 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DGen: Triplane Latent Diffusion for Textured Mesh Generation
Paper and Code
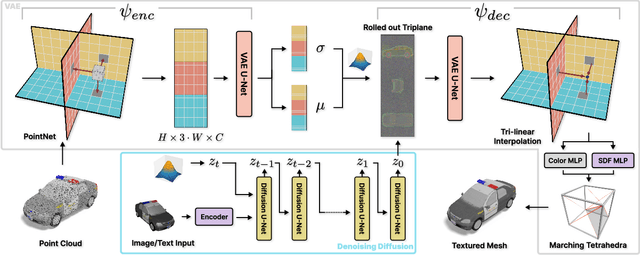
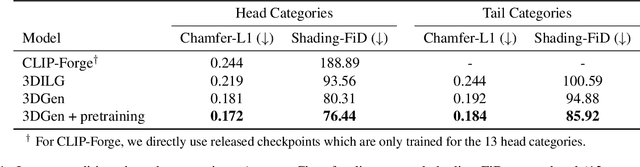

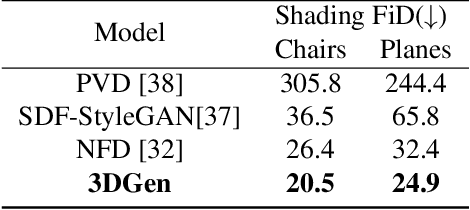
Latent diffusion models for image generation have crossed a quality threshold which enabled them to achieve mass adoption. Recently, a series of works have made advancements towards replicating this success in the 3D domain, introducing techniques such as point cloud VAE, triplane representation, neural implicit surfaces and differentiable rendering based training. We take another step along this direction, combining these developments in a two-step pipeline consisting of 1) a triplane VAE which can learn latent representations of textured meshes and 2) a conditional diffusion model which generates the triplane features. For the first time this architecture allows conditional and unconditional generation of high quality textured or untextured 3D meshes across multiple diverse categories in a few seconds on a single GPU. It outperforms previous work substantially on image-conditioned and unconditional generation on mesh quality as well as texture generation. Furthermore, we demonstrate the scalability of our model to large datasets for increased quality and diversity. We will release our code and trained models.