 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARDoc: A Memory-Aware Refinement Agent Framework for Multimodal Long Document QA
Jun 04, 2026Iterative retrieval-reasoning agents have recently shown promise for multimodal long-document question answering. However, most existing systems maintain a single growing context that mixes retrieval traces, observations, and intermediate reasoning. As interactions accumulate, key evidence becomes scattered and diluted, making multi-hop reasoning noisy. We propose MARDoc, a Memory-Aware Refinement Agent framework that decouples long-document QA into three specialized agents: an Explorer for multi-granularity multimodal retrieval, a Refiner for distilling interaction traces into structured evidence and reasoning memories, and a Reflector for checking evidence sufficiency and providing targeted feedback. Across iterations, the agents rely on a dynamically updated structured memory rather than a full accumulated interaction history. This design reduces context noise while preserving answer-critical facts and their logical dependencies. Experiments on MMLongBench-Doc and DocBench show that MARDoc achieves strong results, outperforming same-backbone baselines and demonstrating the effectiveness of structured memory for agentic document QA.
Benchmark Leakage Trap: Can We Trust LLM-based Recommendation?
Feb 14, 2026The expanding integration of Large Language Models (LLMs) into recommender systems poses critical challenges to evaluation reliability. This paper identifies and investigates a previously overlooked issue: benchmark data leakage in LLM-based recommendation. This phenomenon occurs when LLMs are exposed to and potentially memorize benchmark datasets during pre-training or fine-tuning, leading to artificially inflated performance metrics that fail to reflect true model performance. To validate this phenomenon, we simulate diverse data leakage scenarios by conducting continued pre-training of foundation models on strategically blended corpora, which include user-item interactions from both in-domain and out-of-domain sources. Our experiments reveal a dual-effect of data leakage: when the leaked data is domain-relevant, it induces substantial but spurious performance gains, misleadingly exaggerating the model's capability. In contrast, domain-irrelevant leakage typically degrades recommendation accuracy, highlighting the complex and contingent nature of this contamination. Our findings reveal that data leakage acts as a critical, previously unaccounted-for factor in LLM-based recommendation, which could impact the true model performance. We release our code at https://github.com/yusba1/LLMRec-Data-Leakage.
Multi-Agent Collaboration for Multilingual Code Instruction Tuning
Feb 11, 2025Recent advancement in code understanding and generation demonstrates that code LLMs fine-tuned on a high-quality instruction dataset can gain powerful capabilities to address wide-ranging code-related tasks. However, most previous existing methods mainly view each programming language in isolation and ignore the knowledge transfer among different programming languages. To bridge the gap among different programming languages, we introduce a novel multi-agent collaboration framework to enhance multilingual instruction tuning for code LLMs, where multiple language-specific intelligent agent components with generation memory work together to transfer knowledge from one language to another efficiently and effectively. Specifically, we first generate the language-specific instruction data from the code snippets and then provide the generated data as the seed data for language-specific agents. Multiple language-specific agents discuss and collaborate to formulate a new instruction and its corresponding solution (A new programming language or existing programming language), To further encourage the cross-lingual transfer, each agent stores its generation history as memory and then summarizes its merits and faults. Finally, the high-quality multilingual instruction data is used to encourage knowledge transfer among different programming languages to train Qwen2.5-xCoder. Experimental results on multilingual programming benchmarks demonstrate the superior performance of Qwen2.5-xCoder in sharing common knowledge, highlighting its potential to reduce the cross-lingual gap.
