 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers
Paper and Code


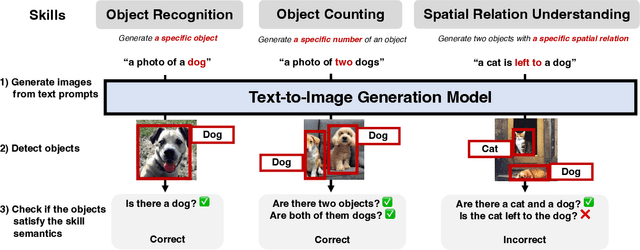
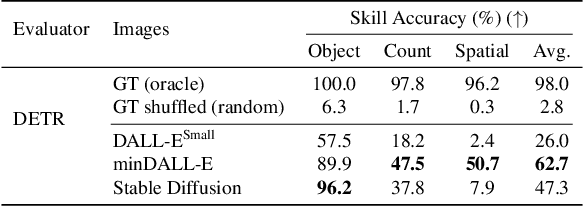
Generating images from textual descriptions has gained a lot of attention. Recently, DALL-E, a multimodal transformer language model, and its variants have shown high-quality text-to-image generation capabilities with a simple architecture and training objective, powered by large-scale training data and computation. However, despite the interesting image generation results, there has not been a detailed analysis on how to evaluate such models. In this work, we investigate the reasoning capabilities and social biases of such text-to-image generative transformers in detail. First, we measure four visual reasoning skills: object recognition, object counting, color recognition, and spatial relation understanding. For this, we propose PaintSkills, a diagnostic dataset and evaluation toolkit that measures these four visual reasoning skills. Second, we measure the text alignment and quality of the generated images based on pretrained image captioning, image-text retrieval, and image classification models. Third, we assess social biases in the models. For this, we suggest evaluation of gender and racial biases of text-to-image generation models based on a pretrained image-text retrieval model and human evaluation. In our experiments, we show that recent text-to-image models perform better in recognizing and counting objects than recognizing colors and understanding spatial relations, while there exists a large gap between model performances and oracle accuracy on all skills. Next, we demonstrate that recent text-to-image models learn specific gender/racial biases from web image-text pairs. We also show that our automatic evaluations of visual reasoning skills and gender bias are highly correlated with human judgments. We hope our work will help guide future progress in improving text-to-image models on visual reasoning skills and social biases. Code and data at: https://github.com/j-min/DallEval