 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCtrl-Adapter: An Efficient and Versatile Framework for Adapting Diverse Controls to Any Diffusion Model
Apr 15, 2024



ControlNets are widely used for adding spatial control in image generation with different conditions, such as depth maps, canny edges, and human poses. However, there are several challenges when leveraging the pretrained image ControlNets for controlled video generation. First, pretrained ControlNet cannot be directly plugged into new backbone models due to the mismatch of feature spaces, and the cost of training ControlNets for new backbones is a big burden. Second, ControlNet features for different frames might not effectively handle the temporal consistency. To address these challenges, we introduce Ctrl-Adapter, an efficient and versatile framework that adds diverse controls to any image/video diffusion models, by adapting pretrained ControlNets (and improving temporal alignment for videos). Ctrl-Adapter provides diverse capabilities including image control, video control, video control with sparse frames, multi-condition control, compatibility with different backbones, adaptation to unseen control conditions, and video editing. In Ctrl-Adapter, we train adapter layers that fuse pretrained ControlNet features to different image/video diffusion models, while keeping the parameters of the ControlNets and the diffusion models frozen. Ctrl-Adapter consists of temporal and spatial modules so that it can effectively handle the temporal consistency of videos. We also propose latent skipping and inverse timestep sampling for robust adaptation and sparse control. Moreover, Ctrl-Adapter enables control from multiple conditions by simply taking the (weighted) average of ControlNet outputs. With diverse image/video diffusion backbones (SDXL, Hotshot-XL, I2VGen-XL, and SVD), Ctrl-Adapter matches ControlNet for image control and outperforms all baselines for video control (achieving the SOTA accuracy on the DAVIS 2017 dataset) with significantly lower computational costs (less than 10 GPU hours).
EnvGen: Generating and Adapting Environments via LLMs for Training Embodied Agents
Mar 18, 2024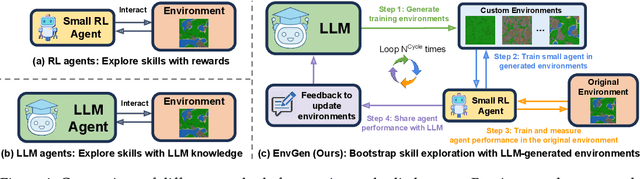



Recent SOTA approaches for embodied learning via interaction directly employ large language models (LLMs) as agents to determine the next steps in an environment. Due to their world knowledge and reasoning capabilities, LLM agents achieve stronger performance than previous smaller agents based on reinforcement learning (RL); however, frequently calling LLMs is slow and expensive. Instead of directly employing LLMs as agents, can we use LLMs' reasoning capabilities to adaptively create training environments to help smaller embodied RL agents learn useful skills that they are weak at? We propose EnvGen, a novel framework to address this question. First, we prompt an LLM to generate training environments that allow agents to quickly learn different tasks in parallel. Concretely, the LLM is given the task description and simulator objectives that the agents should learn and is then asked to generate a set of environment configurations (e.g., different terrains, items given to agents, etc.). Next, we train a small RL agent in a mixture of the original and LLM-generated environments. Then, we enable the LLM to continuously adapt the generated environments to progressively improve the skills that the agent is weak at, by providing feedback to the LLM in the form of the agent's performance. We demonstrate the usefulness of EnvGen with comprehensive experiments in Crafter and Heist environments. We find that a small RL agent trained with EnvGen can outperform SOTA methods, including a GPT-4 agent, and learns long-horizon tasks significantly faster. We show qualitatively how the LLM adapts training environments to help improve RL agents' weaker skills over time. Additionally, EnvGen is substantially more efficient as it only uses a small number of LLM calls (e.g., 4 in total), whereas LLM agents require thousands of LLM calls. Lastly, we present detailed ablation studies for our design choices.