ExecRepoBench: Multi-level Executable Code Completion Evaluation
Dec 16, 2024



Code completion has become an essential tool for daily software development. Existing evaluation benchmarks often employ static methods that do not fully capture the dynamic nature of real-world coding environments and face significant challenges, including limited context length, reliance on superficial evaluation metrics, and potential overfitting to training datasets. In this work, we introduce a novel framework for enhancing code completion in software development through the creation of a repository-level benchmark ExecRepoBench and the instruction corpora Repo-Instruct, aim at improving the functionality of open-source large language models (LLMs) in real-world coding scenarios that involve complex interdependencies across multiple files. ExecRepoBench includes 1.2K samples from active Python repositories. Plus, we present a multi-level grammar-based completion methodology conditioned on the abstract syntax tree to mask code fragments at various logical units (e.g. statements, expressions, and functions). Then, we fine-tune the open-source LLM with 7B parameters on Repo-Instruct to produce a strong code completion baseline model Qwen2.5-Coder-Instruct-C based on the open-source model. Qwen2.5-Coder-Instruct-C is rigorously evaluated against existing benchmarks, including MultiPL-E and ExecRepoBench, which consistently outperforms prior baselines across all programming languages. The deployment of \ourmethod{} can be used as a high-performance, local service for programming development\footnote{\url{https://execrepobench.github.io/}}.
ULMRec: User-centric Large Language Model for Sequential Recommendation
Dec 07, 2024Recent advances in Large Language Models (LLMs) have demonstrated promising performance in sequential recommendation tasks, leveraging their superior language understanding capabilities. However, existing LLM-based recommendation approaches predominantly focus on modeling item-level co-occurrence patterns while failing to adequately capture user-level personalized preferences. This is problematic since even users who display similar behavioral patterns (e.g., clicking or purchasing similar items) may have fundamentally different underlying interests. To alleviate this problem, in this paper, we propose ULMRec, a framework that effectively integrates user personalized preferences into LLMs for sequential recommendation. Considering there has the semantic gap between item IDs and LLMs, we replace item IDs with their corresponding titles in user historical behaviors, enabling the model to capture the item semantics. For integrating the user personalized preference, we design two key components: (1) user indexing: a personalized user indexing mechanism that leverages vector quantization on user reviews and user IDs to generate meaningful and unique user representations, and (2) alignment tuning: an alignment-based tuning stage that employs comprehensive preference alignment tasks to enhance the model's capability in capturing personalized information. Through this design, ULMRec achieves deep integration of language semantics with user personalized preferences, facilitating effective adaptation to recommendation. Extensive experiments on two public datasets demonstrate that ULMRec significantly outperforms existing methods, validating the effectiveness of our approach.
Bucket Pre-training is All You Need
Jul 10, 2024


Large language models (LLMs) have demonstrated exceptional performance across various natural language processing tasks. However, the conventional fixed-length data composition strategy for pretraining, which involves concatenating and splitting documents, can introduce noise and limit the model's ability to capture long-range dependencies. To address this, we first introduce three metrics for evaluating data composition quality: padding ratio, truncation ratio, and concatenation ratio. We further propose a multi-bucket data composition method that moves beyond the fixed-length paradigm, offering a more flexible and efficient approach to pretraining. Extensive experiments demonstrate that our proposed method could significantly improving both the efficiency and efficacy of LLMs pretraining. Our approach not only reduces noise and preserves context but also accelerates training, making it a promising solution for LLMs pretraining.
Review-LLM: Harnessing Large Language Models for Personalized Review Generation
Jul 10, 2024
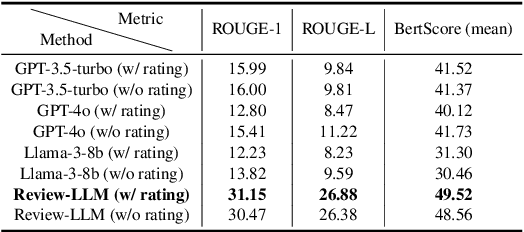
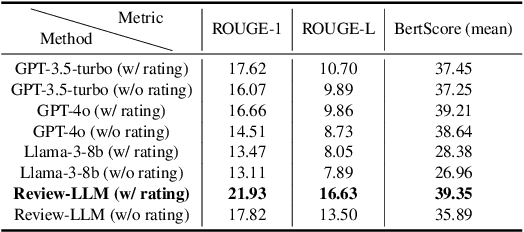
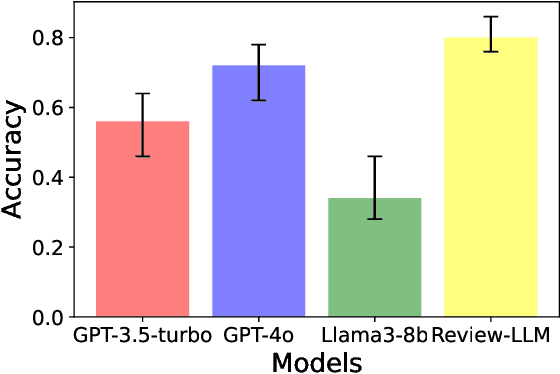
