 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironment-agnostic Multitask Learning for Natural Language Grounded Navigation
Paper and Code
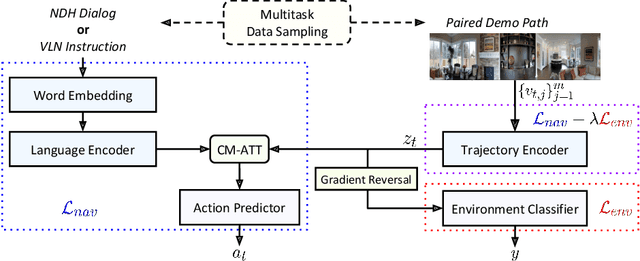
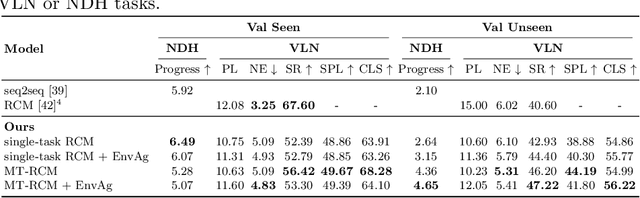
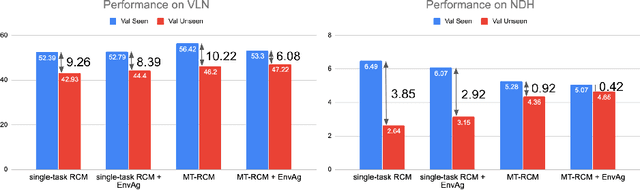
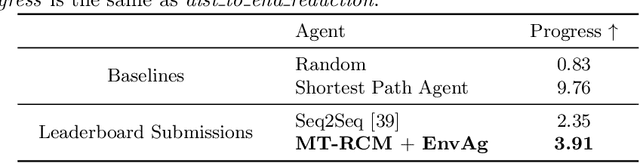
Recent research efforts enable study for natural language grounded navigation in photo-realistic environments, e.g., following natural language instructions or dialog. However, existing methods tend to overfit training data in seen environments and fail to generalize well in previously unseen environments. In order to close the gap between seen and unseen environments, we aim at learning a generalized navigation model from two novel perspectives: (1) we introduce a multitask navigation model that can be seamlessly trained on both Vision-Language Navigation (VLN) and Navigation from Dialog History (NDH) tasks, which benefits from richer natural language guidance and effectively transfers knowledge across tasks; (2) we propose to learn environment-agnostic representations for the navigation policy that are invariant among the environments seen during training, thus generalizing better on unseen environments. Extensive experiments show that training with environment-agnostic multitask learning objective significantly reduces the performance gap between seen and unseen environments and the navigation agent so trained outperforms the baselines on unseen environments by 16% (relative measure on success rate) on VLN and 120% (goal progress) on NDH. Our submission to the CVDN leaderboard establishes a new state-of-the-art for the NDH task outperforming the existing best model by more than 66% (goal progress) on the holdout test set. The code for training the navigation model using environment-agnostic multitask learning is available at https://github.com/google-research/valan.