DiagrammerGPT: Generating Open-Domain, Open-Platform Diagrams via LLM Planning
Oct 18, 2023



Text-to-image (T2I) generation has seen significant growth over the past few years. Despite this, there has been little work on generating diagrams with T2I models. A diagram is a symbolic/schematic representation that explains information using structurally rich and spatially complex visualizations (e.g., a dense combination of related objects, text labels, directional arrows, connection lines, etc.). Existing state-of-the-art T2I models often fail at diagram generation because they lack fine-grained object layout control when many objects are densely connected via complex relations such as arrows/lines and also often fail to render comprehensible text labels. To address this gap, we present DiagrammerGPT, a novel two-stage text-to-diagram generation framework that leverages the layout guidance capabilities of LLMs (e.g., GPT-4) to generate more accurate open-domain, open-platform diagrams. In the first stage, we use LLMs to generate and iteratively refine 'diagram plans' (in a planner-auditor feedback loop) which describe all the entities (objects and text labels), their relationships (arrows or lines), and their bounding box layouts. In the second stage, we use a diagram generator, DiagramGLIGEN, and a text label rendering module to generate diagrams following the diagram plans. To benchmark the text-to-diagram generation task, we introduce AI2D-Caption, a densely annotated diagram dataset built on top of the AI2D dataset. We show quantitatively and qualitatively that our DiagrammerGPT framework produces more accurate diagrams, outperforming existing T2I models. We also provide comprehensive analysis including open-domain diagram generation, vector graphic diagram generation in different platforms, human-in-the-loop diagram plan editing, and multimodal planner/auditor LLMs (e.g., GPT-4Vision). We hope our work can inspire further research on diagram generation via T2I models and LLMs.
VideoDirectorGPT: Consistent Multi-scene Video Generation via LLM-Guided Planning
Sep 26, 2023Although recent text-to-video (T2V) generation methods have seen significant advancements, most of these works focus on producing short video clips of a single event with a single background (i.e., single-scene videos). Meanwhile, recent large language models (LLMs) have demonstrated their capability in generating layouts and programs to control downstream visual modules such as image generation models. This raises an important question: can we leverage the knowledge embedded in these LLMs for temporally consistent long video generation? In this paper, we propose VideoDirectorGPT, a novel framework for consistent multi-scene video generation that uses the knowledge of LLMs for video content planning and grounded video generation. Specifically, given a single text prompt, we first ask our video planner LLM (GPT-4) to expand it into a 'video plan', which involves generating the scene descriptions, the entities with their respective layouts, the background for each scene, and consistency groupings of the entities and backgrounds. Next, guided by this output from the video planner, our video generator, Layout2Vid, has explicit control over spatial layouts and can maintain temporal consistency of entities/backgrounds across scenes, while only trained with image-level annotations. Our experiments demonstrate that VideoDirectorGPT framework substantially improves layout and movement control in both single- and multi-scene video generation and can generate multi-scene videos with visual consistency across scenes, while achieving competitive performance with SOTAs in open-domain single-scene T2V generation. We also demonstrate that our framework can dynamically control the strength for layout guidance and can also generate videos with user-provided images. We hope our framework can inspire future work on better integrating the planning ability of LLMs into consistent long video generation.