Product review generation is an important task in recommender systems, which could provide explanation and persuasiveness for the recommendation. Recently, Large Language Models (LLMs, e.g., ChatGPT) have shown superior text modeling and generating ability, which could be applied in review generation. However, directly applying the LLMs for generating reviews might be troubled by the ``polite'' phenomenon of the LLMs and could not generate personalized reviews (e.g., negative reviews). In this paper, we propose Review-LLM that customizes LLMs for personalized review generation. Firstly, we construct the prompt input by aggregating user historical behaviors, which include corresponding item titles and reviews. This enables the LLMs to capture user interest features and review writing style. Secondly, we incorporate ratings as indicators of satisfaction into the prompt, which could further improve the model's understanding of user preferences and the sentiment tendency control of generated reviews. Finally, we feed the prompt text into LLMs, and use Supervised Fine-Tuning (SFT) to make the model generate personalized reviews for the given user and target item. Experimental results on the real-world dataset show that our fine-tuned model could achieve better review generation performance than existing close-source LLMs.
xCoT: Cross-lingual Instruction Tuning for Cross-lingual Chain-of-Thought Reasoning
Jan 13, 2024Chain-of-thought (CoT) has emerged as a powerful technique to elicit reasoning in large language models and improve a variety of downstream tasks. CoT mainly demonstrates excellent performance in English, but its usage in low-resource languages is constrained due to poor language generalization. To bridge the gap among different languages, we propose a cross-lingual instruction fine-tuning framework (xCOT) to transfer knowledge from high-resource languages to low-resource languages. Specifically, the multilingual instruction training data (xCOT-INSTRUCT) is created to encourage the semantic alignment of multiple languages. We introduce cross-lingual in-context few-shot learning (xICL)) to accelerate multilingual agreement in instruction tuning, where some fragments of source languages in examples are randomly substituted by their counterpart translations of target languages. During multilingual instruction tuning, we adopt the randomly online CoT strategy to enhance the multilingual reasoning ability of the large language model by first translating the query to another language and then answering in English. To further facilitate the language transfer, we leverage the high-resource CoT to supervise the training of low-resource languages with cross-lingual distillation. Experimental results on previous benchmarks demonstrate the superior performance of xCoT in reducing the gap among different languages, highlighting its potential to reduce the cross-lingual gap.
PEPT: Expert Finding Meets Personalized Pre-training
Dec 19, 2023



Finding appropriate experts is essential in Community Question Answering (CQA) platforms as it enables the effective routing of questions to potential users who can provide relevant answers. The key is to personalized learning expert representations based on their historical answered questions, and accurately matching them with target questions. There have been some preliminary works exploring the usability of PLMs in expert finding, such as pre-training expert or question representations. However, these models usually learn pure text representations of experts from histories, disregarding personalized and fine-grained expert modeling. For alleviating this, we present a personalized pre-training and fine-tuning paradigm, which could effectively learn expert interest and expertise simultaneously. Specifically, in our pre-training framework, we integrate historical answered questions of one expert with one target question, and regard it as a candidate aware expert-level input unit. Then, we fuse expert IDs into the pre-training for guiding the model to model personalized expert representations, which can help capture the unique characteristics and expertise of each individual expert. Additionally, in our pre-training task, we design: 1) a question-level masked language model task to learn the relatedness between histories, enabling the modeling of question-level expert interest; 2) a vote-oriented task to capture question-level expert expertise by predicting the vote score the expert would receive. Through our pre-training framework and tasks, our approach could holistically learn expert representations including interests and expertise. Our method has been extensively evaluated on six real-world CQA datasets, and the experimental results consistently demonstrate the superiority of our approach over competitive baseline methods.