 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixMyPose: Pose Correctional Captioning and Retrieval
Apr 04, 2021
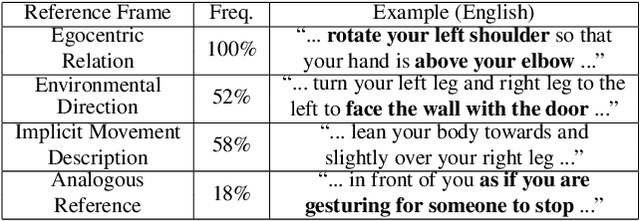


Interest in physical therapy and individual exercises such as yoga/dance has increased alongside the well-being trend. However, such exercises are hard to follow without expert guidance (which is impossible to scale for personalized feedback to every trainee remotely). Thus, automated pose correction systems are required more than ever, and we introduce a new captioning dataset named FixMyPose to address this need. We collect descriptions of correcting a "current" pose to look like a "target" pose (in both English and Hindi). The collected descriptions have interesting linguistic properties such as egocentric relations to environment objects, analogous references, etc., requiring an understanding of spatial relations and commonsense knowledge about postures. Further, to avoid ML biases, we maintain a balance across characters with diverse demographics, who perform a variety of movements in several interior environments (e.g., homes, offices). From our dataset, we introduce the pose-correctional-captioning task and its reverse target-pose-retrieval task. During the correctional-captioning task, models must generate descriptions of how to move from the current to target pose image, whereas in the retrieval task, models should select the correct target pose given the initial pose and correctional description. We present strong cross-attention baseline models (uni/multimodal, RL, multilingual) and also show that our baselines are competitive with other models when evaluated on other image-difference datasets. We also propose new task-specific metrics (object-match, body-part-match, direction-match) and conduct human evaluation for more reliable evaluation, and we demonstrate a large human-model performance gap suggesting room for promising future work. To verify the sim-to-real transfer of our FixMyPose dataset, we collect a set of real images and show promising performance on these images.
ArraMon: A Joint Navigation-Assembly Instruction Interpretation Task in Dynamic Environments
Nov 15, 2020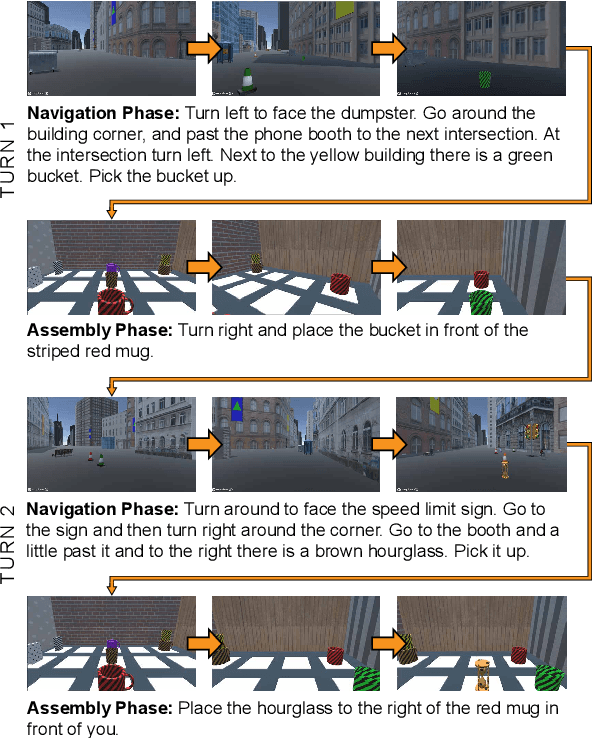
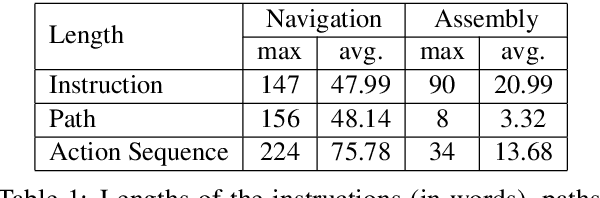
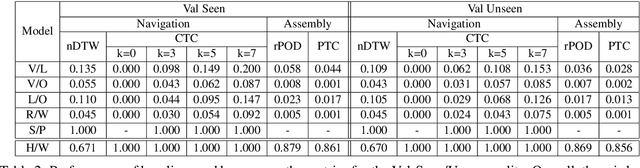
For embodied agents, navigation is an important ability but not an isolated goal. Agents are also expected to perform specific tasks after reaching the target location, such as picking up objects and assembling them into a particular arrangement. We combine Vision-and-Language Navigation, assembling of collected objects, and object referring expression comprehension, to create a novel joint navigation-and-assembly task, named ArraMon. During this task, the agent (similar to a PokeMON GO player) is asked to find and collect different target objects one-by-one by navigating based on natural language instructions in a complex, realistic outdoor environment, but then also ARRAnge the collected objects part-by-part in an egocentric grid-layout environment. To support this task, we implement a 3D dynamic environment simulator and collect a dataset (in English; and also extended to Hindi) with human-written navigation and assembling instructions, and the corresponding ground truth trajectories. We also filter the collected instructions via a verification stage, leading to a total of 7.7K task instances (30.8K instructions and paths). We present results for several baseline models (integrated and biased) and metrics (nDTW, CTC, rPOD, and PTC), and the large model-human performance gap demonstrates that our task is challenging and presents a wide scope for future work. Our dataset, simulator, and code are publicly available at: https://arramonunc.github.io