Visual Programming for Text-to-Image Generation and Evaluation
May 24, 2023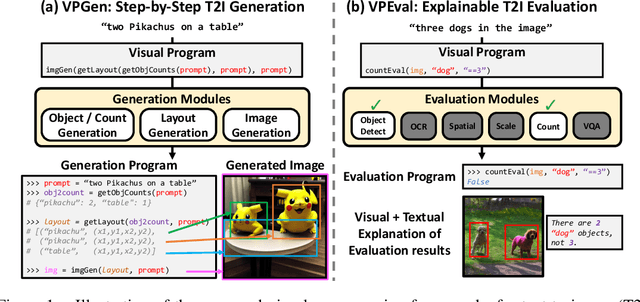



As large language models have demonstrated impressive performance in many domains, recent works have adopted language models (LMs) as controllers of visual modules for vision-and-language tasks. While existing work focuses on equipping LMs with visual understanding, we propose two novel interpretable/explainable visual programming frameworks for text-to-image (T2I) generation and evaluation. First, we introduce VPGen, an interpretable step-by-step T2I generation framework that decomposes T2I generation into three steps: object/count generation, layout generation, and image generation. We employ an LM to handle the first two steps (object/count generation and layout generation), by finetuning it on text-layout pairs. Our step-by-step T2I generation framework provides stronger spatial control than end-to-end models, the dominant approach for this task. Furthermore, we leverage the world knowledge of pretrained LMs, overcoming the limitation of previous layout-guided T2I works that can only handle predefined object classes. We demonstrate that our VPGen has improved control in counts/spatial relations/scales of objects than state-of-the-art T2I generation models. Second, we introduce VPEval, an interpretable and explainable evaluation framework for T2I generation based on visual programming. Unlike previous T2I evaluations with a single scoring model that is accurate in some skills but unreliable in others, VPEval produces evaluation programs that invoke a set of visual modules that are experts in different skills, and also provides visual+textual explanations of the evaluation results. Our analysis shows VPEval provides a more human-correlated evaluation for skill-specific and open-ended prompts than widely used single model-based evaluation. We hope our work encourages future progress on interpretable/explainable generation and evaluation for T2I models. Website: https://vp-t2i.github.io
Hierarchical Video-Moment Retrieval and Step-Captioning
Mar 29, 2023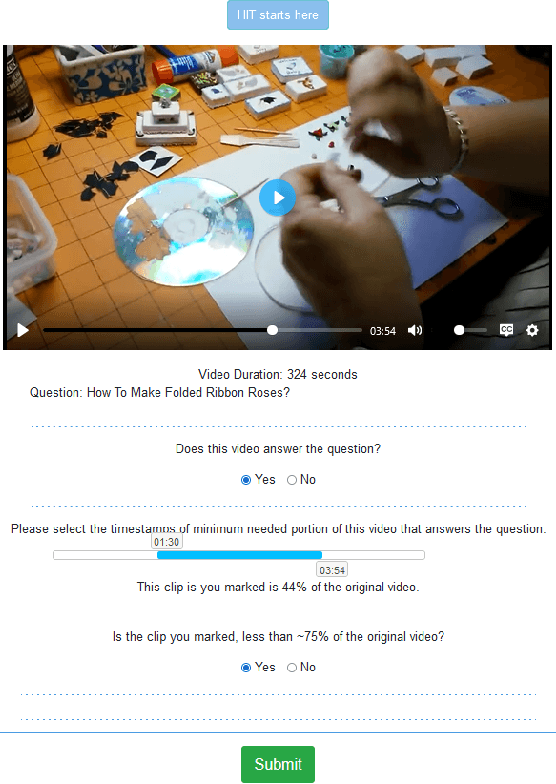

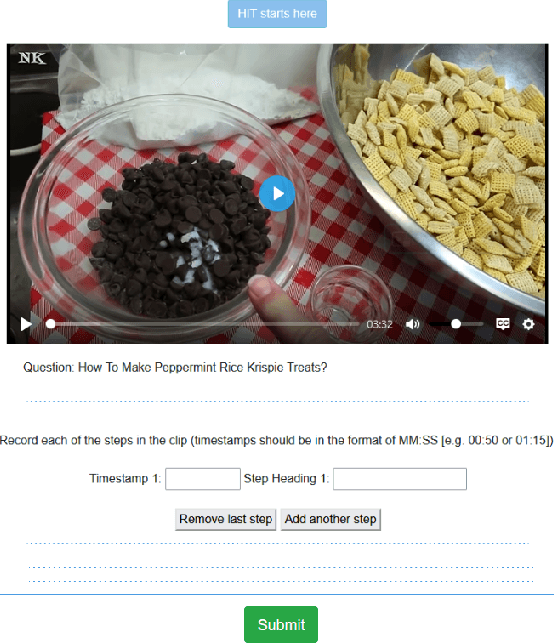
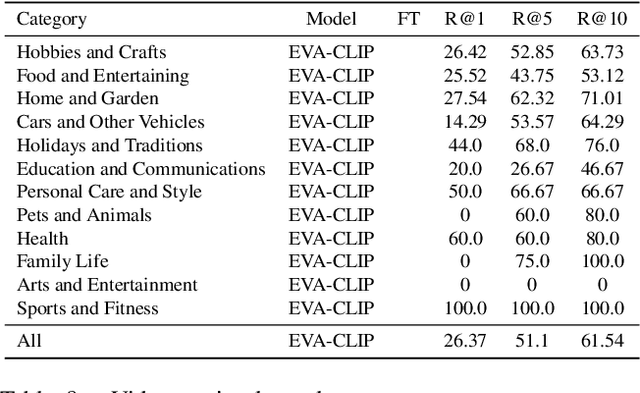
There is growing interest in searching for information from large video corpora. Prior works have studied relevant tasks, such as text-based video retrieval, moment retrieval, video summarization, and video captioning in isolation, without an end-to-end setup that can jointly search from video corpora and generate summaries. Such an end-to-end setup would allow for many interesting applications, e.g., a text-based search that finds a relevant video from a video corpus, extracts the most relevant moment from that video, and segments the moment into important steps with captions. To address this, we present the HiREST (HIerarchical REtrieval and STep-captioning) dataset and propose a new benchmark that covers hierarchical information retrieval and visual/textual stepwise summarization from an instructional video corpus. HiREST consists of 3.4K text-video pairs from an instructional video dataset, where 1.1K videos have annotations of moment spans relevant to text query and breakdown of each moment into key instruction steps with caption and