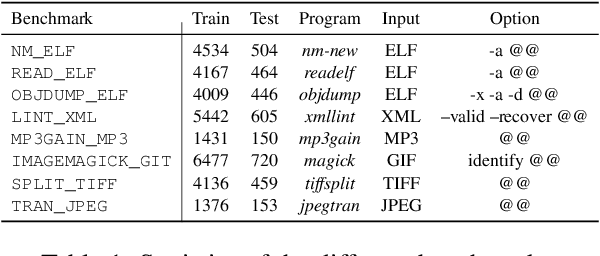
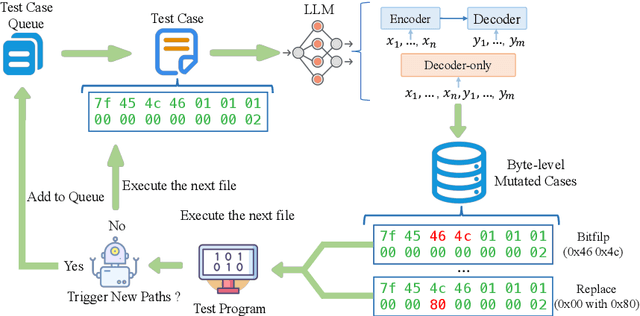
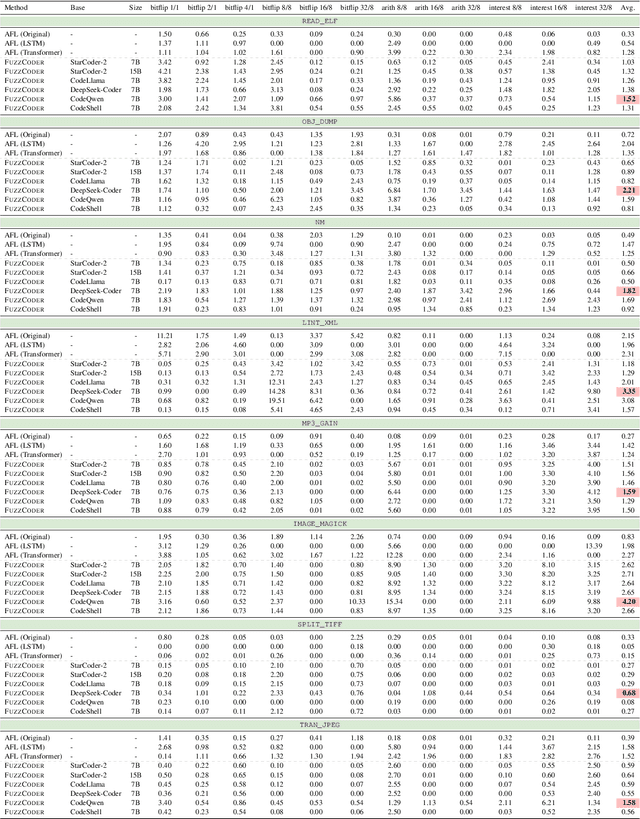
Fuzzing is an important dynamic program analysis technique designed for finding vulnerabilities in complex software. Fuzzing involves presenting a target program with crafted malicious input to cause crashes, buffer overflows, memory errors, and exceptions. Crafting malicious inputs in an efficient manner is a difficult open problem and the best approaches often apply uniform random mutations to pre-existing valid inputs. In this work, we propose to adopt fine-tuned large language models (FuzzCoder) to learn patterns in the input files from successful attacks to guide future fuzzing explorations. Specifically, we develop a framework to leverage the code LLMs to guide the mutation process of inputs in fuzzing. The mutation process is formulated as the sequence-to-sequence modeling, where LLM receives a sequence of bytes and then outputs the mutated byte sequence. FuzzCoder is fine-tuned on the created instruction dataset (Fuzz-Instruct), where the successful fuzzing history is collected from the heuristic fuzzing tool. FuzzCoder can predict mutation locations and strategies locations in input files to trigger abnormal behaviors of the program. Experimental results show that FuzzCoder based on AFL (American Fuzzy Lop) gain significant improvements in terms of effective proportion of mutation (EPM) and number of crashes (NC) for various input formats including ELF, JPG, MP3, and XML.