timestamps (totaling 8.6K step captions). Our hierarchical benchmark consists of video retrieval, moment retrieval, and two novel moment segmentation and step captioning tasks. In moment segmentation, models break down a video moment into instruction steps and identify start-end boundaries. In step captioning, models generate a textual summary for each step. We also present starting point task-specific and end-to-end joint baseline models for our new benchmark. While the baseline models show some promising results, there still exists large room for future improvement by the community. Project website: https://hirest-cvpr2023.github.io
CoSIm: Commonsense Reasoning for Counterfactual Scene Imagination
Jul 08, 2022
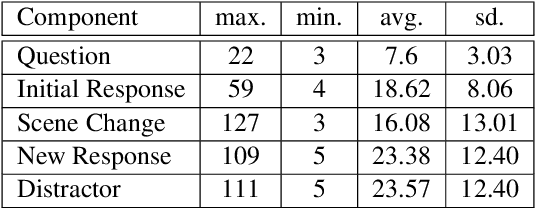
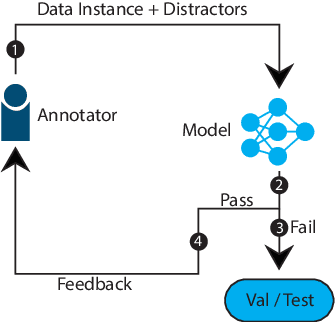
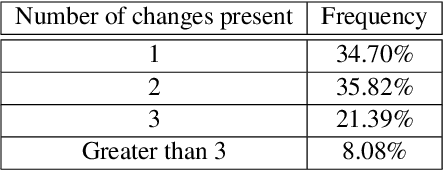
As humans, we can modify our assumptions about a scene by imagining alternative objects or concepts in our minds. For example, we can easily anticipate the implications of the sun being overcast by rain clouds (e.g., the street will get wet) and accordingly prepare for that. In this paper, we introduce a new task/dataset called Commonsense Reasoning for Counterfactual Scene Imagination (CoSIm) which is designed to evaluate the ability of AI systems to reason about scene change imagination. In this task/dataset, models are given an image and an initial question-response pair about the image. Next, a counterfactual imagined scene change (in textual form) is applied, and the model has to predict the new response to the initial question based on this scene change. We collect 3.5K high-quality and challenging data instances, with each instance consisting of an image, a commonsense question with a response, a description of a counterfactual change, a new response to the question, and three distractor responses. Our dataset contains various complex scene change types (such as object addition/removal/state change, event description, environment change, etc.) that require models to imagine many different scenarios and reason about the changed scenes. We present a baseline model based on a vision-language Transformer (i.e., LXMERT) and ablation studies. Through human evaluation, we demonstrate a large human-model performance gap, suggesting room for promising future work on this challenging counterfactual, scene imagination task. Our code and dataset are publicly available at: https://github.com/hyounghk/CoSIm
DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers
Feb 08, 2022

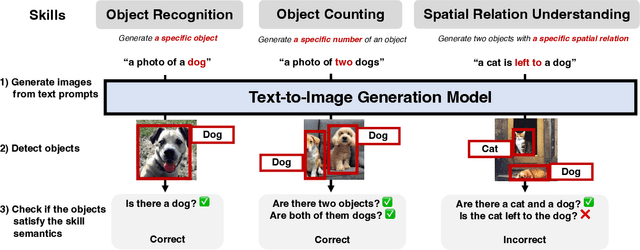
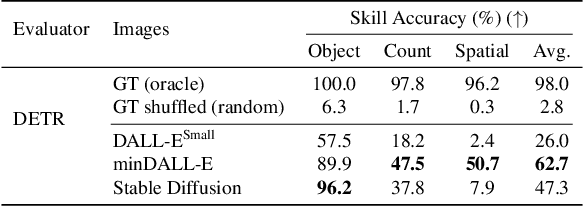
Generating images from textual descriptions has gained a lot of attention. Recently, DALL-E, a multimodal transformer language model, and its variants have shown high-quality text-to-image generation capabilities with a simple architecture and training objective, powered by large-scale training data and computation. However, despite the interesting image generation results, there has not been a detailed analysis on how to evaluate such models. In this work, we investigate the reasoning capabilities and social biases of such text-to-image generative transformers in detail. First, we measure four visual reasoning skills: object recognition, object counting, color recognition, and spatial relation understanding. For this, we propose PaintSkills, a diagnostic dataset and evaluation toolkit that measures these four visual reasoning skills. Second, we measure the text alignment and quality of the generated images based on pretrained image captioning, image-text retrieval, and image classification models. Third, we assess social biases in the models. For this, we suggest evaluation of gender and racial biases of text-to-image generation models based on a pretrained image-text retrieval model and human evaluation. In our experiments, we show that recent text-to-image models perform better in recognizing and counting objects than recognizing colors and understanding spatial relations, while there exists a large gap between model performances and oracle accuracy on all skills. Next, we demonstrate that recent text-to-image models learn specific gender/racial biases from web image-text pairs. We also show that our automatic evaluations of visual reasoning skills and gender bias are highly correlated with human judgments. We hope our work will help guide future progress in improving text-to-image models on visual reasoning skills and social biases. Code and data at: https://github.com/j-min/DallEval
FixMyPose: Pose Correctional Captioning and Retrieval
Apr 04, 2021
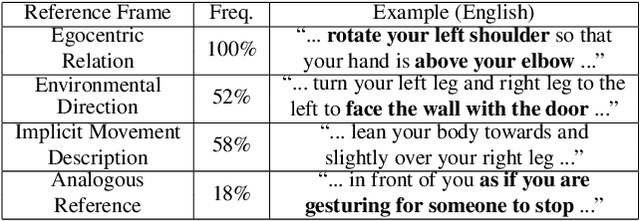


Interest in physical therapy and individual exercises such as yoga/dance has increased alongside the well-being trend. However, such exercises are hard to follow without expert guidance (which is impossible to scale for personalized feedback to every trainee remotely). Thus, automated pose correction systems are required more than ever, and we introduce a new captioning dataset named FixMyPose to address this need. We collect descriptions of correcting a "current" pose to look like a "target" pose (in both English and Hindi). The collected descriptions have interesting linguistic properties such as egocentric relations to environment objects, analogous references, etc., requiring an understanding of spatial relations and commonsense knowledge about postures. Further, to avoid ML biases, we maintain a balance across characters with diverse demographics, who perform a variety of movements in several interior environments (e.g., homes, offices). From our dataset, we introduce the pose-correctional-captioning task and its reverse target-pose-retrieval task. During the correctional-captioning task, models must generate descriptions of how to move from the current to target pose image, whereas in the retrieval task, models should select the correct target pose given the initial pose and correctional description. We present strong cross-attention baseline models (uni/multimodal, RL, multilingual) and also show that our baselines are competitive with other models when evaluated on other image-difference datasets. We also propose new task-specific metrics (object-match, body-part-match, direction-match) and conduct human evaluation for more reliable evaluation, and we demonstrate a large human-model performance gap suggesting room for promising future work. To verify the sim-to-real transfer of our FixMyPose dataset, we collect a set of real images and show promising performance on these images.
ArraMon: A Joint Navigation-Assembly Instruction Interpretation Task in Dynamic Environments
Nov 15, 2020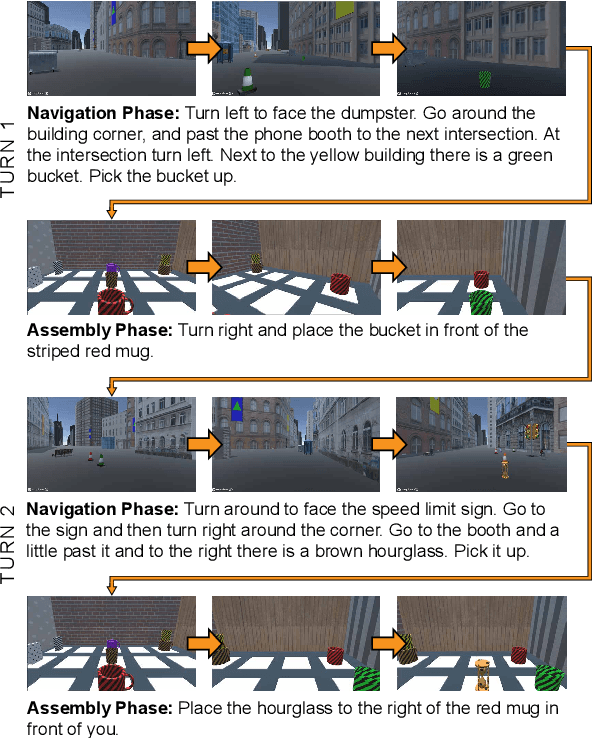
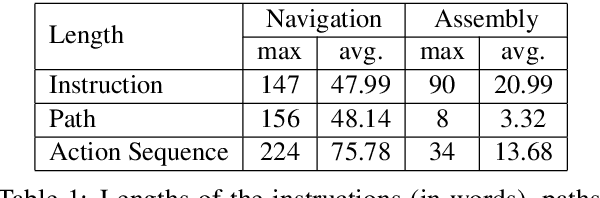
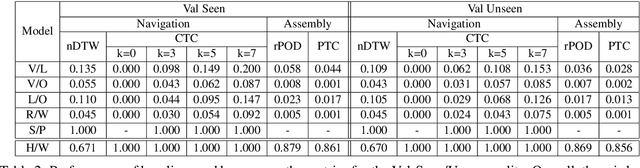
For embodied agents, navigation is an important ability but not an isolated goal. Agents are also expected to perform specific tasks after reaching the target location, such as picking up objects and assembling them into a particular arrangement. We combine Vision-and-Language Navigation, assembling of collected objects, and object referring expression comprehension, to create a novel joint navigation-and-assembly task, named ArraMon. During this task, the agent (similar to a PokeMON GO player) is asked to find and collect different target objects one-by-one by navigating based on natural language instructions in a complex, realistic outdoor environment, but then also ARRAnge the collected objects part-by-part in an egocentric grid-layout environment. To support this task, we implement a 3D dynamic environment simulator and collect a dataset (in English; and also extended to Hindi) with human-written navigation and assembling instructions, and the corresponding ground truth trajectories. We also filter the collected instructions via a verification stage, leading to a total of 7.7K task instances (30.8K instructions and paths). We present results for several baseline models (integrated and biased) and metrics (nDTW, CTC, rPOD, and PTC), and the large model-human performance gap demonstrates that our task is challenging and presents a wide scope for future work. Our dataset, simulator, and code are publicly available at: https://arramonunc.github.io